
You can usually tell when a new part of the AI world is still early. The language around it feels bigger than the thing itself. Everyone is trying to name the problem before the problem has fully settled.
@OpenLedger sits in that kind of space.
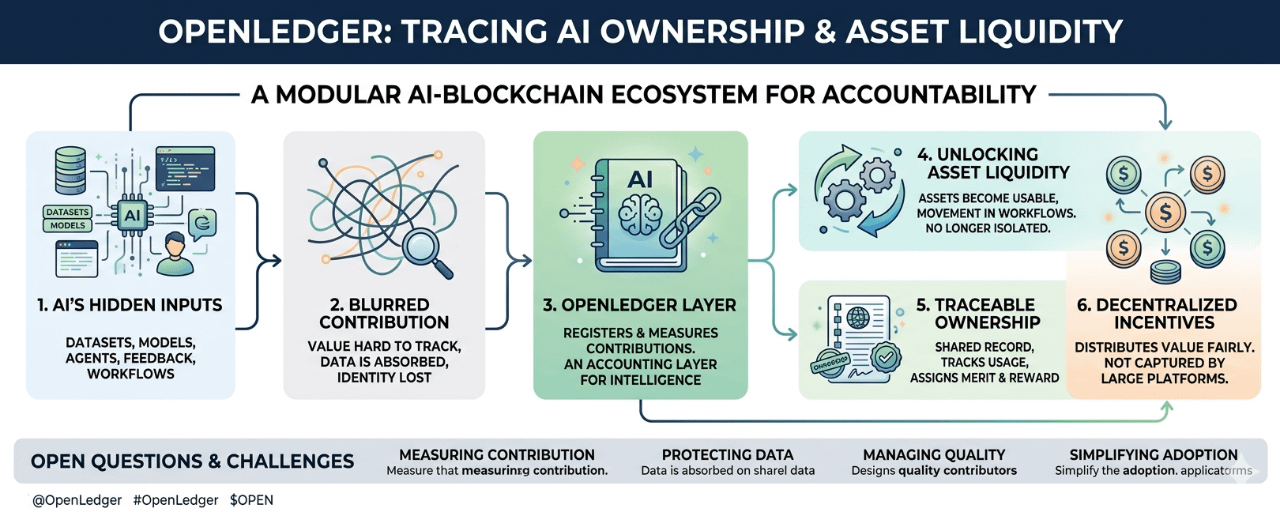
At a simple level, OpenLedger is an AI blockchain built around data, models, and agents. But that sentence can sound heavier than it needs to. The more useful way to look at it is this: AI is starting to depend on many things that people and teams create outside the large platforms. Datasets. Fine-tuned models. Small agents. Domain knowledge. Feedback loops. Workflows. Pieces of intelligence that may not look impressive on their own, but become valuable when they are used again and again.
And right now, a lot of that value is hard to track.
That is where things get interesting.
For years, data was treated as something that had to be collected, cleaned, stored, and then mostly locked away. Companies gathered it because they knew it might matter later. Researchers built datasets. Developers trained models. Communities created behavior patterns that made systems smarter without always being seen or rewarded for it.
AI made this more obvious. A model is not just code. It carries traces of the data it learned from, the prompts people tested, the evaluations that shaped it, and sometimes the human judgment that corrected it. The final model may look like one product, but underneath it there is a long chain of inputs.
The question changes from “who built the model?” to “what made the model useful?”
That second question is harder.
#OpenLedger seems to be working around that layer. Not AI as a finished app. Not blockchain as a trading surface. More like an accounting layer for intelligence itself. A place where data, models, and agents can be registered, used, measured, and possibly monetized based on their contribution.
That sounds abstract at first. But it becomes obvious after a while why something like this might be needed.
Imagine a small team has a strong dataset in a narrow field. Maybe it is medical imaging, logistics, local language data, legal documents, or market behavior. The dataset has value, but the team may not want to sell it outright. They may not even know who should use it. They might want it to help train models, improve agents, or support AI applications, while still keeping some record of ownership and usage.
Today, that is difficult.
Data often becomes valuable only after it leaves the hands of the people who created it. Once it is merged, transformed, or absorbed into a model, the trail gets blurry. The same thing happens with smaller AI models. A model might be useful as part of a larger system, but there is no simple way to prove how often it helped or what value it added.
OpenLedger is trying to make that trail less blurry.
The word “liquidity” matters here, but not in the loud financial sense. It is more about making assets usable. A dataset sitting unused is not liquid. A model that cannot be discovered or plugged into anything is not liquid. An agent that performs a specific task well, but has no trusted way to connect with other systems, stays isolated.
Liquidity, in this context, means movement. It means these AI assets can enter markets, workflows, and applications without losing their identity completely.
That is the part I find worth paying attention to.
A lot of AI discussion still focuses on the largest models. Bigger context windows. Better benchmarks. Faster responses. Those things matter, of course. But beneath that, there is a quieter shift happening. The value of AI may not only sit in one huge model. It may sit in many smaller pieces that work together.
A specialized dataset.
A tuned model.
A scoring system.
An agent that handles one task well.
A feedback stream from real users.
A private knowledge base.
OpenLedger appears to be built for that more modular world.
In that kind of world, ownership needs to become more flexible. Not just “I own this file” or “this company owns this model.” More like: this asset contributed here, was used there, generated value in this way, and can keep participating without being fully handed over.
Blockchain makes sense in that setting because it can act as a shared record. Not because every AI problem needs a token. Not because decentralization fixes everything. But because trust becomes difficult when many different parties are contributing pieces to the same intelligence system.
If data providers, model builders, agent developers, and application owners all need to interact, someone has to keep track of what happened. Who supplied what. What was used. What improved performance. What deserves payment. What terms were attached.
Without that, the default is simple: large platforms capture most of the value.
That has already happened in many parts of the internet. People create content, behavior, and knowledge. Platforms organize it. Then the platform becomes the main economic layer. AI may follow the same pattern unless there are better ways for smaller contributors to stay connected to the value they create.
OpenLedger seems to be asking whether that pattern can be softened.
Not reversed completely. That would be too neat. But maybe adjusted.
Maybe a dataset does not have to disappear into a model without a trace. Maybe a model can be treated like an asset that earns when it is used. Maybe an AI agent can become part of a larger network instead of staying trapped inside one app. Maybe contribution can be measured in a more open way.
There are still a lot of open questions.
How do you measure real contribution fairly? How do you protect sensitive data? How do you stop low-quality assets from flooding the system? How do you make this simple enough that normal builders actually use it? These are not small details. They are probably the hard part.
And yet, the direction feels understandable.
AI is making intelligence easier to package. Blockchain, at its best, can make ownership and usage easier to trace. OpenLedger is trying to bring those two ideas together around the assets that feed AI systems.
Not in a flashy way, at least not when you strip the language down. More like a quiet attempt to give AI’s hidden inputs a market, a memory, and a way to keep their names attached.
That may end up mattering more than it first appears. Because as AI becomes more common, the important question may not be who has access to intelligence.
It may be who gets recognized when intelligence is built from many hands… and who quietly disappears into the background.
$OPEN
Άρθρο
OpenLedger and the slow shift around AI ownership
Αποποίηση ευθυνών: Περιλαμβάνει γνώμες τρίτων. Δεν είναι οικονομική συμβουλή. Ενδέχεται να περιλαμβάνει χορηγούμενο περιεχόμενο. Δείτε τους Όρους και προϋποθέσεις.