A few months into running $ROBO tasks at Fabric Foundation, we noticed something odd in the verification logs. Nothing was technically failing. But verification checks were starting to disagree with themselves. The same task would pass verification at 12:03, fail at 12:05, and pass again at 12:08.
No code changes. No policy updates. Just different answers depending on when the check happened.
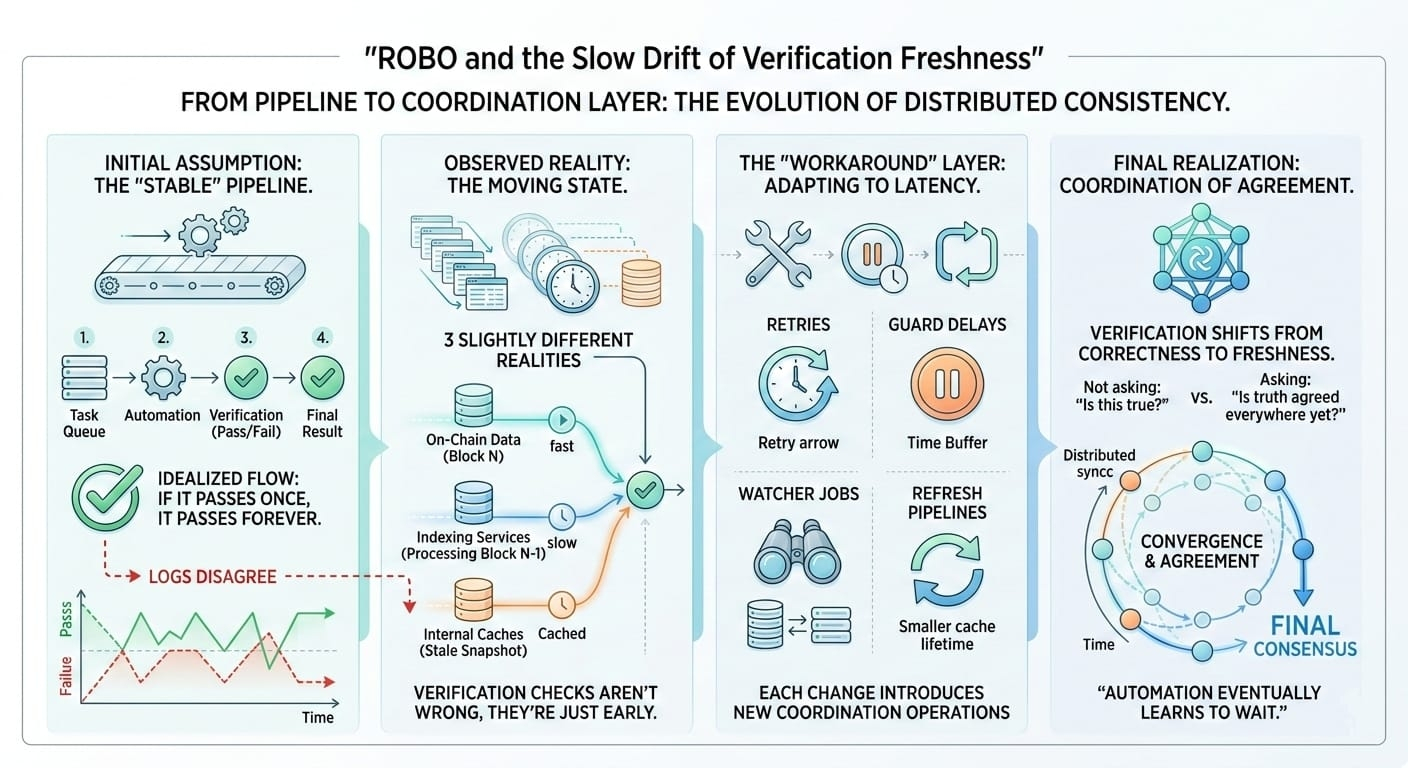
The system wasn’t designed to behave like that. The expected flow was simple: a task enters the queue, automation processes it, verification confirms the state, the result is recorded, and the task exits. Verification was supposed to be stable. If verification passed once, it should pass every time. That was the assumption.
Production had a different opinion.
What we slowly realized was that verification wasn’t checking a single state. It was checking a moving one. Some of the data lived on-chain. Some came from indexing services. Some came from internal state snapshots. Each of those sources moved at slightly different speeds. Sometimes the difference was seconds. Sometimes it was minutes.
So the same verification request could observe three slightly different realities. The chain said one thing. The indexer hadn’t caught up yet. A cache still held the previous block.
Verification wasn’t wrong. It was just early.
At first the system treated these mismatches as failures. That created a lot of noise. Tasks that were actually correct kept bouncing back into the queue. Operators assumed something was broken, but most of the time the data simply hadn’t finished settling.
The first fix was retries. If verification failed, the task would wait and try again. Thirty seconds later, the result usually matched. Retries looked like a simple safety net, but they quietly changed the behavior of the system.
Then came guard delays. Instead of verifying immediately, some tasks waited before running checks. Just enough time for indexers to update. That reduced unnecessary retries, but it introduced verification windows.
Later we added watcher jobs. Small background processes that periodically re-verified tasks that looked suspicious. Sometimes the original verification had happened during an unlucky timing window, and watcher jobs cleaned those up.
Then refresh pipelines appeared. Index snapshots were refreshed more frequently to reduce stale reads. Caches got shorter lifetimes. Some services started forcing fresh queries whenever verification was involved.
Each of these changes made sense on its own. But together they created something else: a coordination layer.
Not in the protocol. In the operations.
At that point verification wasn’t really about correctness anymore. It was about freshness. The system wasn’t asking “Is this true?” It was asking “Has the rest of the system caught up enough for this to be true everywhere?”
That’s a different question.
What ROBO actually coordinates isn’t just tasks. It coordinates when different parts of the system finally agree about reality. Sometimes that agreement takes longer than expected. Retries, delays, watchers, and refresh pipelines mostly exist to give the system time to converge.
After operating it for a while, the architecture diagram starts to feel slightly dishonest. It shows a clean pipeline, but the real system is doing something quieter. It keeps asking the same question again and again. Not because the logic is wrong, but because the truth inside distributed systems tends to arrive in stages.
And automation eventually learns to wait.#ROBO @Fabric Foundation $ROBO