I didn’t approach OpenLedger like a trader hunting for the next hype cycle.
I approached it like a skeptic.
And honestly, that skepticism felt justified.
The AI space has become crowded with projects repeating the same polished vocabulary — decentralization, autonomy, intelligence — without ever explaining what any of it actually means at the infrastructure level. A lot of teams talk about rebuilding the future, but very few seem interested in dealing with the uncomfortable questions hiding underneath the surface.
Who owns the data once it enters these systems?
Who benefits financially when models generate value from millions of invisible contributions?
And perhaps most importantly, how do you create accountability inside systems that are becoming harder to understand even for the people building them?
Those questions stayed in the back of my mind while researching OpenLedger. But the more time I spent examining the project, the more I realized it wasn’t trying to position itself as another flashy AI application designed to capture attention for a few months. Its focus felt deeper than that. Quieter, too.
OpenLedger seems less interested in building a consumer product and more interested in fixing the economic structure underneath artificial intelligence itself.
That distinction changes the entire way the project reads.
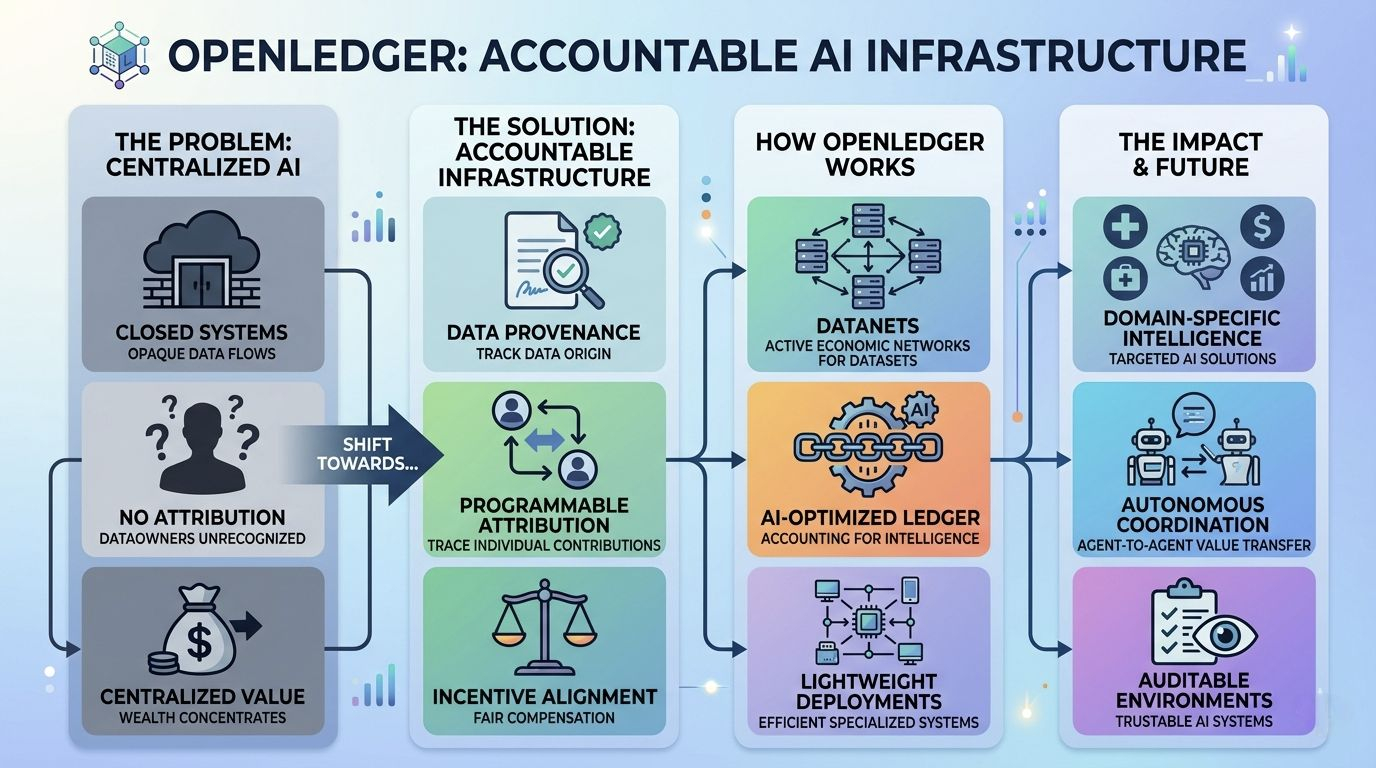
Most modern AI systems operate inside highly centralized environments. Data is collected from everywhere, absorbed into closed infrastructures, refined through opaque training pipelines, and eventually transformed into commercial intelligence. Meanwhile, the individuals contributing to that process — whether intentionally or passively — remain disconnected from the value being created.
That imbalance has slowly become one of the defining problems of the AI era.
The infrastructure powering modern models depends heavily on participation from distributed networks of people, developers, researchers, and datasets. Yet the ownership structure remains concentrated in the hands of the entities operating the systems themselves. Contributors lose visibility, developers lose attribution, and economic rewards become increasingly centralized.
OpenLedger appears to recognize that this isn’t just a technical issue. It’s an accounting issue.
At the center of the project is the idea that attribution should not exist as a vague promise or optional feature. It should exist as infrastructure. That sounds simple at first, but it has major implications. Once contributions become traceable, compensation becomes programmable. Once provenance becomes verifiable, data starts behaving less like disposable raw material and more like an accountable economic asset.
That philosophy shapes almost every part of the network’s design.
Instead of building a generic blockchain and attaching AI functionality onto it afterward, OpenLedger structures the chain itself around AI participation. Data contribution, model refinement, inference activity, and autonomous interactions are all intended to exist within the same operational environment. The blockchain becomes more than a settlement layer. It starts functioning like an accounting system for intelligence itself.
You can see this clearly in the project’s concept of Datanets.
Rather than treating datasets as static repositories sitting quietly in storage, OpenLedger treats them as active economic networks. Contributors, validators, and developers can all interact within the same system while preserving transparent attribution relationships between them. In practical terms, this means specialized datasets used for healthcare research, financial modeling, industrial automation, or language systems can maintain a visible history of contribution over time.
That may sound highly technical on paper, but the underlying idea is surprisingly practical.
The future of AI probably won’t depend entirely on giant generalized models trained on endless volumes of internet content. More likely, it will depend on highly specialized intelligence systems trained on narrow, high-quality datasets. And high-quality datasets do not emerge sustainably unless the incentive structure around them makes sense.
OpenLedger seems built around that reality.
Its infrastructure appears less focused on creating one dominant intelligence layer and more focused on enabling thousands of smaller domain-specific systems that can sustain themselves economically without relying entirely on centralized ownership.
That’s also why some of the project’s technical decisions feel more grounded than performative. Efficient deployment systems, transparent inference accounting, and traceable data flows are not abstract ideals. They are operational requirements if decentralized AI coordination is ever going to work at scale.
Even the project’s approach to lightweight model deployment reflects a fairly realistic understanding of where the industry may be heading. The future likely won’t belong exclusively to a handful of massive centralized models. It may involve large numbers of smaller specialized systems operating across different industries simultaneously.
That aligns much more closely with how real organizations function.
Most companies are not looking for abstract artificial general intelligence. They want narrow expertise, controlled environments, transparent data boundaries, and systems they can actually audit. OpenLedger’s architecture feels designed with those realities in mind.
The same logic becomes even more relevant when looking at the project’s recent direction around autonomous AI agents.
Once software agents begin interacting independently — accessing datasets, executing tasks, requesting services, and generating outputs continuously — accountability becomes much harder to maintain through traditional systems. At that point, infrastructure needs reliable ways to track origin, measure contribution, and coordinate value distribution without depending entirely on centralized intermediaries.
OpenLedger increasingly seems to position these agents as native participants within the network itself rather than external applications running on top of it. That changes the role of the ledger entirely. It stops being a system that merely records transactions and starts becoming a coordination layer between datasets, models, autonomous agents, and human contributors operating together.
Of course, none of this guarantees success.
Building decentralized AI infrastructure remains computationally expensive, operationally difficult, and economically fragile. Attribution systems become harder to maintain as models evolve in complexity. Incentive structures around data quality are notoriously difficult to balance long term. And convincing enterprises to adopt transparent contribution systems may prove challenging in industries built around informational control.
But what makes OpenLedger interesting is that it doesn’t pretend these problems don’t exist.
The project doesn’t frame decentralization as some magical solution capable of fixing every structural issue overnight. Instead, its architecture feels like a serious attempt to make transparency, attribution, and economic coordination enforceable at the infrastructure level rather than dependent on institutional trust alone.
And after researching it carefully, that’s probably the part that stayed with me the most.
OpenLedger doesn’t feel like a project trying to manufacture excitement.
It feels like infrastructure being built for a future that is arriving faster than most systems are prepared for.