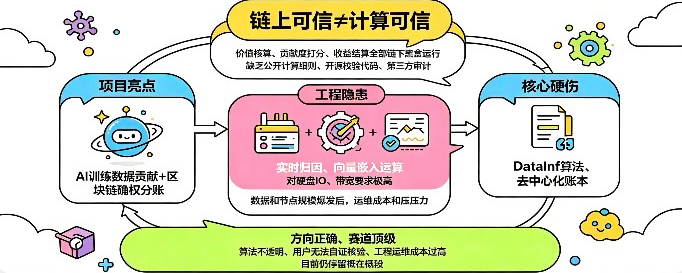

聊点圈内真实的干货,不吹不黑,客观扒一扒@OpenLedger 现阶段最核心的硬伤。
很多人看好这个项目,无非是看中它独一无二的叙事:把AI训练数据贡献,用区块链做确权、自动分账。
坦白说,它的技术选型真的没问题。
引用学术界成熟的DataInf近似算法、自研归因计算公式、后缀数组令牌检索、OpenLoRA实时归因……整套架构完全对标大模型数据确权赛道,逻辑先进、叙事超前。
而且依托去中心化账本,所有数据上链记录真实不可篡改,解决了传统AI行业数据盗用、无法溯源、无法分润的老难题。
但!整个项目最致命的问题,恰恰是所有散户最容易忽略的一点:链上可信,不等于计算可信。
这也是目前AI+区块链赛道的通用死穴。
OpenLedger所有的数据价值核算、贡献度打分、代币收益结算,全部在链下完成。
白皮书公示的归因公式看着严谨,但没有公开可复现的计算细则、没有开源校验代码、没有第三方审计背书。
这就导致:所有人看到的,只是最终结算结果,中间全过程是完全封闭的黑盒。
区块链只能保证“数据确实上链了”,但完全无法保证“系统给你的贡献分算得精准无偏差”。
记录不可篡改,不代表结果绝对公正。
除此之外,工程落地的隐性成本隐患非常大。
大模型级别的实时归因、向量嵌入运算、海量日志存储,对硬盘IO、带宽资源、动态索引运维要求极高。现在体量小问题不明显,一旦全网数据、节点规模爆发增长,高昂的硬件成本和运维压力,会直接考验项目的长期稳定性。
客观总结:
OpenLedger方向绝对正确,赛道绝对顶级,它找到了AI行业数据价值流转的最优解。
但现阶段,算法不透明、用户无法自证核验、工程运维成本过高三大问题没解决之前,所有“数据挖矿、数据分润”,都只能停留在概念阶段。
概念落地不了,再华丽的技术架构都是空谈。
想问下圈内朋友:
你觉得#OpenLedger 后续能通过ZK零知识证明、公开算法源码、第三方审计,彻底打通归因透明化吗?还是这套模型本身就存在无法突破的天然缺陷?评论区交流下真实看法!$OPEN
