
A few days ago, I was spending time exploring different AI-focused blockchain projects. At first, most of them sounded almost identical. Everyone talked about open participation, decentralization, and community-driven contribution. On the surface, it sounded exciting like a future where anyone could participate equally 😇
But after looking deeper, one pattern became impossible to ignore.
Most decentralized systems start organized, then slowly become overwhelmed by noise as they scale. The reason is simple: people optimize around incentives. If rewards are tied mostly to volume and activity, the ecosystem gradually fills with repetitive uploads, low-quality data, and contributors chasing rewards instead of solving meaningful problems.
That was the point where OpenLedger started feeling different to me.
Honestly, my first impression was that the platform seemed unusually restrictive. Upload limits, structured categories, approval layers it all felt almost opposite to how most crypto ecosystems market themselves today. While many projects aggressively push openness and unlimited participation, OpenLedger appears far more focused on structure and filtering.
The more I studied it, though, the more I realized that might actually be the important part.
Because the biggest challenge in decentralized systems is not technology. It is coordination.
Think about a large city without traffic signals. When roads are empty, everything moves smoothly. But once traffic increases, the entire system begins collapsing into chaos because everyone is trying to move at the same time without direction.
A lot of blockchain ecosystems feel similar right now.
People are uploading data, training models, and contributing constantly, but very few projects are asking how useful signal can survive long term inside growing noise. OpenLedger seems to be thinking about that problem earlier than most.
The Datanets structure especially stood out to me. Contribution does not appear to be measured only by quantity. Contextual usefulness and approval quality seem to matter too. That changes the psychology of participation completely. The environment starts feeling less like a mining race and more like a collaborative research network.
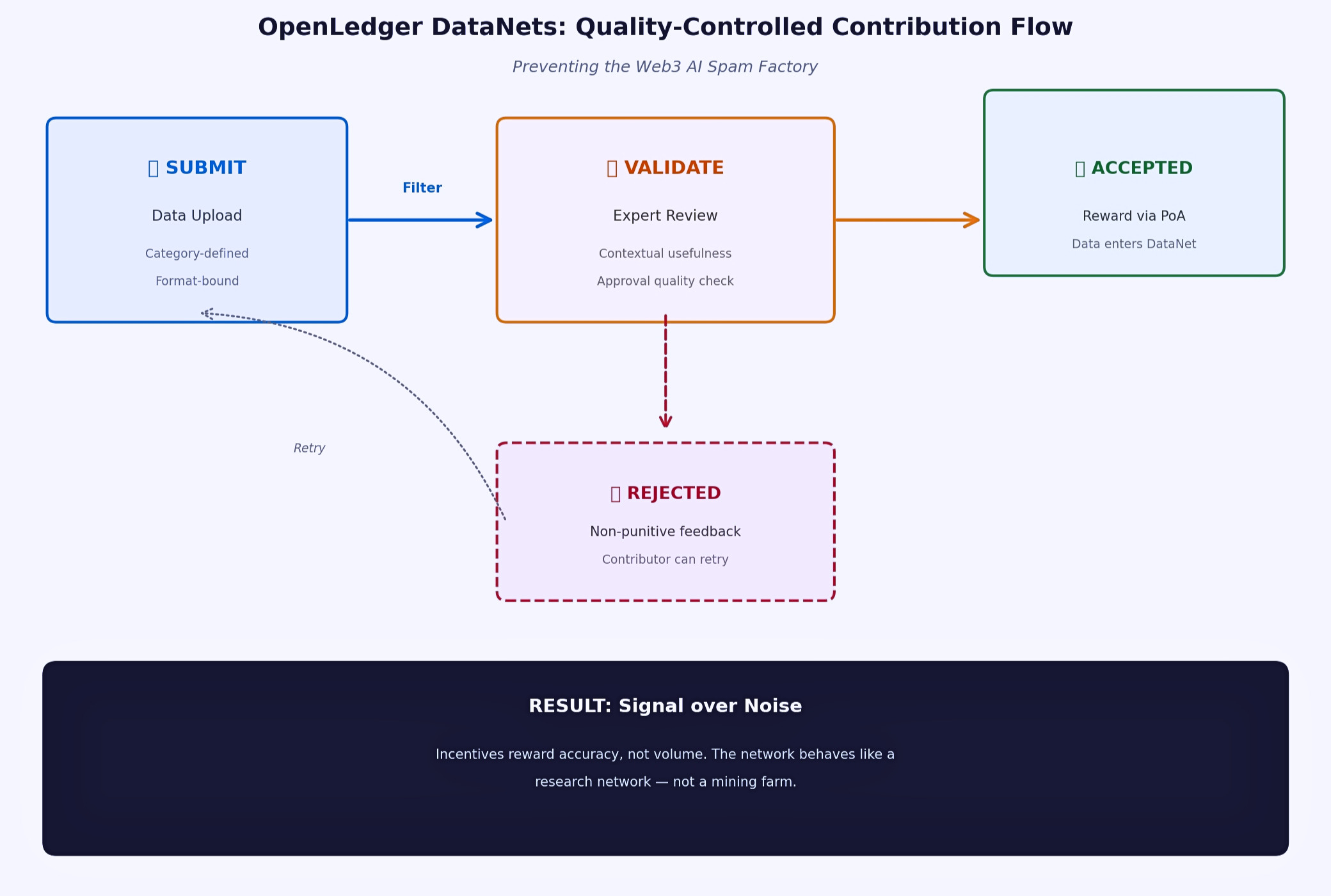
Another subtle but important detail I noticed was how failed submissions are handled.
In many systems, rejection becomes so punitive that people stop experimenting altogether. Everyone starts playing safe because failure feels expensive. Innovation quietly slows down. OpenLedger’s approach feels more balanced. There is structure, but experimentation does not seem heavily discouraged.
I think that balance matters more than people realize.
Because unrestricted openness eventually creates spam, while excessive control slowly kills innovation. Sustainable ecosystems need a middle ground between those two forces.
The ModelFactory side of the ecosystem also caught my attention for similar reasons.
Even today, most AI tooling remains highly technical. Many training environments still depend on terminal commands, scripting knowledge, and complex setup processes that immediately filter out non-technical users. So even when ecosystems claim to be open, participation often remains limited in practice.
OpenLedger appears to be reducing that friction through interface-driven workflows. Adjusting learning rates, epochs, or batch settings through direct controls may sound like a small detail, but usability changes adoption behavior in powerful ways.
Good infrastructure often becomes invisible. Users simply feel that the system is easier to interact with.
Of course, simplicity also creates new risks.
The easier experimentation becomes, the more low-quality experimentation increases as well. That is why accessibility alone is not enough. Organizational control still matters. OpenLedger seems to be experimenting with that equilibrium.
Its support for LoRA and QLoRA training methods also feels practical rather than narrative-driven. Realistically, full-scale model training remains too expensive for most independent builders. Lightweight adaptation systems are far more aligned with how people actually operate today. Projects that ignore this economic reality often end up building for hype instead of real usage.
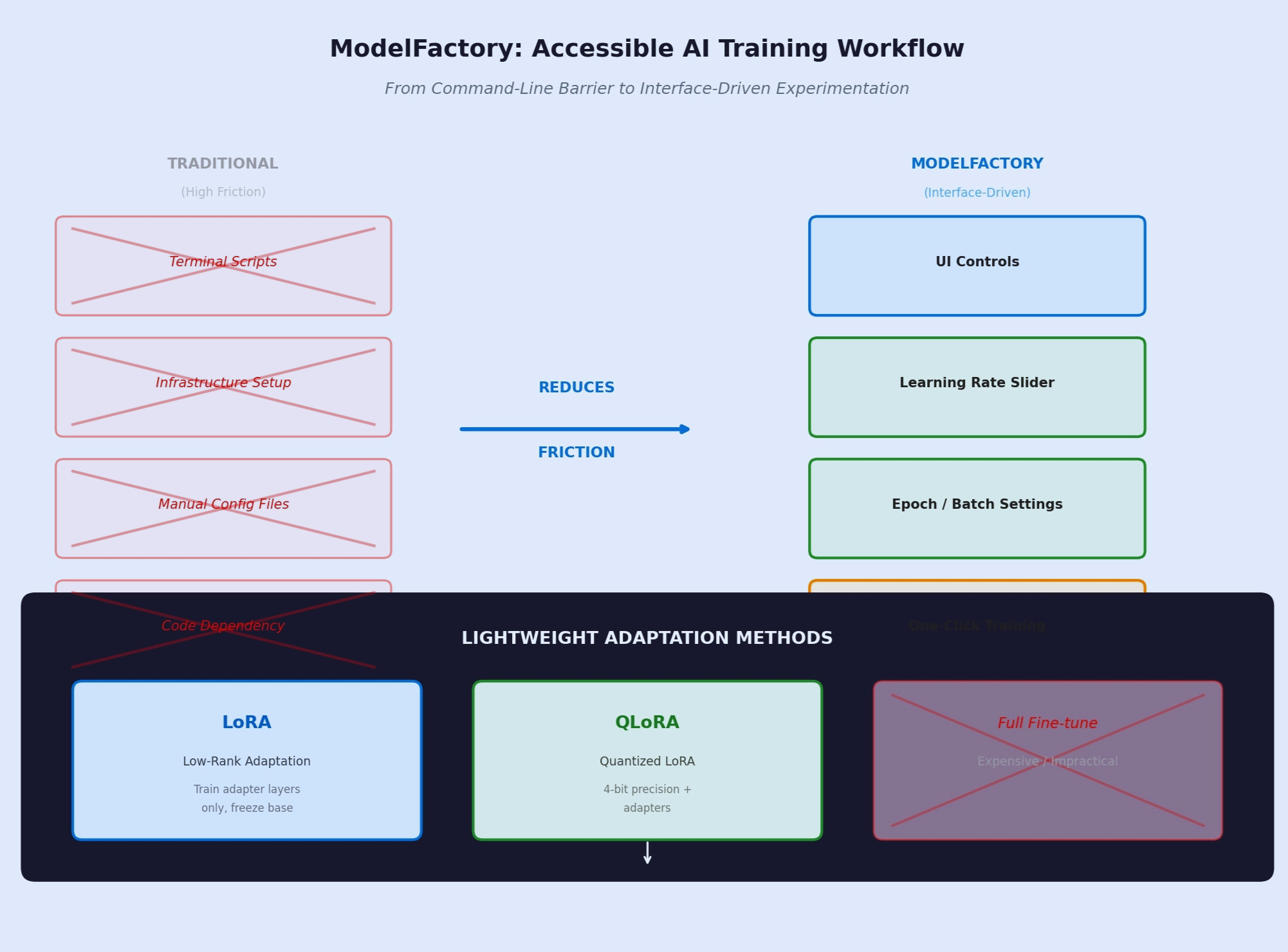
Another thing I found interesting was the ecosystem’s compatibility approach.
Supporting multiple model families like DeepSeek, Qwen, Mistral, and LLaMA creates flexibility at the infrastructure layer and reduces dependency risk. Blockchain ecosystems often become fragile when everything is forced into one narrow standard.
At the same time, maintaining openness is difficult.
The broader the compatibility, the greater the coordination pressure, maintenance complexity, and scaling challenge become. Many projects grow quickly at first, then quietly struggle once operational pressure increases.
I am not claiming OpenLedger will automatically succeed. Many ambitious decentralized AI projects have failed before once incentive systems faced real scale.
But one thing stands out to me clearly: OpenLedger seems aware of these trade-offs from the beginning.
The ecosystem feels less like a speculative hype launch and more like a structured infrastructure experiment trying to solve practical coordination problems step by step.
And honestly, that may become increasingly valuable over time.
Because as AI ecosystems grow larger, markets will not only care about intelligence. They will care about trust, organization, reliability, and whether systems can still function under pressure.
In the end, the real challenge is not simply creating decentralized participation.
The real challenge is building decentralized systems that people can still trust once the crowd finally arrives.🫡