
I was scrolling through some on-chain discussions the other night, nothing serious at first, just the usual mix of noise and half-formed ideas. Then I kept seeing OpenLedger mentioned in different contexts, not as a hype topic, but more like people trying to figure out what it actually means when data itself becomes something you can earn from. It made me pause longer than I expected.
I remember when “data” in crypto mostly meant analytics dashboards or something traders used to get an edge. It never felt like an asset in its own right. You just used it, consumed it, moved on. So when I first read about OpenLedger framing data, models, and agents as something that can be monetized directly, it felt slightly unfamiliar. Not exciting in a loud way, more like… wait, how would that even work in practice?
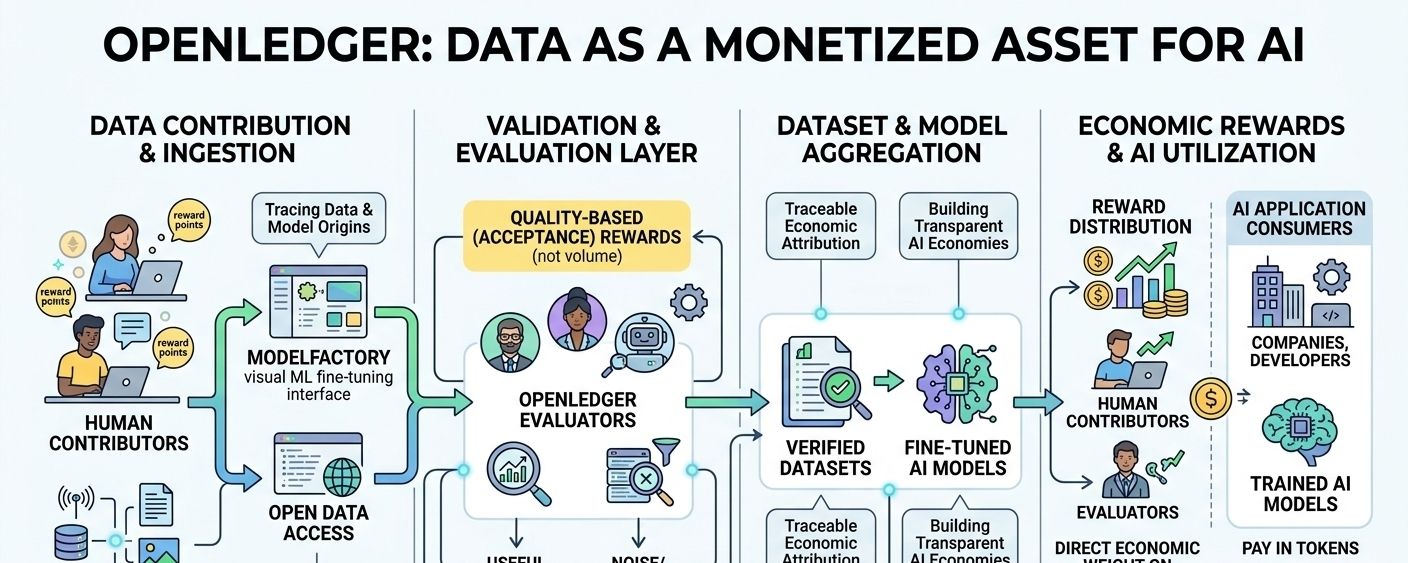
The idea seems simple on the surface. People contribute data or models, and instead of it disappearing into a system where value is hard to trace, it gets tracked, evaluated, and rewarded. OpenLedger sits in that intersection where AI infrastructure meets incentive design. But I keep wondering whether simplicity in explanation usually hides complexity in execution.
What stood out to me more than the narrative itself was the emphasis on contribution quality. Most systems I’ve seen, even outside crypto, tend to reward volume. More uploads, more activity, more noise sometimes. OpenLedger seems to lean the other direction, where acceptance and validation matter more than raw participation. I’m not fully sure yet if that actually holds up under scale, but the direction is interesting.
It also reminds me of early data marketplaces that tried to price information but struggled with trust. The missing piece back then wasn’t demand, it was verification. Who decides what data is useful? Who filters what is just filler? If OpenLedger is really pushing acceptance-based evaluation, then the real question becomes who the evaluators are and how neutral they stay over time.
There’s also this ModelFactory layer people talk about, where model fine-tuning is made more accessible. I’ve seen similar ideas before, visual interfaces for complex ML workflows. They usually start simple and then slowly drift back into complexity as real users push the limits. Maybe I’m wrong, but I feel like that tension between accessibility and depth is where these systems either succeed or quietly fade out.
Another thing I keep thinking about is whether contributors actually care about “ownership” of their data in a practical sense. In theory, everyone says yes. But in reality, most people just want outcomes, not systems. If rewards are small or delayed, attention usually moves elsewhere. That’s just how attention works in crypto too, even if we don’t like admitting it.
At the same time, there’s something quietly compelling about the idea that AI training data could become traceable and economically attributed. Not in a perfect sense, but at least partially structured. I don’t know if we’re ready for that level of transparency, or if it even stays transparent once the system grows. That uncertainty keeps coming back when I think about it.
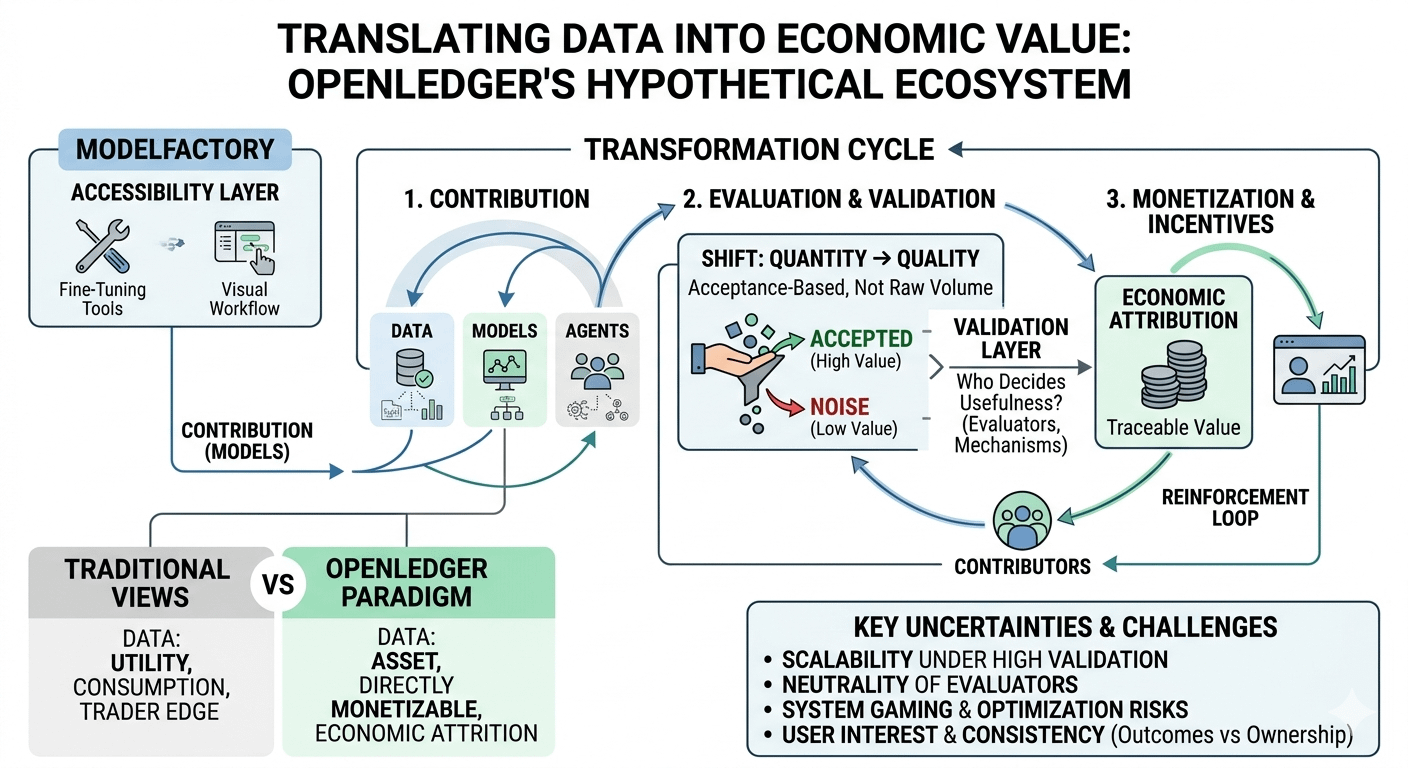
I also keep asking myself whether “monetizing data” changes behavior in a good way or just adds another layer of gaming the system. People optimize whatever you reward. That’s almost a law at this point. So if data becomes valuable, do we get better data, or just better-optimized submissions that look valuable?
What makes OpenLedger slightly different in my mind is that it isn’t just trying to build a dataset or a model marketplace. It feels closer to an economic experiment where AI output, human contribution, and validation layers are tied together. Still, I’m not fully convinced I understand where the real bottleneck is going to appear first.
Maybe it’s scalability. Maybe it’s governance. Or maybe it’s something simpler, like whether enough people actually care to participate consistently without immediate visible payoff. I don’t know yet, and I think that’s part of why it sticks in my head longer than other projects I scroll past.
If I step back, the broader shift here feels less about OpenLedger specifically and more about this slow move toward treating information as something that carries direct economic weight. We’ve been moving in that direction for years, but most systems still feel indirect. This one tries to tighten the loop.
I’m not sure where it goes from here. Some days it feels like these systems will become foundational infrastructure for AI training economies. Other days it feels like we’re still early in understanding what “valuable data” even means in a machine learning world. That back-and-forth is probably the most honest place to be right now.
And maybe that’s the part I keep returning to. Not certainty, but the fact that the system is still open enough to question.
