One thing I’ve realized while exploring these new systems is that at first glance, they often feel overly controlled and rigid. But when you dig deeper, you see it’s not about creating chaos — it’s about building intentional structure.
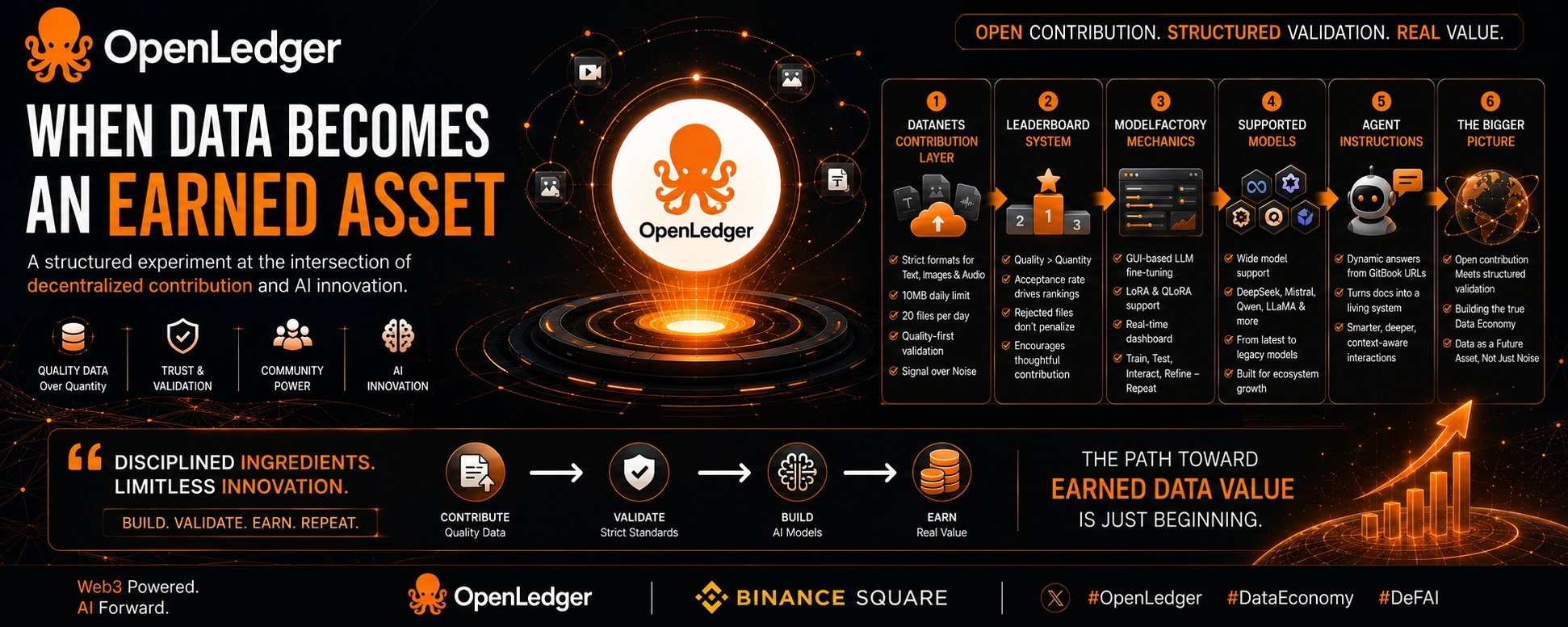
If I’m being completely honest, reading through @OpenLedger ’s documentation left me with one clear takeaway: this isn’t just another AI or data platform. It’s a genuine experiment in turning data into a real “earned asset.”
Let’s break it down.
The Datanets Contribution Layer
What stands out immediately are the restrictions. You can’t just upload anything — text, images, and audio have strict formats and validation rules. In a Web3 world where we expect full permissionlessness, this feels counterintuitive at first. There’s a 10 MB daily limit and a 20-file cap too. 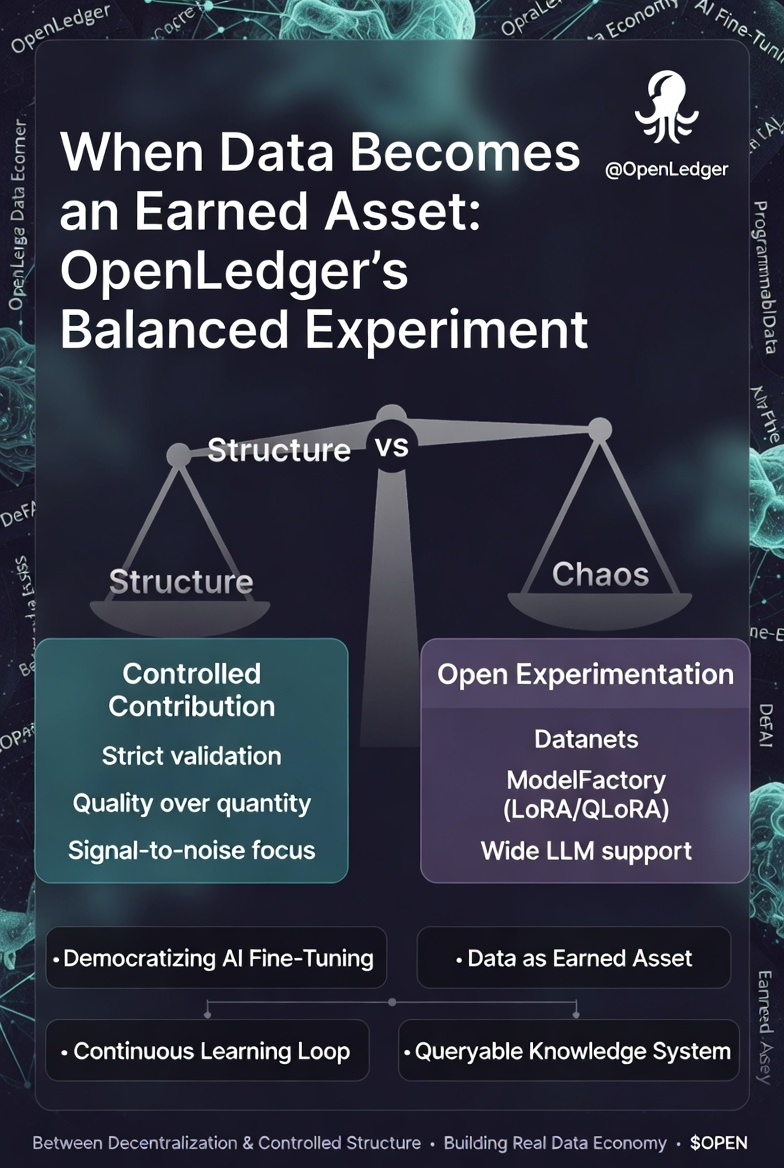
But it makes sense. These aren’t arbitrary barriers — they’re designed to protect signal from noise. Unlimited contributions sound great, but they quickly turn into spam. This approach keeps quality high and makes valuable data easier to find.
The Leaderboard System
Don’t expect to climb ranks just by uploading more. Here, acceptance rate matters far more than volume. Upload ten low-quality files and the system won’t reward you, even if your ego wants it to. Rejected files don’t hurt your standing either.
It’s a surprisingly healthy design — one that encourages thoughtful experimentation instead of fear-driven grinding.
ModelFactory Mechanics
This is where OpenLedger gets serious. They’ve turned LLM fine-tuning into a visual, GUI-driven process instead of leaving it only for coding experts. You can adjust learning rates, batch sizes, and epochs through an intuitive interface.
Supporting LoRA and QLoRA makes it practical and affordable. The real-time dashboard and post-training interaction create a continuous loop: train, test, interact, refine. It’s a smart way to democratize AI development while keeping standards intact.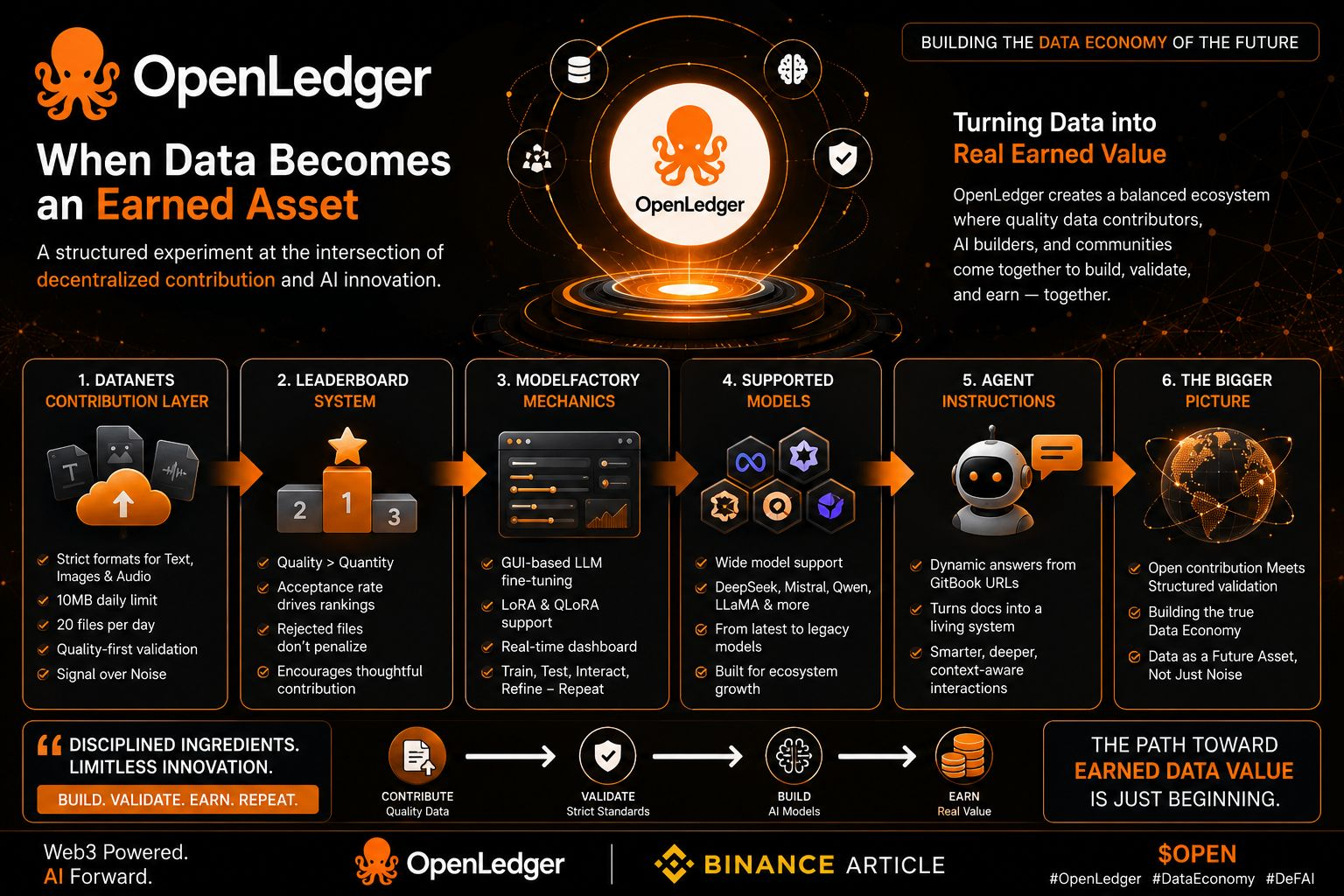
Supported Models
They’ve included a wide range — DeepSeek, Mistral, Qwen, LLaMA series, plus older ones like GPT-2, BLOOM, and ChatGLM. It’s not about chasing only the best models, but creating space for broad experimentation and ecosystem growth.
One image that keeps coming to mind is a disciplined kitchen: ingredients must follow rules, but once the dish is ready, everyone can taste and rate it. Vibes alone won’t get you far here.
The Underrated Agent Instructions
This part allows dynamic answers by pulling from GitBook URLs for deeper queries. It turns static documentation into a living, queryable knowledge system.
The Bigger Picture
@OpenLedger sits at the intersection of two powerful forces: open, decentralized contribution on one side, and strict validation with controlled structure on the other. Balancing them isn’t easy.
If they get it right, this could help create a true data economy instead of just more noise. The real question is whether data can truly become a future asset, or if we’re simply repackaging old validation problems.
There’s no final answer yet, but as an experimentation layer, OpenLedger is definitely worth watching.
What do you think — is this the path toward earned data value?