玩了快十年的老韭菜都知道,现在市面上绝大多数顶着AI帽子的项目,说白了都是在玩“左手倒右手”的拼图游戏。买几张显卡搞个算力租赁,或者去套个开源大模型的壳子发个空气币,就敢跟市场要几个亿的估值。这不叫创新,这叫赶集。大厂手里的中心化算力围墙和模型壁垒,根本不是这种表面功夫能砸穿的。我盯了去中心化AI赛道很久,直到翻完 @OpenLedger 的白皮书,才发现终于有人开始去啃最硬、也最容易被忽视的骨头:高质量数据的归属与分配。
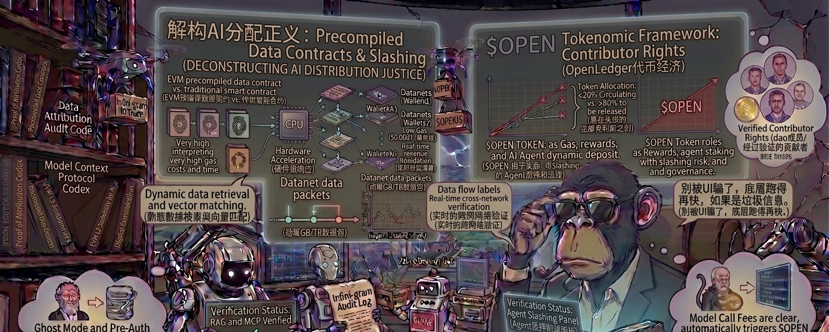
大家都在关注它的Proof of Attribution(归因证明)和Datanets(数据网络),说实话,这些虽然抓住了痛点,但在圈内已经不算完全的新鲜概念。真正让我眼前一亮的,反而是白皮书里藏着的那个几乎没人公开讨论过的底层技术——**预编译数据契约(Precompiled Data Contracts)**。
传统的以太坊虚拟机(EVM)在处理普通的智能合约时还算够用,但如果要让它去跑动辄几个GB甚至TB级别的AI数据流标签、跨网络归属判定和实时的收益清算,那高昂的Gas费和龟速的TPS能直接让所有人破产。OpenLedger把这一套逻辑做成了EVM兼容L2层面的预编译合约,类似于把经常要用的复杂数学公式直接写死在区块链的CPU芯片里。这样一来,复杂的AI数据确权和利润分配不需要再走一遍繁琐的虚拟机指令,而是直接硬件级响应。这才是懂行的人干的事,不搞表面繁琐的堆砌,而是从底层给去中心化AI降本增效。
配合这个底层的,是他们提到的OpenLoRA和智能体(Agent)的质押削减机制。如果一个AI智能体在网络里为了骗取 $OPEN 奖励而故意输出垃圾数据,或者在执行任务时掉链子,对不起,它质押的代币会被直接Slashing(削减)掉。这种用真金白银逼着AI保持理性的做法,比Web2里那些模型出了错只能封号或者发个道歉声明的机制要有诚意得多。$OPEN
但作为一个在这个圈子里摸爬滚打多年的老手,我也不会只说好话。OpenLedger的愿景听起来很性感,但骨感的地方同样明显。几乎八成的代币都还没进入流通,这意味着后续的释放压力会像悬在头顶的达摩克利斯之剑。而且,这种纯粹靠链上博弈构建的数据生态,高度依赖于最初能不能吸引到足够优秀的开发者和干净的原始数据集。如果进来的人全是为了刷交互、薅羊毛而倒腾的垃圾信息,那底层的预编译合约跑得再快,也只是在一个高效的流水线上生产工业垃圾。
我们常说去中心化是为了打破垄断,但在AI时代,打破垄断不仅仅是让大家都有机会买到显卡,而是让每个贡献了思想、留下了数字足迹的普通人,都能拿回属于自己的主权。
这其实是一个关乎数字存在主义的哲学问题。在Web2的世界里,我们每一个人都是免费给科技巨头喂养算法的“数字农奴”,我们的每一次搜索、每一句对话,都成了他们万亿市值的燃料,而我们自己却一无所有。#OpenLedger 的尝试,本质上是在用代码重新构建一种数字时代的分配正义:如果思想是人类唯一的火种,那么当AI试图借这团火照亮未来的世界时,它必须向每一个提供木柴的人致敬,并且支付应有的对价。去中心化AI的终局,不该是创造一个更快的发币机器,而应该是让数据的所有权,重新回归于创造它的神明。