I have been down a bit of a rabbit hole with OpenLedger for the last three weeks and, honestly, I’m still not sure I have a clean one line explanation for it. Every time I think I do, I end up opening another tab and realizing I missed something.
The funny part is I was not even researching OpenLedger specifically. I was trying to map out a bunch of AI related crypto projects and separate the ones building actual infrastructure from the ones that seemed mostly focused on compute marketplaces with AI branding attached to them.
At first I put OpenLedger in that same bucket.
That was probably my first wrong assumption.
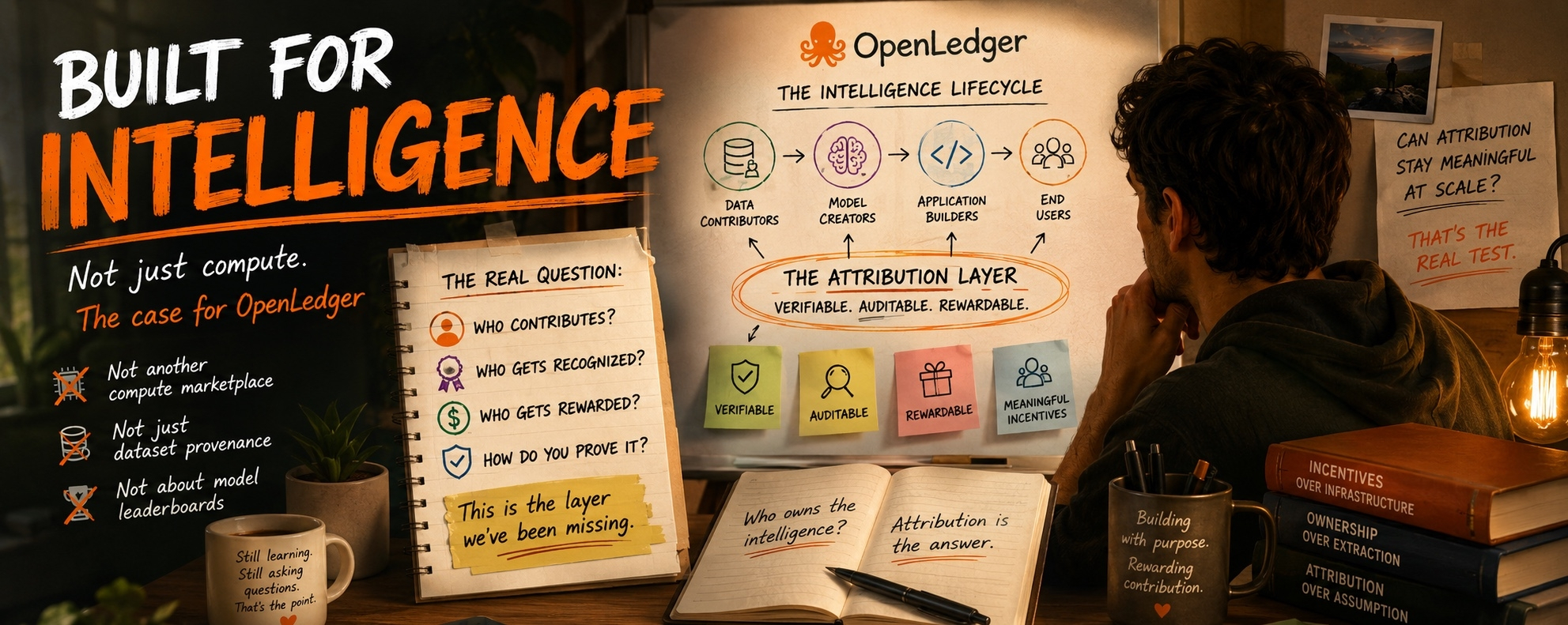
I kept seeing the phrase, Most blockchains were built for finance. OpenLedger was built for intelligence and I interpreted it as marketing language. You know the kind. Big statement, vague meaning.
So I opened the whitepaper.
Then the docs.
Then a Discord discussion thread about attribution rewards.
Then another thread where people were arguing about data contributors versus model builders and somehow forty minutes disappeared.
I actually wasted almost an hour thinking the attribution layer was basically a fancy version of dataset provenance. Just a system for tracking where data came from. Turns out that’s not really the point. Or at least not the whole point.
The way I understand it now they are trying to build infrastructure that tracks contributions across the intelligence creation process itself. Data contributors, model creators, application developers, different participants in the pipeline. The attribution layer is not just recording assets. It’s trying to record who contributed value and make those contributions visible.
At least that’s the goal.
Whether it works at scale is a completely different question.
There was another dead end where I got confused by some of the documentation around verifiable intelligence. I kept reading it through the lens of model performance benchmarks. Thought it was mainly about proving model quality.

Then I went back through a section of the docs and realized they were talking much more about verification and attribution than leaderboard style evaluation. Different thing entirely.
That changed how I looked at the project.
Most crypto AI projects I have researched spend a lot of time talking about compute.
GPUs.
Inference.
Training resources.
Resource allocation.
OpenLedger feels like it’s asking a different question.
What happens after intelligence is created?
Who owns the underlying contribution?
Who gets recognized?
Who gets rewarded?
And how do you prove any of that?
I was reading one document page about contributor incentives while simultaneously trying to fix a squeaky desk chair in my apartment. Completely unrelated but somehow both problems felt weirdly similar. Every screw looked important until I realized only one of them was actually causing the issue.
That’s kind of how OpenLedger feels to me right now.
A lot of the AI conversation focuses on the obvious parts of the stack. The model. The compute. The output.
OpenLedger keeps pointing toward the less visible layer underneath.
The ownership layer.
The attribution layer.
The incentive layer.
What I find interesting is that contributors are not supposed to become invisible inputs. The idea seems to be that datasets, domain expertise, model improvements, and other forms of contribution can remain linked to value creation rather than getting absorbed into a black box where nobody knows who added what.
Again in theory.
I am not writing this as someone who’s fully convinced.
One thing I still struggle with is imagining how attribution behaves when you have massive numbers of contributors interacting across multiple datasets, applications, and models at the same time. The whitepaper explains the vision reasonably well, but I still end up with practical questions once I start thinking about real world complexity.
And that’s probably why I keep reading.
The project feels different from compute focused AI crypto projects because it is not primarily trying to become another marketplace for processing power. It seems more interested in making intelligence itself auditable and attributable.
That’s a subtle distinction, but I think it’s an important one.
The deeper I get into OpenLedger, the less I think about AI models and the more I think about incentives. Who contributes. Who benefits. Who gets recognized. Who gets left out.
I don’t really have a neat conclusion here.
I understand the attribution layer much better than I did three weeks ago. I understand why they keep repeating the built for intelligence line. I understand why contributor ownership is central to the design.
What I still don’t know is whether attribution can stay meaningful once the network becomes genuinely large and messy.
Maybe that’s the real test.
I haven’t found an answer to that one yet.