I keep thinking about credit scores in a slightly uncomfortable way. Not because they are perfect, they are not, but because they turn messy behavior into something other systems can act on. A bank does not need to know every detail of a person’s life before deciding whether to extend credit. It looks at a structured record, imperfect and sometimes unfair, but reusable. That small idea keeps coming back when I look at OpenLedger and $OPEN. At first, I saw the project mostly through the usual AI-data lens: contributors provide data, models use it, rewards flow back. Clean enough. But the more I sit with it, the more I wonder if that framing is too flat.
Autonomous AI agents create a stranger problem than normal users. A human can build reputation socially. A company can file documents, sign contracts, maintain accounts, and accumulate a public operating history. But an AI agent that acts across networks, tools, wallets, APIs, and markets does not automatically carry a trustworthy identity from one place to another. It can complete tasks, but completion is not the same as credibility. It can interact often, but activity is not the same as reliability. This is where OpenLedger starts to look less like a simple contribution ledger and more like an early attempt at structured behavioral memory.
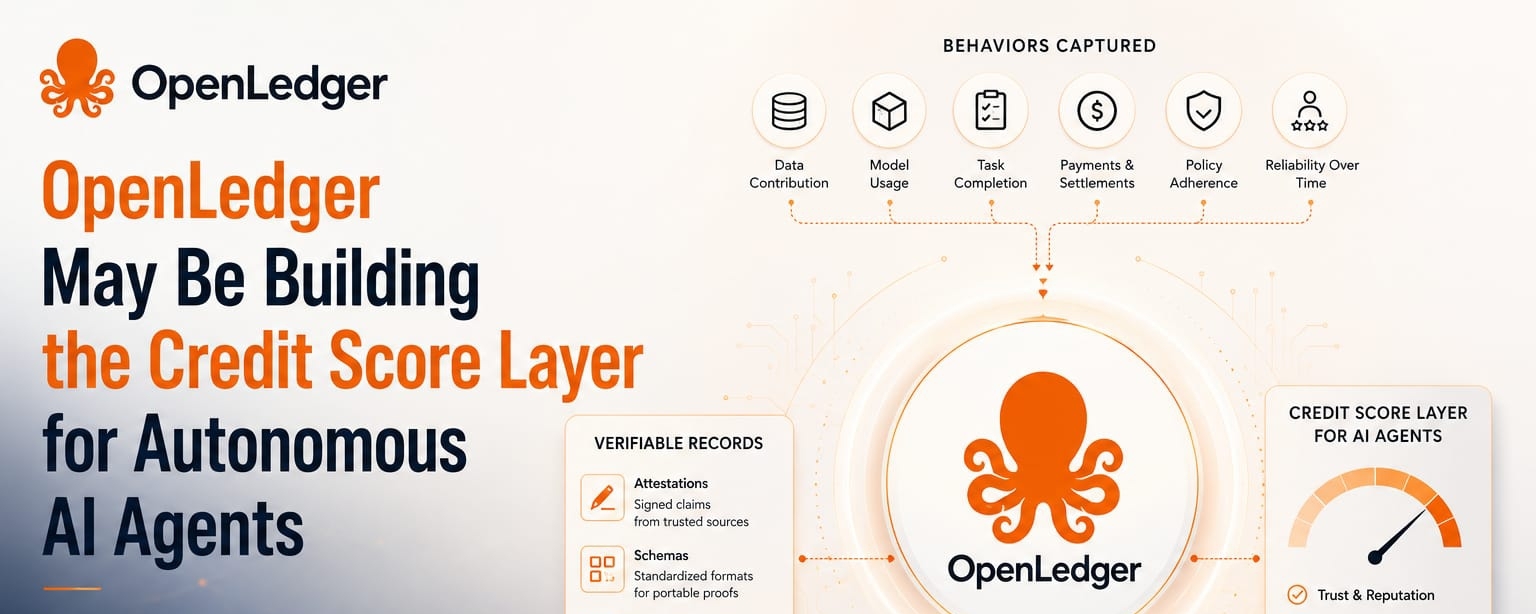
A credit score layer for AI agents would not mean copying the consumer credit system directly. That would be too crude. What matters is the function. A system needs to remember whether an agent has completed work honestly, used data correctly, respected permissions, paid contributors, avoided manipulation, and behaved consistently when incentives changed. In crypto terms, this might rely on attestations, which are just signed claims that something happened. A data source contributed this. A model used that. An agent completed a task under these rules. The point is not disclosure for its own sake. The point is reusable proof.
That distinction matters. A lot of crypto infrastructure still treats proof like a receipt. Something happened, therefore record it. But markets usually care more about what the record allows later. Eligibility, access, pricing, reputation, limits, routing. If OpenLedger can help turn AI participation into structured records, then $OPEN may sit near a more interesting layer than basic rewards. It may help decide which agents are treated as trusted participants and which ones remain anonymous activity with no accumulated weight.
I am cautious here, because the market often overprices anything that sounds like identity. We have seen this before. Wallet scores, soulbound tokens, reputation dashboards, contribution badges. Many looked useful until incentives faded and users stopped caring. The hard question is whether the behavior keeps repeating naturally. Do agents need this record because it reduces friction, unlocks work, lowers risk, or improves access? Or is it just another metric created because the system wants something measurable? That gap between usage and real demand is where most token narratives get exposed.
Still, AI agents make the question sharper. If agents become economic actors, they will need something between a wallet address and a legal entity. A wallet can hold assets, but it cannot explain trust. A legal entity can assume responsibility, but many AI workflows will move faster, smaller, and more modular than traditional business structures. So the missing layer may be operational credibility. Not identity as biography. Identity as accumulated behavior. That is a colder idea, but probably more useful.
OpenLedger’s possible role is interesting because attribution sits close to this credibility layer. If an agent uses data, pays for access, generates outputs, and creates downstream value, then the system needs to track not just who participated, but how dependable that participation became over time. Schemas could matter here. A schema is simply a standard format for describing records, so different systems can understand the same type of proof. Without schemas, reputation becomes messy storytelling. With schemas, it can become portable logic.
There is also a selective disclosure angle, though I would not overstate it. Selective disclosure means showing only the needed part of a record instead of exposing everything. An agent might prove it has a clean task history without revealing every client, dataset, or workflow. Zero-knowledge proofs could support that by proving a condition is true without revealing the underlying details. Again, the simple version is this: trust may need privacy, because full transparency can become its own risk.
For $OPEN, the deeper question is whether the token captures dependency or only activity. Activity can be farmed. Dependency is harder. If agents, developers, data providers, and applications repeatedly need OpenLedger’s records to make decisions, then the token’s relevance becomes tied to system memory. If not, it risks becoming another reward asset floating around a narrative that sounds stronger than the behavior underneath.
I do not think this is settled. Maybe OpenLedger remains mostly an attribution and data economy layer. Maybe the agent-credit-score framing is too early. But I keep coming back to the same market pattern: the valuable layer is often not the one that looks busiest. It is the one other systems quietly stop restarting from zero without.
