I still think about a friend who once spent weeks cleaning messy datasets for an AI project that later got a bit of attention. The model worked, people praised the output, and somehow his part quietly disappeared from the story. No mention, no share, nothing traceable. It didn’t feel malicious, just… normal. And that’s exactly the problem. The people closest to the raw work are often the easiest to forget.
That’s the thought I carried when I first came across OpenLedger. Not the usual “AI meets blockchain” pitch, but something more specific: what if contribution didn’t vanish so easily? What if data, models, even autonomous agents had a visible trail—and more importantly, a financial one?
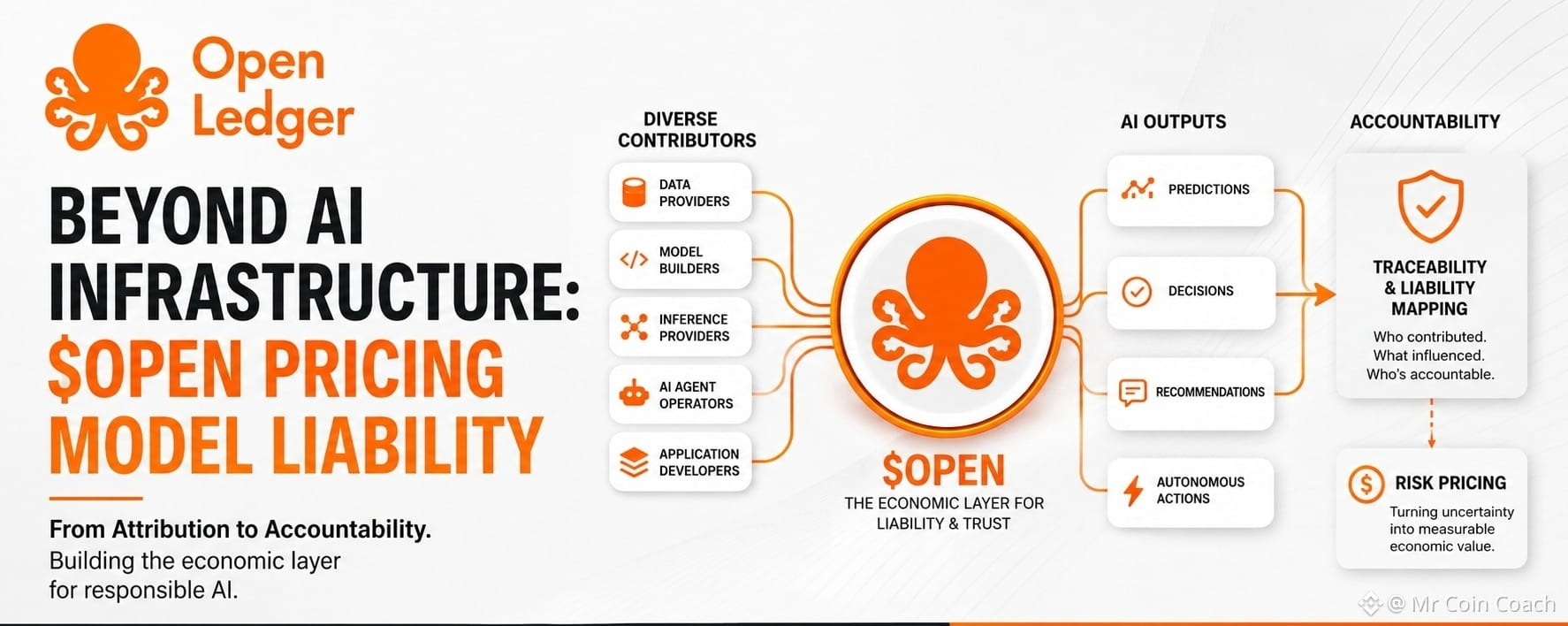
OpenLedger leans into that idea in a way that feels less theoretical than most. It tries to map the entire flow, from raw data to final output, and attach accountability along the way. Data gets structured into focused networks instead of just being dumped somewhere. Models aren’t treated like isolated creations; they carry some sense of where they came from. And agents, which are becoming more common by the day, aren’t just tools here—they’re part of the economic loop.
There’s something quietly compelling about that. If an AI system generates value, there’s at least an attempt to look backward and recognize what made that possible. Not in a vague “community effort” kind of way, but in something closer to measurable attribution. It’s the kind of idea that feels obvious once you hear it, but it hasn’t really been built into systems at this level before.
At the same time, it’s hard to ignore how messy this gets in reality. Data isn’t clean. It overlaps, evolves, gets reused in ways that blur ownership. Once multiple sources shape a model’s behavior, attribution stops being precise and starts becoming interpretive. OpenLedger seems aware of this, but awareness doesn’t automatically solve it. There’s a gap between tracking contribution in theory and doing it fairly at scale.
Then there’s the incentive layer, which feels familiar if you’ve spent any time around crypto projects. Rewards, participation campaigns, token distribution—they create movement, but not always meaning. People show up quickly when there’s something to earn. The harder question is whether they stay when the system expects real contribution instead of just activity.
Still, there are parts of OpenLedger that feel grounded in a way that’s hard to dismiss. The push toward integrating AI behavior into everyday tools, like wallets or simple interfaces, suggests it’s not just chasing narratives. If interacting with AI becomes as natural as using an app, and you can still verify what’s happening underneath, that’s a shift people would actually notice.
What sits in the background, though, are the heavier questions that no project can fully answer yet. Once you start assigning value to data, you step into legal gray zones. Ownership, rights, cross-border use—it all becomes complicated very quickly. And decentralization doesn’t magically remove those complications; it just redistributes them.
Even with all that, OpenLedger feels like it’s pointing in a direction that matters. Not because it has everything figured out, but because it’s trying to fix something most people have quietly accepted. The idea that the foundation of AI—data, effort, iteration—shouldn’t just dissolve into the background once the output looks good.
Whether it actually works at scale is still an open question. But if nothing else, it nudges the conversation forward. It makes you pause and ask who really contributes to intelligence, and who ends up benefiting from it.
And once that question sticks in your head, it’s surprisingly hard to ignore.