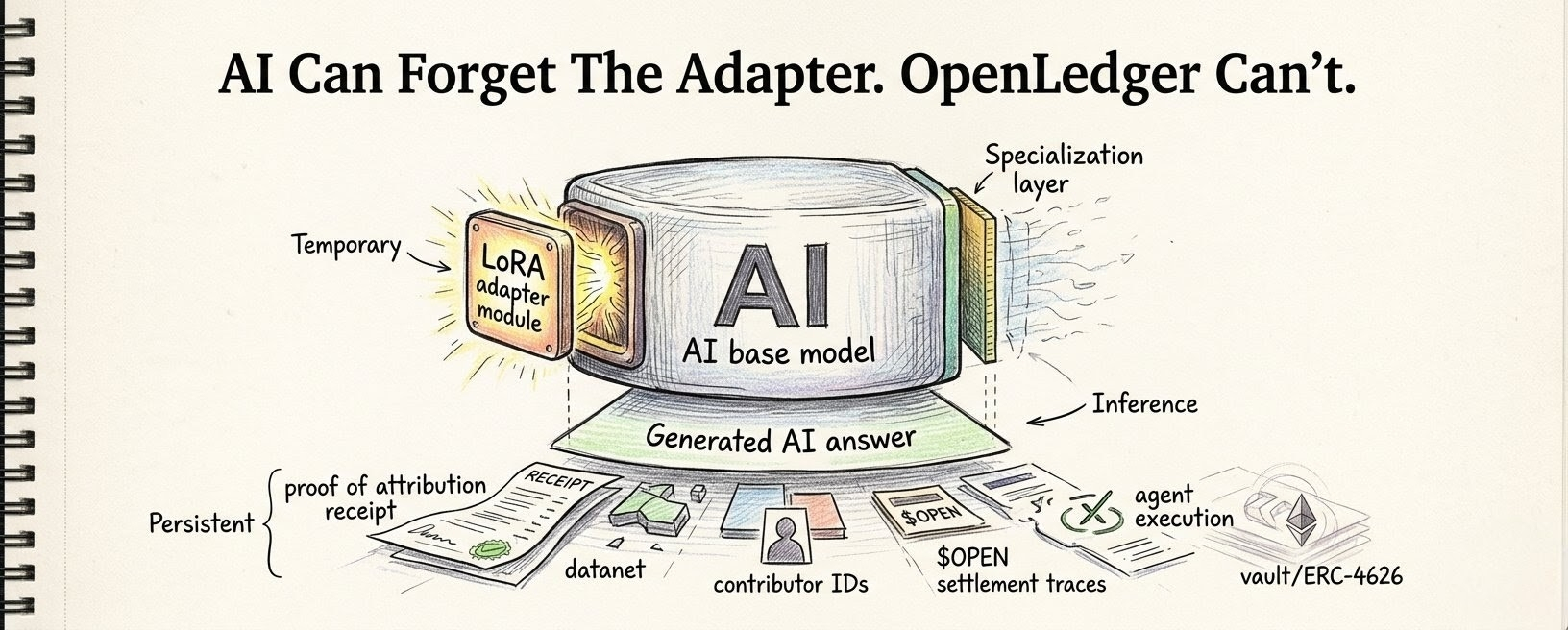

i keep thinking people talk about data inside OpenLedger (@OpenLedger ) like the hard part is just getting enough of it into the system.
good data, verified data, structured data, vertical data, Datanets, all that.
and yeah obviously that matters. bad data ruins things fast. garbage goes in, model gets weird later, everyone acts surprised, same old story. but the more i sit with OpenLedger the less i think the real tension stops at data quality itself. or does it ever really stop there.
because once a OpenLedger system starts doing Proof of Attribution properly, once it starts tracking what influenced outputs and who entered the path and what contribution actually mattered during inference, it feels like something else starts happening under that.
the system begins remembering the people behind the contributions too.
not in some soft social way. not “community” memory. not vibes. more like operational memory, contributor memory, memory that can lean on future reward logic.
and that changes the feeling of the whole thing more than people admit. because what is being remembered then, really? the data, sure. but also the pattern behind the data. the hand behind it.
because in most AI systems, even bad contribution just disappears into the blur. web gets scraped, junk gets mixed with signal, behavior gets flattened, and later a model comes out sounding a little smarter or a little more broken and nobody can really point to where the rot accumulated. no trail, no lasting mark on the hands feeding the machine, no real consequence except inside some hidden internal metrics nobody sees.
OpenLedger feels like it refuses that fog.
once Datanets exist, once data lineage matters, once attribution starts connecting output back to source, once repeated low-signal contribution can actually show up in future weighting, the question stops being only “what data entered?” and starts becoming “who keeps feeding this thing well, and who keeps polluting it?”.
that second question is where it gets uncomfortable for me.
because now contribution is no longer just an act. it starts looking more like a behavior pattern.
and behavior patterns have memory.
i keep coming back to this because people usually hear “contributors get rewarded” and think that’s the whole economic story. help the system, get paid, done. clean, fair, sounds nice. but OpenLedger’s own logic pushes way past that. if contributor reputation matters, if influence scoring matters, if low-quality or adversarial input can trigger penalties, if future rewards can get reduced because of what you previously fed into the system, then the economy is not only rewarding useful data.
it’s building a memory of contributor quality across time.
so now the system is not just asking whether one upload was helpful.
it’s asking what kind of contributor have you been, repeatedly, under pressure, across different moments where real inference happened and attribution had something concrete to calculate.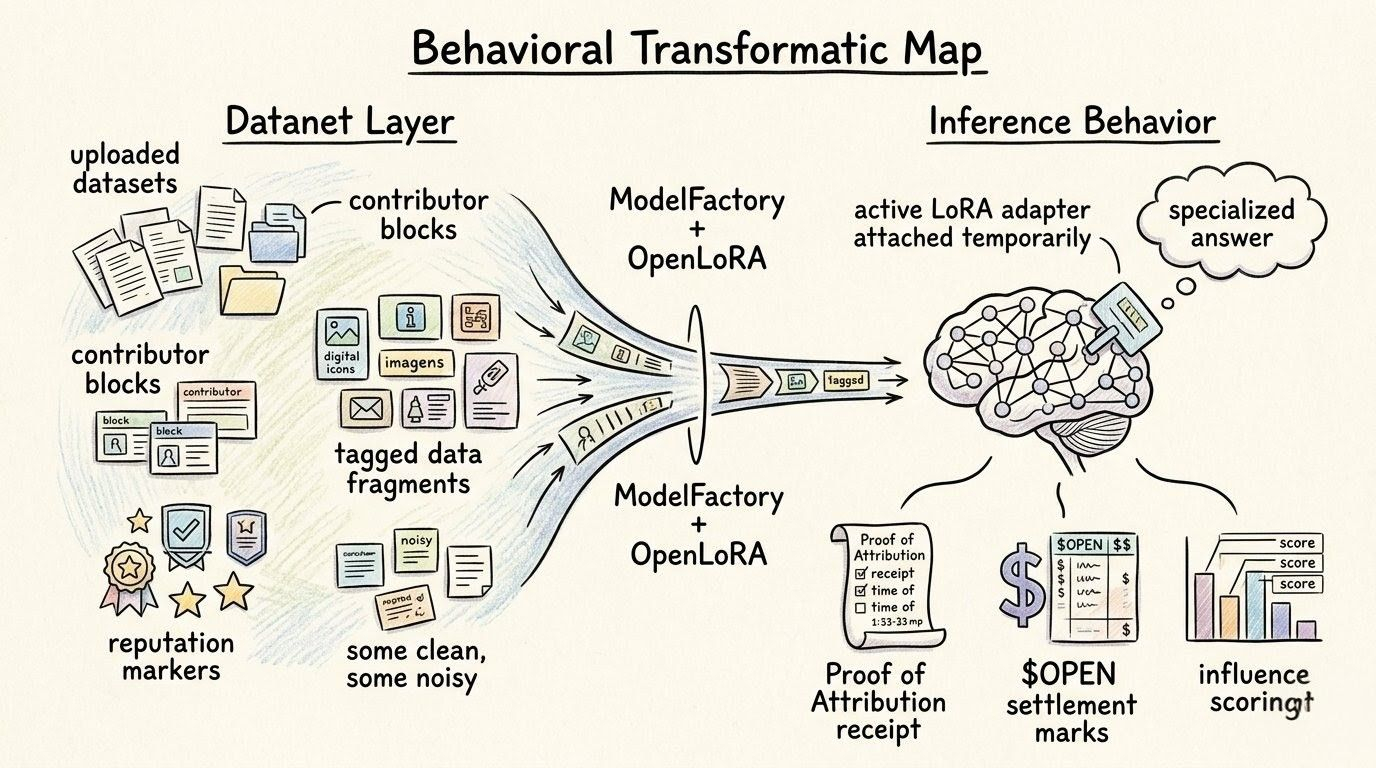
that feels heavier than the usual “AI data economy” line people throw around. heavier than it sounds at first, anyway.
because a one-time mistake is one thing. a bad pattern is another.
and if OpenLedger starts distinguishing between those two, then contribution becomes less like dumping assets into a pool and more like building a record inside a machine that doesn’t forget easily, a record that can keep leaning on future reward share long after one upload disappears from your mind.
“the data enters once. the behavior stays longer.”
that line keeps sitting there for me.
because it means the OpenLedger system is not just pricing outputs. it is slowly pricing habits.
and habits are a different kind of truth. maybe harsher too. because habits don’t care what you meant, only what you kept doing.
i keep picturing somebody contributing to a Datanet over and over. maybe at first it looks fine from the outside. structured enough, tagged enough, nothing obviously broken. but later, after models get trained, after OpenLoRA routes narrow specialization into live inference, after answers actually start moving through real usage paths, maybe the influence looks weaker than expected. maybe the data keeps showing up in low-signal zones. maybe it overlaps too much, maybe it’s noisy, maybe it nudges outputs the wrong way, maybe it just keeps adding weight without adding precision.
what happens then.
does the OpenLedger system politely ignore it forever? maybe a normal system would. maybe that’s exactly what old AI would do, just absorb it and move on.
but OpenLedger doesn’t sound built for polite forgetting. not if contributor reputation and penalty logic are real parts of the pipeline. not if future rewards can be reduced. not if low-quality contribution can keep affecting how the system sees you later the next time attribution wakes up and value gets split again.
so suddenly the economic layer changes shape.
it’s not only “did this dataset matter?” it becomes “what have you been like to this network?”.
that’s a much more serious question than people make it sound.
because once the openLedger system remembers behavior, contribution becomes something closer to exposure. you’re not just offering data anymore. you’re exposing your pattern of judgment to a network that can keep scoring it long after one upload stops feeling important.
and this is where the protocol stays sharper than the softer story people tell around it. this is not just some vague reputation vibe. this is contributor reputation feeding future weighting, repeated low-signal contribution showing up across later inference paths, weaker influence reducing future reward share, maybe even harsher consequences if the pattern keeps repeating. the system does not need a speech about standards. repeated attributed outcomes become the standard.
“repetition becomes evidence here.”
which is where it starts getting strange.
because AI has spent years pretending memory is mostly for models.
remember the context window, remember the tokens, remember the embeddings, remember the user, remember the prompt, whatever.
but here the system starts remembering contributors too.
not emotionally. economically.
and that’s where i think the real pressure hides inside OpenLedger. because what is reputation here if not accumulated economic memory.
a lot of people still think decentralized AI means more openness, more access, more participation, more chances for anyone to contribute and get rewarded. fine. maybe. but once OpenLedger starts weighting contributor behavior over time, decentralization stops feeling like open participation and starts feeling more like a system where future settlement keeps leaning on your past attributed outcomes.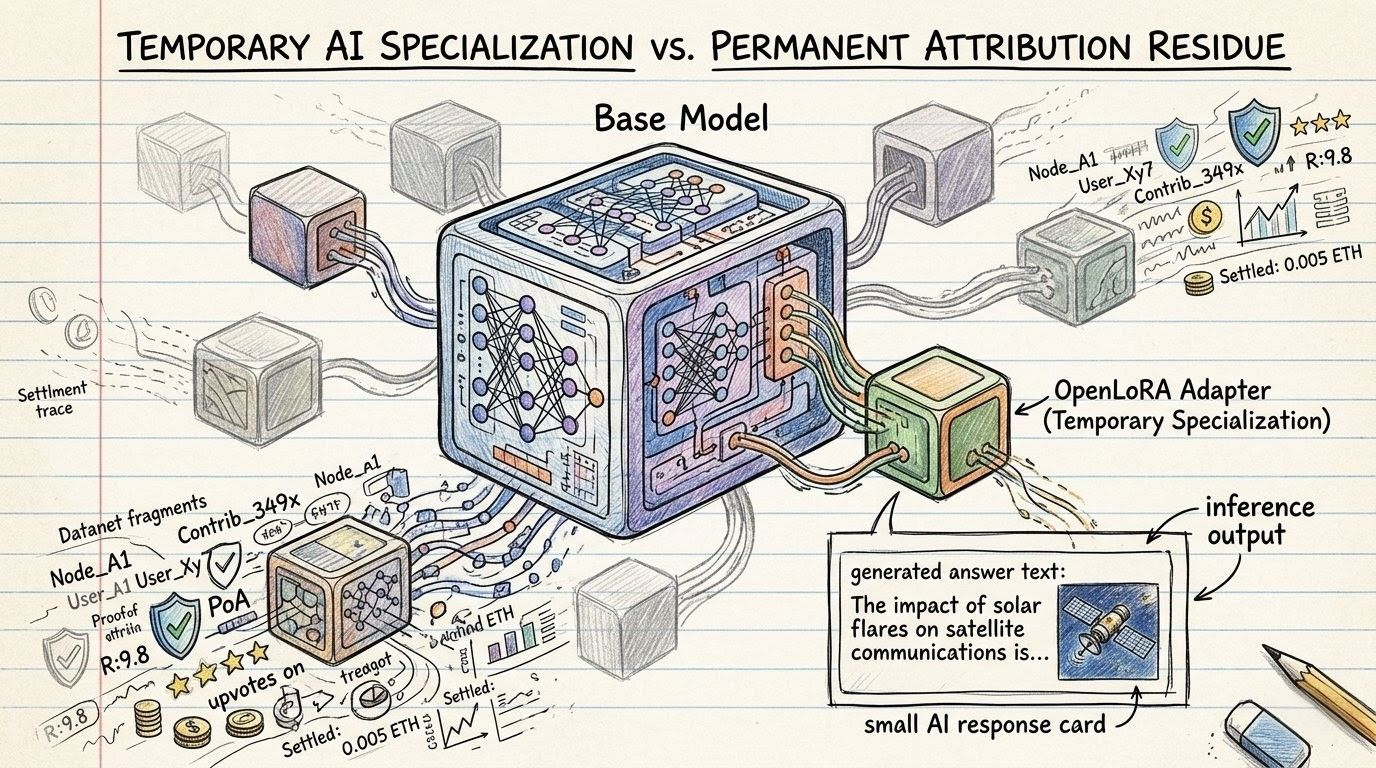
and maybe that’s necessary. maybe it has to be like that. because you can’t keep saying AI should pay for useful inputs if you don’t also build a way to downgrade inputs that repeatedly prove weak, manipulative, redundant, biased, or adversarial.
still… there’s something cold about it.
because now failure doesn’t just disappear into yesterday.
it can follow you forward.
not as drama, just as math.
lower trust, lower weighting, lower reward share, maybe future reduction, maybe quieter forms of exclusion from the flows where openLedger ($OPEN ) actually gets routed.
and all of that can happen quietly, without the theatrical feeling people expect from punishment.
that quietness is what makes it feel real to me.
the OpenLedger system doesn’t need to yell at you. it just needs to remember.
and once it remembers, the next time inference happens, the next time Proof of Attribution wakes up and starts splitting value across the path that produced a live output, your history is already there in the background shaping what kind of weight you carry into that moment.
so then what exactly is a contributor in OpenLedger.
is it a person submitting data.
or is it a reputation vector moving through future reward logic.
or both, and that’s the unsettling part.
i know that sounds too abstract maybe, but it’s honestly what this architecture starts feeling like when you follow it all the way down. Datanets aren’t just curated data surfaces. they become places where contributor behavior gets tested over time. ModelFactory isn’t just a build layer. it becomes one more place where weak inputs can expose themselves later. Proof of Attribution doesn’t just pay backward. it also gives the OpenLedger system material for memory. OpenLoRA doesn’t just make specialization efficient. it creates more real usage moments where bad contribution can get exposed faster because the path is narrower and the task is more specific.
and then the future of it gets even weirder.
because the more active the network gets, the more agents run through OctoClaw, the more payable inference starts happening, the more opportunities there are for the OpenLedger system to learn not only what data helped but what kind of contributors consistently distort or strengthen the network.
so over time OpenLedger may end up doing something big AI never really had the incentive to do.
not just trace data origin.
trace contributor quality as a living economic fact.
that’s bigger than the marketing line. bigger because it changes what contribution even means.
that means the OpenLedger system slowly develops standards without having to preach them first. it just observes repeated attributed outcomes, tracks influence, records patterns, and moves rewards accordingly. almost like governance is happening partly through repeated settlement, not just votes, partly through repeated inference moments that keep hardening into a memory of who strengthens the network and who keeps degrading it.
“the network doesn’t just learn from data. it learns from the hands that keep bringing it.”
and once that’s true, contributor behavior stops being a side detail. it becomes part of the architecture.
that’s why i don’t really read OpenLedger as just another fairness layer for AI. fairness is too soft a word for what this turns into. this is closer to behavioral accounting inside an attribution economy, a system where your past contribution quality can keep leaning on your future economic reality.
and yeah, maybe that’s exactly what AI needs.
because right now most AI systems are built like giant appetite machines. they consume everything, forget the source, hide the route, monetize the output, and call that intelligence. OpenLedger at least tries to break that by forcing provenance, attribution, and payout into the center. but the moment you do that, the system gets pulled toward a harder truth too: if good contribution should be remembered, then bad contribution probably should be remembered as well.
you can’t really have one without the other.
and maybe that’s the real transition nobody talks about enough.
the system is no longer only tracing where value came from.
it’s learning which participants keep degrading that value and which ones keep strengthening it across repeated inference and settlement.
and what happens once that learning hardens? once it stops feeling like observation and starts feeling like economic gravity.
maybe the deeper thing inside OpenLedger is not that it pays data.
maybe it’s that over time it starts assigning memory to behavior, and once that happens the economy gets sharper than people expect.
not just “did you help?” more like what have you been like here, across time, across inference, across consequence.
and once the network starts asking that, OpenLedger doesn’t just feel like gas or reward anymore. it starts looking like the settlement language of a system that is slowly deciding who it can trust to keep feeding it intelligence without degrading it.
that feels way more serious than the usual AI-blockchain pitch.
because data can be uploaded once and forgotten.
behavior can’t.