在币圈混了快十年,看过了太多风口。每天刷广场,除了满屏幕歇斯底里的 Meme 狂欢,就是一堆 AI 概念项目在狂飙官方话术。坦白说,钱包早就被那些动不动就宣称要“重塑生产关系”的 PPT 项目整免疫了。大家都在蹭大模型的热度,但绝大多数项目连最基本的链上摩擦和成本问题都没搞明白。
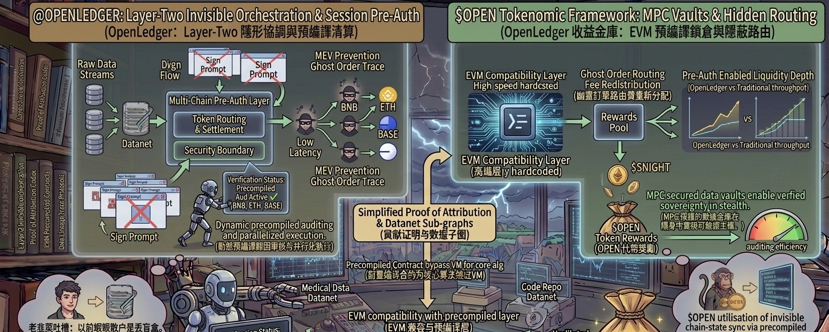
最近翻完 @OpenLedger 的技术白皮书,多数人的目光可能还停留在那些宏大的去中心化数据集或者 OpenLoRA 这种算力分配故事上。但我更关注一个在宣发里几乎没被拿出来吹过的底层细节:**EVM 兼容层中的 Precompiled Contracts(预编译归因契约)**。
大家得明白一个大白话逻辑,AI 训练要给成千上万的数据贡献者算账,每一次数据提交、每一次微调、每一次调用(Inference)都要在链上记录是谁的贡献,这就是所谓的 Proof of Attribution(归因证明)。如果把这个逻辑写成普通的智能合约,每次算力过滤和贡献度清算都要在 EVM 里跑一遍复杂的哈希和矩阵权重分配,那每次跑数所消耗的 Gas 费,能直接把项目方和贡献者全部烧破产。这就像是你为了买一瓶两块钱的矿泉水,却不得不开着一辆百公里油耗五十升的重型卡车去超市。
OpenLedger 聪明的地方在于,它直接在底层用 Layer 2 的预编译合约把这套归因逻辑固化了。
简单来说,它把最吃算力的“数据贡献度审计”算法,直接写进了节点底层的客户端代码里,而不是让它在虚拟机里低效地解释执行。这样一来,复杂的 AI 数据流转和确权,在链上变成了只需要极低固定的 Gas 就能调用的底层指令。这个改动极其硬核,它把原本属于“数学高能耗”的链上清算,硬生生压成了类似于转账一样轻量级的操作。只有把链上摩擦的成本打下来,普通人贡献的那点小微数据才有可能真正变成“能变现的资产”,而不是全扣掉当了手续费。$OPEN
看惯了周期更迭,我常觉得现在的 Web3 AI 陷入了一种奇怪的执念。大家都在拼命证明自己有庞大的算力集群,或者有海量的社区用户在用安卓设备挂机跑节点。但如果底层的账本连最基本的高频归因清算都承载不了,这种虚假繁荣就只是一场左手倒右手的泡沫游戏。
我很赞同把 AI 的生命周期资产化。通过 $OPEN 引入 Proof of Attribution,让数据、模型和智能体在链上拥有可追溯的血统,这确实切中了痛点。但我们更应该看清,技术的核心从来不是那些天花乱坠的词藻,而是最底层的经济学账本能不能算得过来。
从哲学的本质来看,区块链和人工智能其实是硬币的两面。AI 是一种代表着无限中心化坍缩的技术,它把人类社会所有的知识、数据和智慧,最终压缩进那几个巨头手里那几个不透明的参数黑盒里;而区块链则是对抗这种绝对中心化垄断的唯一底层武器。OpenLedger 做的尝试,本质上是在用确定性的去中心化账本,去给那个混沌、不透明且不断膨胀的 AI 黑盒套上缰绳。如果这个账本自身的运转成本不够低廉、不够务实,那对抗垄断就只能是一句空话。希望这一次,我们看到的是技术逻辑的彻底落地,而不是又一个高开低走的资本玩具。