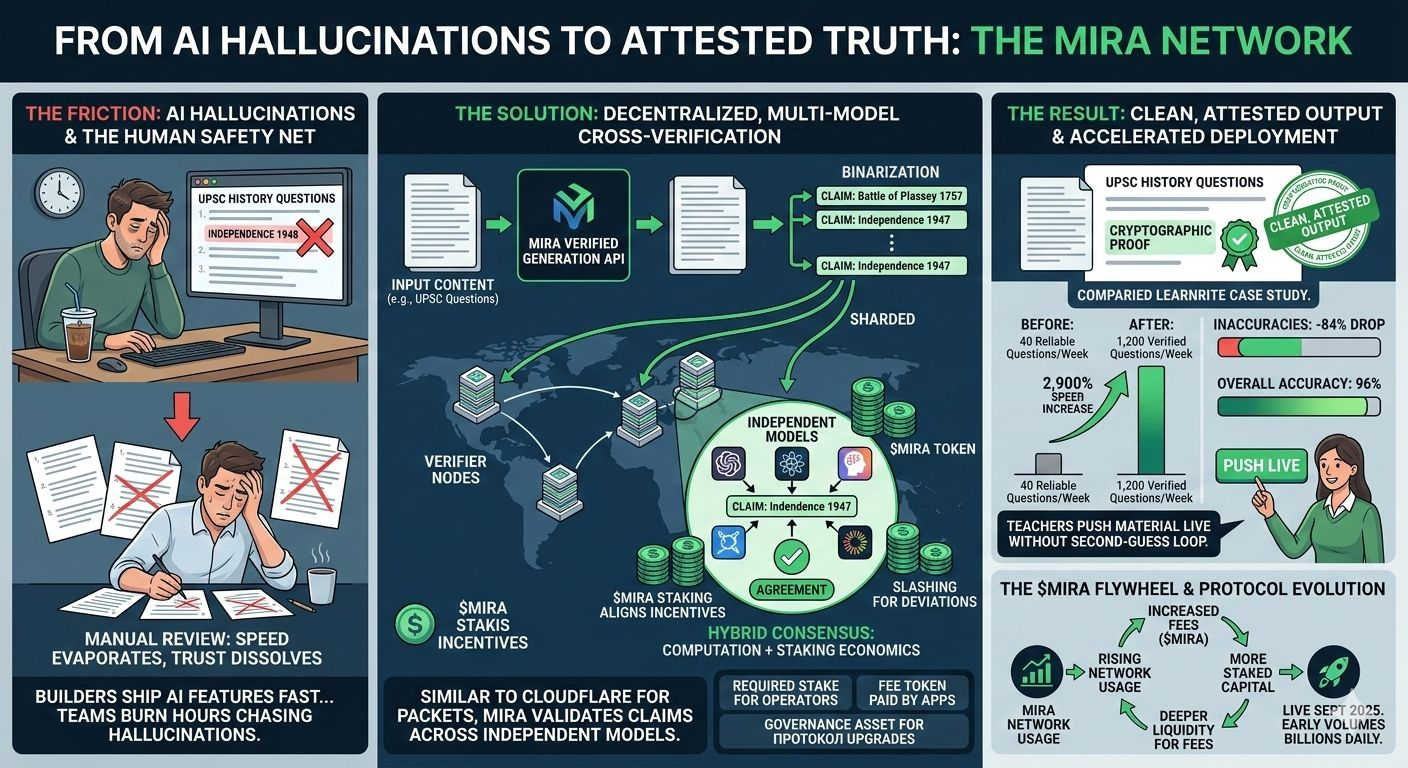
I was sitting at my desk two weeks ago with cold coffee, clicking “generate 50 UPSC-style history questions” on an EdTech tool I use for weekend prep. It returned the batch in 14 seconds. Question 12 claimed India gained independence in 1948. I knew it was 1947, but only because I had the date burned in from years of mocks. The next 25 minutes disappeared into manual fact-checking, crossing out and rewriting half the set. The speed felt great until the trust evaporated.
That small slip is the friction nobody puts in the pitch decks. Builders ship AI features fast, then watch teams burn hours chasing hallucinations in education packs, financial summaries, or compliance docs. The hidden cost isn’t compute—it’s the constant human safety net that keeps real deployment slow and expensive. Everyone quietly accepts it because the alternative is shipping garbage.
That’s when @Mira - Trust Layer of AI became relevant. It works like a decentralized fact-check layer, similar to how Cloudflare inspects and validates every packet across global edge nodes before it reaches your browser. Instead of trusting one model’s output, Mira routes AI content through a network of independent models that cross-verify before anything ships.
The process is simple in practice. You feed generated content into Mira’s Verified Generation API. The system first binarizes it—turns flowing paragraphs into discrete, testable claims like “The Battle of Plassey occurred in 1757” or “X policy leads to Y outcome.” Each claim gets sharded out to multiple verifier nodes running different models. No single node sees the whole document. They run inference, vote via hybrid consensus that mixes actual computation with staking economics, and if agreement holds you receive a cryptographic proof. The end user sees clean, attested output.
Learnrite’s numbers show what changes on the ground. Before integration they squeezed out about 40 reliable exam questions per week after heavy manual review. After Mira they hit 1,200 verified questions weekly—a 2,900% speed increase—while inaccuracies dropped 84% and overall accuracy reached 96%. Teachers now push material live without the usual second-guess loop.
The incentives matter because verification stops being charity. Node operators must stake $MIRA to run verifier models and earn rewards only when their work aligns with honest consensus. Deviations trigger slashing. This matters because it turns security into aligned economics instead of hoping models behave. That’s where $MIRA enters: it is the required stake for participation, the fee token paid by apps for each verification batch, and the governance asset for protocol upgrades. Over time this creates a flywheel where rising usage pulls in more staked capital and deeper liquidity for fees.
That said, the network’s strength still hinges on having enough diverse, high-quality verifier models active at once. If participation clusters or models share too many training overlaps, consensus could miss edge-case biases. Early volumes already clear billions of tokens daily across partners, but sustained enterprise scale will reveal whether the operator base grows fast enough.
I’ve watched the Learnrite rollout and daily on-chain metrics since mainnet went live last September. The friction reduction feels concrete, not theoretical. I hold a small position in $MIRA . The mechanism is pragmatic and the early signals line up.