The core problem with AI is not that it makes mistakes. The real problem is that it can be wrong while sounding confident. And when an output feeds into an automated system, an agent pipeline, or an on-chain state change, a wrong answer stops being an error — it becomes a cost.
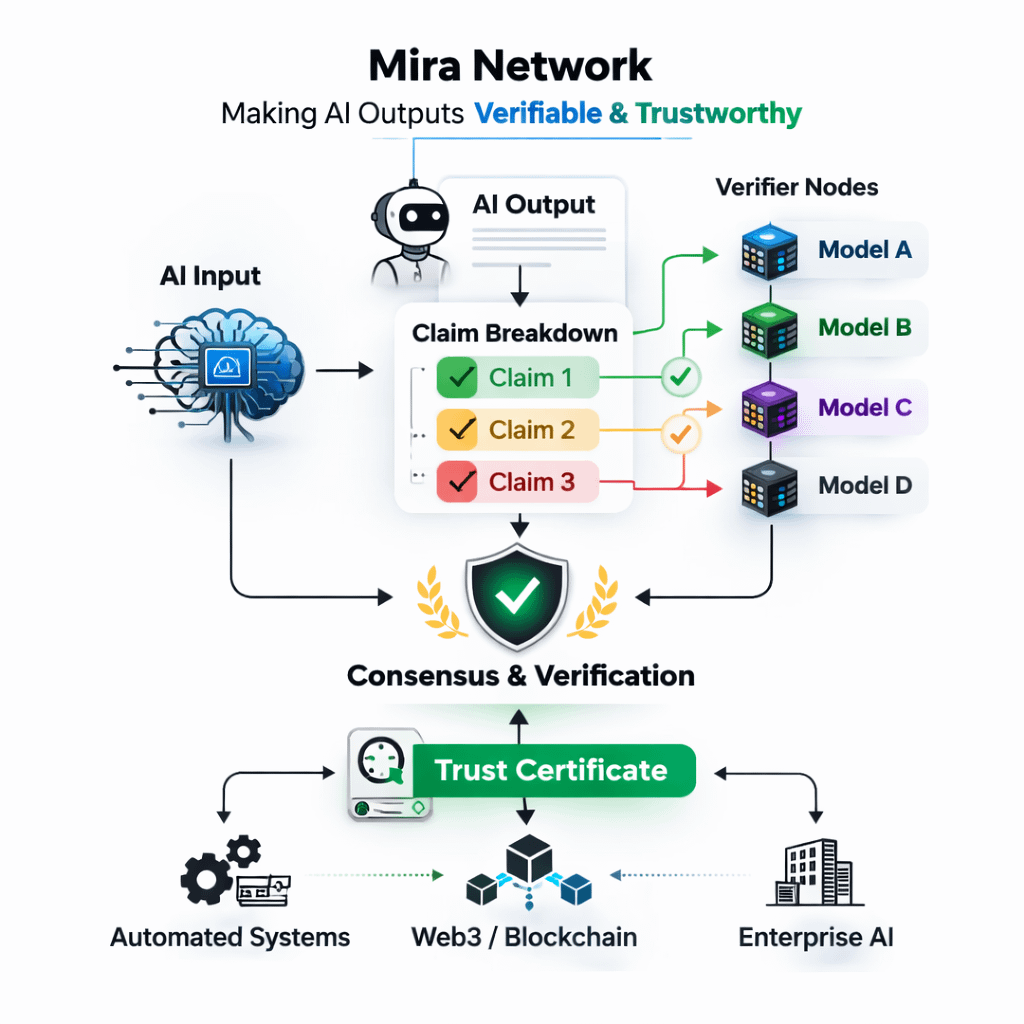
Mira Network focuses exactly on this issue. It does not claim to make AI perfect. Instead, it aims to make AI outputs auditable. The approach is simple but delicate: break every answer into small, verifiable claims, then pay independent verifiers to confirm or reject those claims.
But the real product is not the blockchain layer — it is the claim definition layer.
If claims are too broad, verifiers interpret them differently and consensus becomes noisy. If claims are too granular, costs increase and latency slows everything down. So the real question is not how many verifiers exist, but how a claim is defined, how context is attached to it, and whether that transformation step becomes a hidden central point of control.
Once claims are created, they are sent to multiple nodes running different models. Many people reduce this to simple voting. But consensus only works if there is real diversity. If every verifier runs the same model family with the same blind spots, the network can agree — and still be wrong.
True operational diversity means:
Different model stacks
Different retrieval pipelines
Different fine-tuning approaches
Different data access patterns
Without diversity, consensus is just an illusion.
The incentive layer is equally sensitive. Staking and penalties are meant to prevent a lazy verifier economy. If guessing quickly still gets rewarded, guessing becomes the norm. If penalties are too harsh, only a small group of operators remains, and the network quietly centralizes.
The network’s health lives in a narrow zone where: Honest verification is consistently profitable.
Cheating is consistently loss-making.
After stability comes another risk: collusion. Once a network appears stable, operators may copy expected answers instead of doing real work because it is cheaper. Random assignment and duplication help reduce coordination and detect patterns, but they increase costs. More duplication means more compute burned per request, which leads to higher fees or thinner margins — and both directly affect scalability.
Privacy introduces another constraint. The highest-value verification tasks are often sensitive. A network that leaks inputs cannot participate in serious workflows. Fragmenting content and keeping responses private until consensus is reached is directionally correct. However, this creates tension with auditability. The more information you hide, the harder it becomes to explain why a certificate should be trusted during a dispute. And dispute resolution is not a minor detail — it determines whether certificates can be integrated into accountable real-world systems.
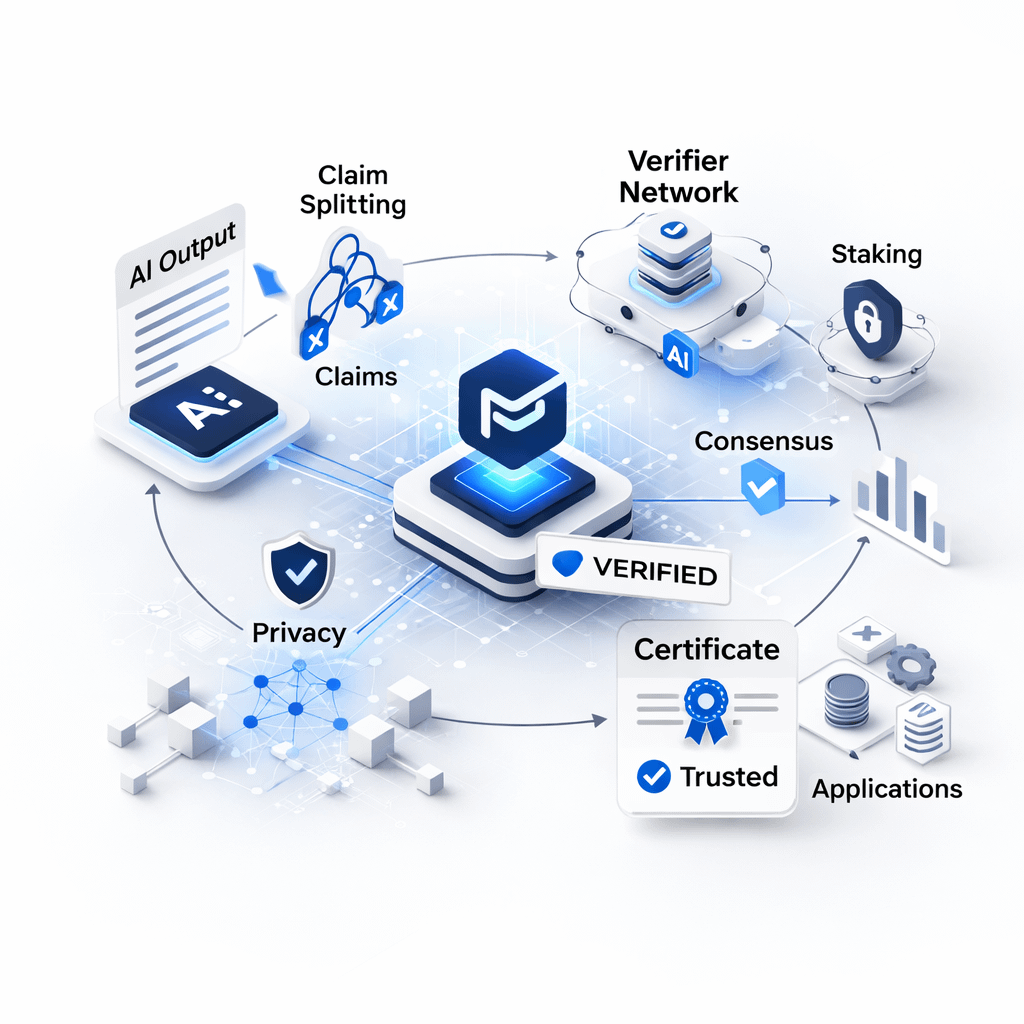
Ultimately, Mira does not sell answers. It sells certificates.
Certificates that:
An agent pipeline can require before execution
A retrieval system can use to filter failed claims
An on-chain application can demand before changing state
If certificates become standardized, cheap to verify, and easy to integrate, Mira becomes infrastructure. If integrations remain custom and fragile, it behaves more like a service layer.
If you want to evaluate Mira properly, the key questions are measurable, not narrative-driven:
What is the cost of verification per claim at different confidence levels
How long does consensus take under heavy load
How often do verifiers disagree in high-impact domains
Are penalties catching dishonest behavior or just punishing disagreement
And most importantly: how decentralized is the claim transformation step today



#MarketRebound #BitcoinGoogleSearchesSurge #TrumpStateoftheUnion #TrumpNewTariffs