A few days ago, there was a night I won’t easily forget. I was moving funds on-chain, and at first everything felt completely normal. But gradually I started noticing something unusual the network didn’t feel as responsive as before. 🤔
One transaction stayed pending, then another. The wallet took longer to load, refreshes slowed down, and confirmations were arriving much later than usual.
At first, I thought it might be an issue on my side. But after a while, I realized it wasn’t just me. There was a subtle pressure building inside the entire system. Everything was still functioning, but that smooth flow I was used to was no longer there. It felt like a large machine still running, but with growing internal friction somewhere inside.
Moments like this always make me think about one thing.
We usually talk about blockchain or any network in terms of speed, TPS, and performance metrics. But real-world usage always reveals something different. The real test happens when thousands of users and transactions start hitting the system at the same time.
In calm conditions, everything looks fast.Under pressure, the truth slowly reveals itself.
I often compare infrastructure to the traffic system of a large city during different times of the day. Early morning, when the roads are empty, everything moves smoothly and the system feels perfect. But during rush hour, when thousands of vehicles move at once, you start noticing where the planning is weak, where intersections are poorly designed, and where a single signal can slow down the entire flow.
Infrastructure is exactly like that!
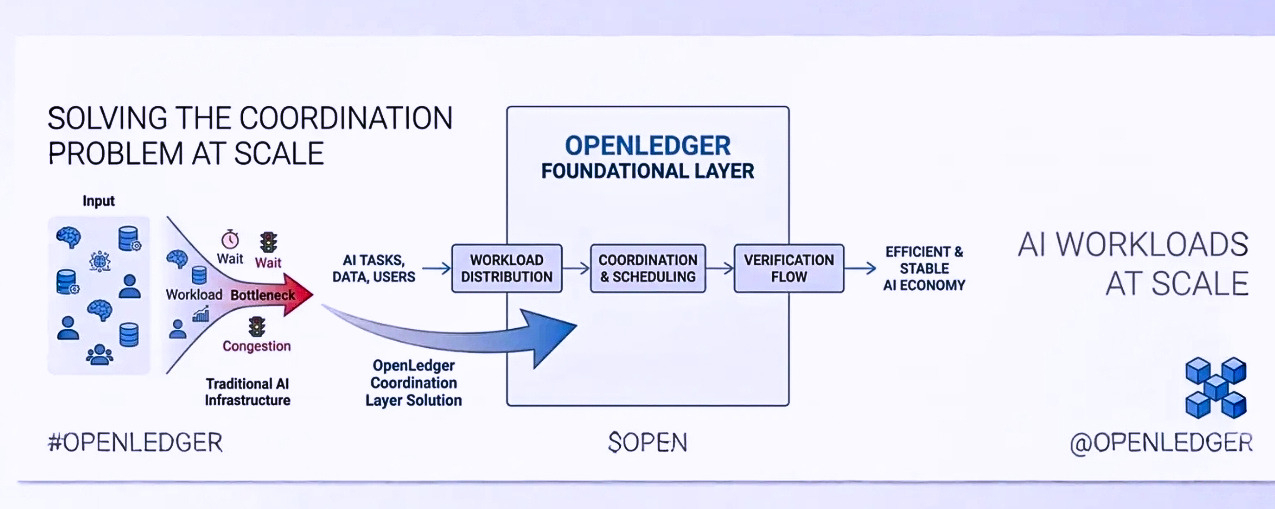
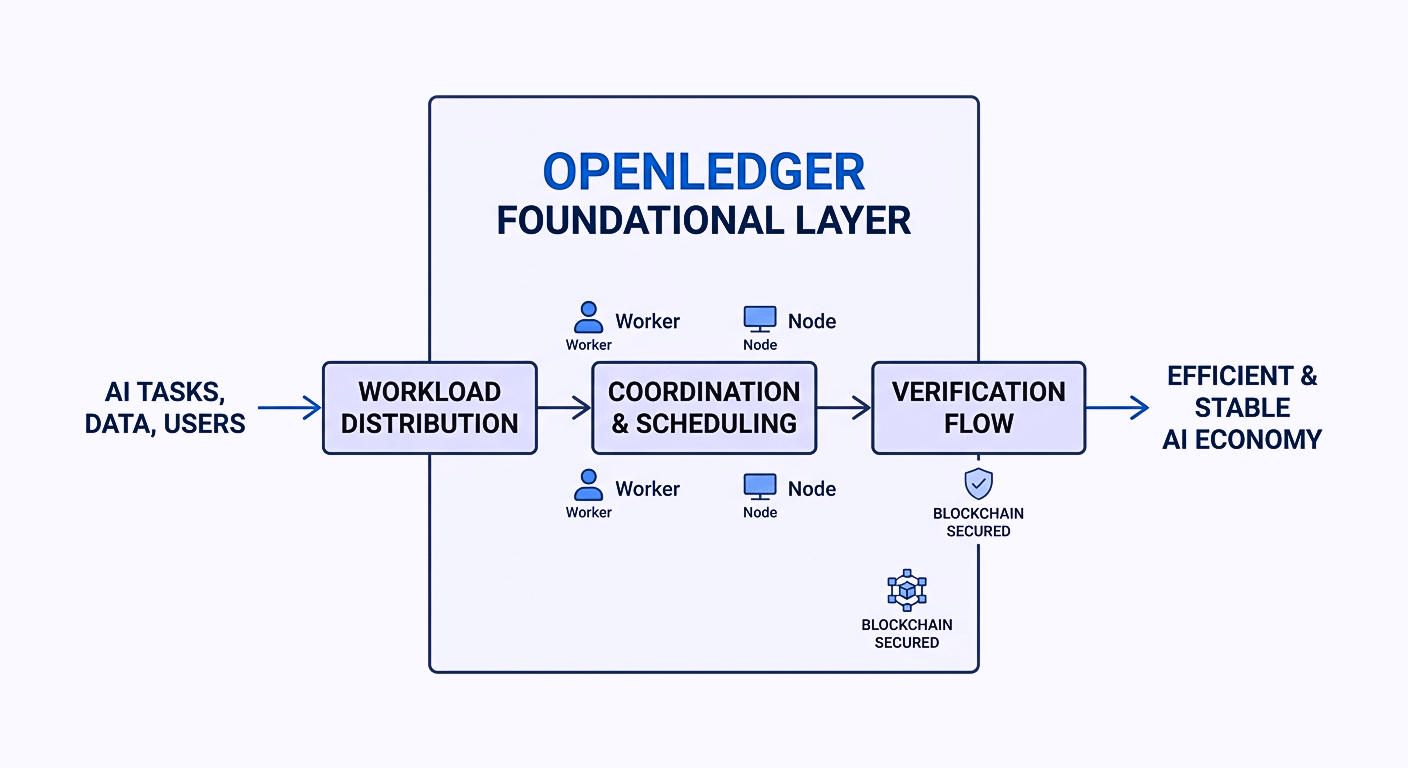
It’s not just about powerful hardware or high processing speed. The real challenge is how the system manages its internal work. Which task goes where, which processes run separately, and how congestion is prevented from spreading across the entire network this coordination is what truly matters.
As AI systems become more deeply integrated with blockchain infrastructure, this challenge becomes even more critical.
Because AI workloads never stop. Verification, computation, data handling, scheduling all of it runs in parallel continuously. If workloads are not properly distributed, even small delays can quickly turn into major bottlenecks, and the entire system can start struggling under pressure.
This is where @OpenLedger caught my attention.
What stood out to me was not any flashy performance claim, but rather the approach itself. It feels like the project is trying to design infrastructure not just as a “fast execution layer,” but as a coordination system.
Task separation, worker coordination, verification flow all of it seems structured in a way that prioritizes stability before scalability.
And to me, that feels more realistic.
Because most system failures don’t happen suddenly. They build up slowly. It starts with small delays, minor synchronization issues, slightly growing queues, these inefficiencies accumulate over time until they begin affecting the entire network.
At that point, it becomes clear that the real problem was never speed it was coordination.
In weak systems, congestion spreads quickly across everything.
In strong systems, pressure is absorbed, isolated, and managed without collapsing the entire structure.
This may not sound dramatic from the outside, but in reality, it is the most important difference.
Stable infrastructure is never loud. It doesn’t seek attention. But it’s what holds the entire ecosystem together when everything else becomes uncertain.
And over time, one thing becomes clearer to me,
The future AI economy and digital infrastructure won’t be defined by hype or raw speed.
They will be defined by systems that can quietly and consistently handle large-scale coordination, absorbing pressure without breaking the network.
In the end, the strongest systems are the ones you barely notice working because they simply keep everything running as it should. 😏
