I didn’t start paying attention to Walrus because of storage. I noticed it because of churn — and because $WAL wasn’t behaving the way most infrastructure tokens do when activity picks up. Even with $WAL trading around the mid-$0.1 range and steady daily volume in the tens of millions, nothing about the protocol’s posture felt reactive.
Most decentralized systems talk about permanence, but when you look underneath, they quietly assume stability. Nodes stay online. Committees don’t change too often. Data moves rarely. Walrus doesn’t make those assumptions, and that difference shows up everywhere in its design.
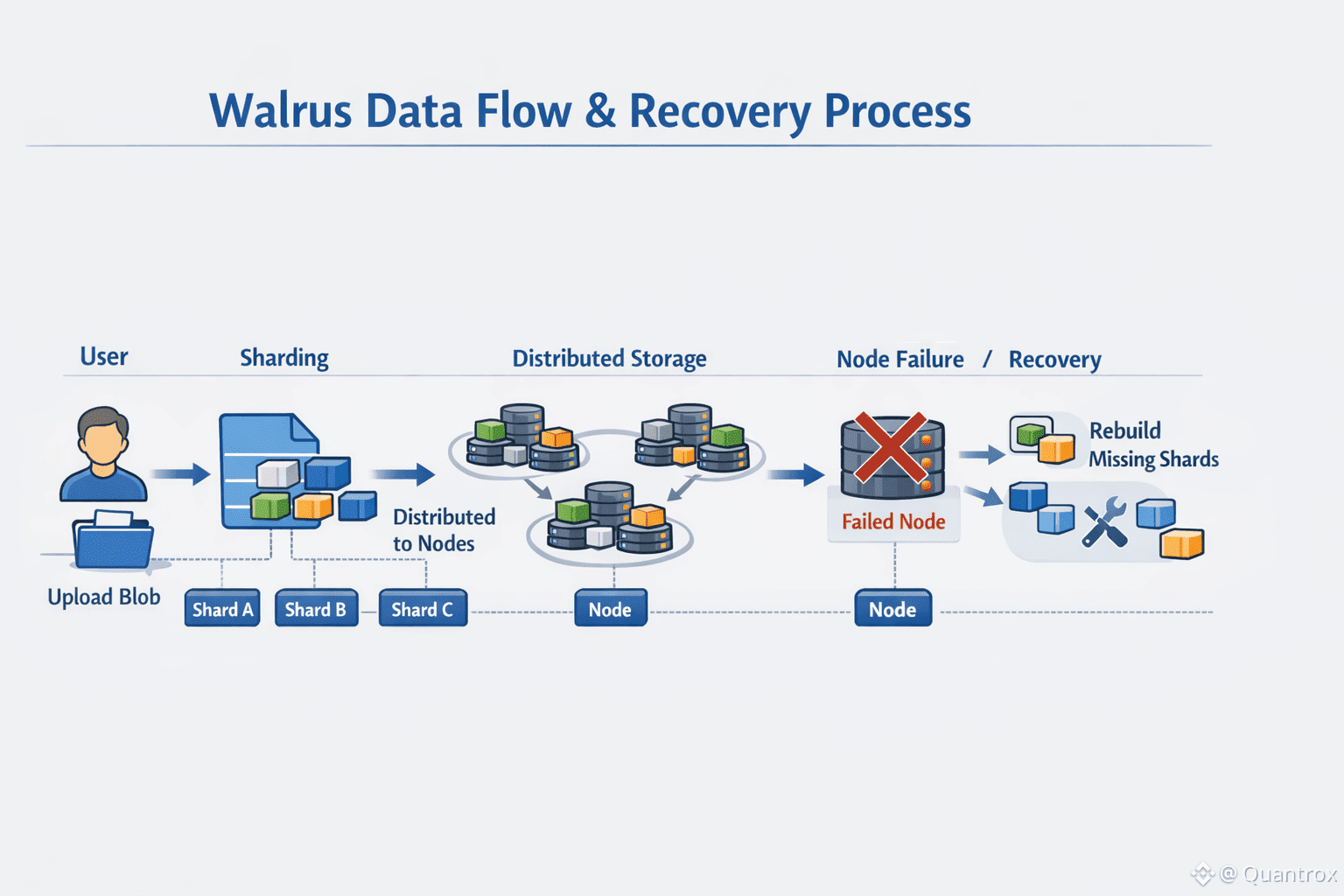
What the user sees is simple enough. You upload a blob to Walrus. It’s available. Applications retrieve it without worrying where it lives. That’s the surface layer. Underneath, Walrus is constantly preparing for things to go wrong. Nodes leave. Stake shifts. Epochs end. New operators appear. The system treats all of that as normal background noise rather than exceptional events.
Walrus runs on epochs that last roughly two weeks. At each epoch boundary, the storage committee can change. Shards get reassigned. If you store data on Walrus, it still needs to be available while all of that is happening. That constraint explains almost every design choice that follows.
Instead of full replication, Walrus uses erasure coding. That part isn’t unusual on its own. What matters is how it’s applied. Data isn’t just split and scattered once. It’s structured in a way that anticipates recovery. When a node disappears, the Walrus network doesn’t panic or rebuild entire files. It recovers only what’s missing, pulling small pieces from many places. The bandwidth used to recover a shard stays close to the shard’s size, not the file’s size. That difference compounds when you’re managing hundreds of nodes and thousands of shards.
At the time of writing, Walrus distributes around 1,000 shards across a little over 100 storage nodes. That ratio matters. It tells you the Walrus protocol isn’t trying to minimize coordination. It’s embracing it, but in a controlled way. More nodes means more places to recover from, which makes churn cheaper rather than more expensive.
This approach changes incentives too. Storage providers on Walrus aren’t racing to host specific files. They’re maintaining capacity and correctness over time. Rewards and penalties tied to $WAL are calculated at the epoch level, based on real behavior. That encourages steady operation rather than opportunistic behavior.
That delay feels restrictive at first. When I first looked at Walrus, I assumed it was a UX flaw. It’s not. It’s a stability mechanism. Walrus is optimizing for a system that doesn’t flinch every time incentives or token activity shift slightly.
There are risks here. Coordination overhead is real. Recovery logic is complex. The Walrus protocol assumes enough honest nodes remain online during transitions. If that assumption breaks, things get messy fast. Walrus isn’t pretending those risks don’t exist.
What this reveals is a broader pattern. Infrastructure is moving away from pretending the world is stable. Walrus feels built for environments where instability is the default.
The quiet insight is this: Walrus doesn’t promise that nothing will break. It promises that when things do, the system already knows how to keep going.

