
医疗影像数据在AI圈子里算得上抢手货,隐私要求高,人工标注费钱,训练模型还离不开这类数据。本来我觉得@OpenLedger 的健康数据板块,肯定能稳稳吃到这波红利,可亲自上手试用后,才发现想象和实际差别挺大。
之前试着上传数据,结果卡在审核验证环节一动不动,干等了半个小时,页面既没提示错误,也没有进度更新,没办法只能中途放弃。不光操作体验不好,质押规则也让人心里没底。官方只说质押门槛会随时变动,说白了就是平台想改规则就能改,普通人事先根本没法知晓。
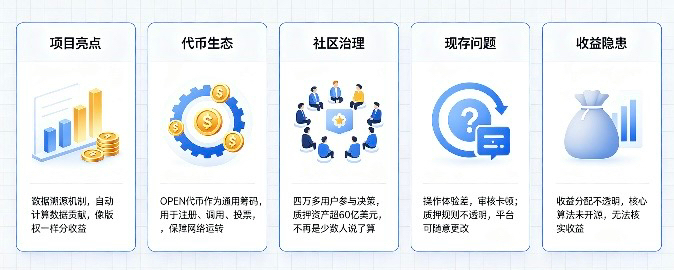
想要参与就得先拿出资产质押,花时间精力上传数据,全程都是自己实打实付出。但收益没有明确标准,所有风险基本都压在了数据贡献者身上。
收益方面也算不上理想,平台每天总共放出30万枚$OPEN 代币,分摊到各个数据板块后,再算到单次数据使用上,到手也就零点零几枚代币。而且平台从来不对外公布真实的数据调用量、实际使用频次这些关键信息,能赚多少钱全靠大家自己猜测。
虽说二层网络手续费不算高,但数据上链记录依旧会产生成本损耗,算下来实际收益还要再变少,目前也没有官方给出具体的成本核算参考。
抛开这些现实问题,项目的设计思路确实挺有新意。靠着数据溯源机制,能自动算出每份数据对AI生成内容起到的作用。这下数据不再是白白消耗的资源,反而能像版权作品一样,被调用一次就能分一次收益,收益会自动打到账户里,不用自己额外申报核对。
OPEN代币也是整个生态的通用筹码,注册模型、调用功能、社区投票都得用到它,既能避免恶意捣乱刷数据,也能维持整个网络正常运转。用户调用产生的费用,会自动分给数据提供者、模型研发者,还有维护平台的团队,资金流向都能在链上查到。
现在整个项目质押资产已经超60亿美元,四万多用户都能参与项目决策,不再是少数人说了算。
不过短板也很突出,核心的数据计算算法没有公开,也没有方便自查的工具。自己的数据被调用多少次、收益怎么分配都没法核实,难免会担心收益被变相稀释。
目前整个行业都没能完美解决AI数据确权溯源的难题,这个项目敢率先把想法落地链上,这份魄力还是值得认可。我也试着上传了数据集观望,暂时没有大额投入。
一边是能让数据持续赚钱的新颖模式,一边又是规则模糊、收益不明的现实困扰,大家觉得这个项目后续能稳步发展,真正实现数据变现吗?#OpenLedger
