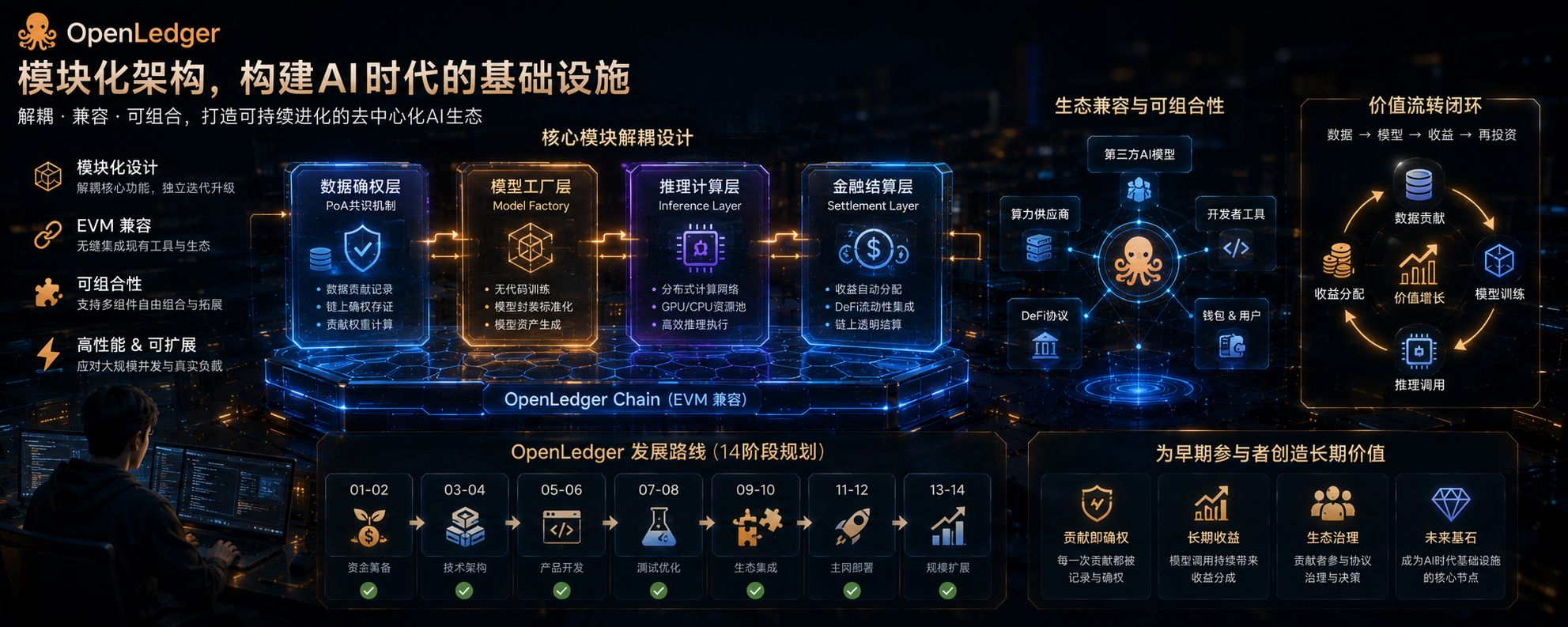
在 Web3 的叙事里,我们看过太多项目因为架构过重导致主网上线后性能崩溃。但 OpenLedger 在架构设计上选择了一条“模块化”的路,这在目前的 AI 赛道显得尤为冷静且务实。
架构的核心逻辑,是“解耦”。
它没有试图在一个协议里做完所有事情,而是将数据确权、模型工厂、推理计算和金融结算做了清晰的拆分。这种模块化架构的好处是显而易见的:当某一个环节需要迭代时,它不需要推倒整个系统重来。这种“拼积木”式的方式,让生态能够快速兼容外部的 AI 工具,而不是闭门造车。
为什么机构对这种“模块化”如此买账?
核心原因在于“可组合性”。对于大型算力机构来说,他们不希望参与到一个封闭的生态里。模块化意味着兼容性,他们可以将现有的 GPU 集群快速接入 OpenLedger,同时利用现有的 DeFi 基础设施进行结算。这实际上是把传统的“算力出租”升级为了“链上资产配置”。
再看这次架构带来的真实体验感。
很多老玩家会感觉到,虽然项目一直在不断更新功能,但底层的交互体验一直很稳。这就是 EVM 兼容带来的红利,它极大地降低了我们作为参与者的操作门槛。你可以用熟悉的钱包,使用熟悉的工具,完成一次次复杂的链上交互。
我们必须认清:一个项目的生死,往往取决于它的“工程落地能力”而非“宏大叙事”。
现在回头看 OpenLedger 的 14 阶段规划,每一个节点(如之前的资金筹备、技术架构构建)都在按部就班地推进。对于我们而言,持续保持在架构内的“参与深度”,就是对这些工程进展最好的投票。
当 AI 时代的“电力网”逐渐铺开,那些早期就参与了架构基建、并保持高质量数据贡献的账户,注定会成为协议最稳定的基石节点。在这个赛道里,比拼的不是谁跑得最快,而是谁能在漫长的基建期里,把每一个模块打磨得最稳。