A lot of blockchain projects try to sound bigger than they are. They pile on words like “ecosystem,” “multi-chain,” and “decentralized future,” and by the end of it you still are not sure what problem they are actually solving.
OpenLedger feels different.
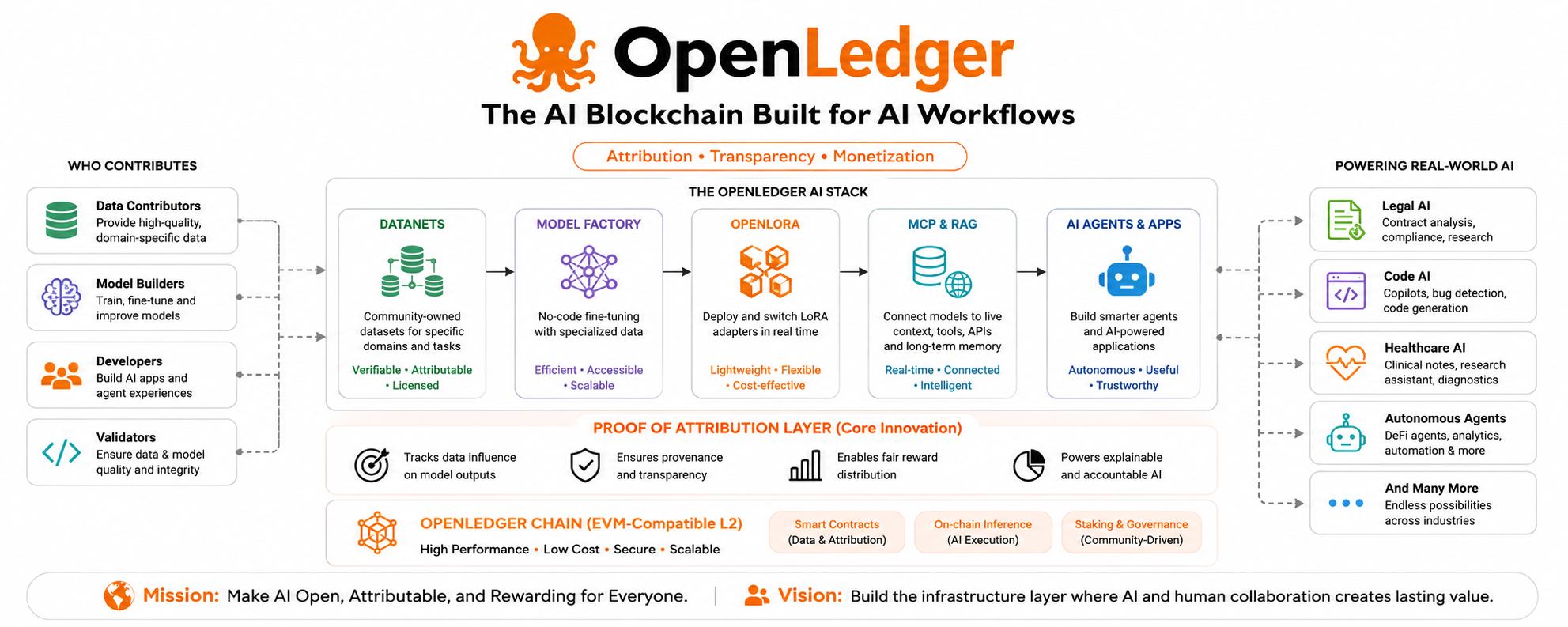
It is not trying to be a chain for everything. In its own words, it is the AI blockchain, built to unlock liquidity for data, models, and agents, and it says plainly that it is not a general-purpose chain. It positions itself as an execution and attribution layer for intelligent systems. That is a much more focused idea, and it gives the project a clearer identity than most crypto narratives manage.
What makes that interesting is that OpenLedger is not just saying “AI lives here.” It is saying AI needs its own infrastructure. Not just a place to deploy tokens, but a place where contribution can be seen, measured, and rewarded. That is the heart of its pitch.
Why that matters
AI systems have a strange habit of hiding the people and data that make them useful. A model can answer a question in seconds, but the value behind that answer may come from many sources: specialized datasets, fine-tuning work, adapter changes, prompt design, retrieval layers, and live context tools. OpenLedger is trying to make that invisible process visible. Its core concept, Proof of Attribution, is meant to identify data influence and connect that influence to transparent rewards, price discovery, and explainability.
That idea sounds technical, but the human meaning is simple. If someone contributes useful data, that contribution should not disappear into the machine. If a model depends on a dataset, that dependency should not be hidden. OpenLedger is trying to turn AI from a black box into something more accountable.
Built around AI workflows, not around generic chain activity
This is where OpenLedger becomes easier to understand. It does not seem to be organizing itself around the usual blockchain categories like payments, DeFi, or NFTs. Instead, it organizes itself around the actual workflow of AI building: data collection, model tuning, deployment, context access, and agent execution. Its own materials describe a pipeline built from Datanets, Model Factory, OpenLoRA, MCP, and RAG.
That structure is important because it shows intent. OpenLedger is not treating AI as a side project. It is designing the chain around the way AI systems are made and used in real life. The project’s product page says Model Factory can fine-tune models with specialized data, OpenLoRA supports efficient adapter deployment, and DataNet is designed for collecting specialized data with verifiable attribution and fair rewards.
That is what makes it feel like infrastructure. Infrastructure is usually not the thing users talk about first. It is the thing that makes everything else possible. OpenLedger seems to want that role inside AI.
Data is not just input here. It is the asset.
One of the strongest parts of OpenLedger’s story is how seriously it treats data. In many AI systems, data is just raw fuel. It is gathered, consumed, and forgotten. OpenLedger treats it more like a living economic object. Its documentation describes Datanets as specialized, attributable data repositories, built around particular domains and use cases rather than broad, unfocused collections.
That matters because AI is increasingly becoming specialized. A legal model needs different knowledge than a clinical assistant. A coding copilot needs different signals than an education tutor. OpenLedger’s approach fits that reality by making domain-specific data a first-class part of the system instead of an afterthought.
There is also a social layer to this. OpenLedger’s framing suggests that contributors should not be invisible. The people who help create useful datasets, improve models, or maintain specialized knowledge should be able to receive credit and value when those contributions are used. That is a very human idea hiding inside a technical design.
The model layer is built for adaptation
OpenLedger also seems to understand that good AI is rarely static. It changes. It gets tuned. It gets adapted to a niche. It gets improved by better instructions, better datasets, and better context.
That is why Model Factory and OpenLoRA matter. OpenLedger says Model Factory is meant to make fine-tuning simpler, while OpenLoRA is designed for lightweight, efficient deployment of adapter variants. In plain English, that means the project is trying to make AI models easier to customize and easier to update without heavy operational overhead.
That kind of design makes the project feel less like a place where models are merely stored and more like a place where models evolve. And that is a better fit for AI than a generic chain ever really could be.
It also thinks about live context, not only training
Another reason OpenLedger feels like infrastructure for AI workflows is that it does not stop at training data. It also talks about live context, retrieval, and external tools. Its blog on MCP says the protocol helps bridge AI models with real-time data sources like blockchains, APIs, databases, and SaaS tools. Another OpenLedger post says the platform uses MCP to let models access external state and context so they can open files, read databases, and invoke tools.
That is a big deal because modern AI is not just about generating text. It is about acting in the world. It needs memory, access, and coordination. OpenLedger is trying to make those live interactions part of the same attributable system as the data and models themselves.
That gives the project a more complete shape. Data does not sit alone. Models do not sit alone. Context does not sit alone. Everything is meant to connect, and everything is meant to be traceable.
The blockchain is real, but it is not the headline
OpenLedger is still a blockchain project, and it says it is EVM-compatible at the L2 level. But the blockchain itself is not presented as the big story. The big story is what the blockchain enables: attribution, model workflows, data monetization, and AI-native applications. In other words, the chain is the machinery underneath the AI layer, not the entire identity of the project.
That is a healthier framing than trying to be a universal chain and hoping AI use cases somehow fit later. OpenLedger starts with the AI problem and designs around it. That is why its messaging feels narrow in a good way. Narrow can be powerful when it is clear.
The bigger idea behind OpenLedger
At a deeper level, OpenLedger is making a bet about where AI value will come from next. It is betting that the future will not belong only to the biggest models or the loudest products. It will also belong to systems that can prove where their knowledge came from, who helped create it, and how value should flow back to the people behind the data and model work. That is what its Proof of Attribution story is really about.
That is also why the project feels more thoughtful than promotional. It is not selling an abstract dream of “AI on chain.” It is trying to solve the quieter, harder problem underneath AI: trust, credit, and economic alignment. Those are not flashy words, but they are the words that matter if AI is going to become a real infrastructure layer rather than just a collection of powerful tools.
OpenLedger’s vision is ultimately simple to say and hard to build: make AI open, make it attributable, and make contribution matter. That is what gives the project its human shape. Not hype. Not noise. Just a clear attempt to build the rails underneath the next generation of AI systems.
