OpenLedger is the kind of project that makes me pause, but not in the clean, excited way people expect.
More like the tired pause you get after watching this market recycle the same three narratives for years, only with better branding each cycle. AI. Data. Ownership. Agents. Incentives. We have heard versions of all of this before. Most of them looked smart on a deck, traded well for a while, and then slowly turned into noise once real usage failed to show up.
So no, I’m not looking at OpenLedger with fresh eyes.
I’m looking at it with scar tissue.
But that is also why it caught my attention.
The project is not only chasing the usual AI model race. That race is already crowded, expensive, and honestly exhausting. Everyone wants to talk about better models, faster outputs, smarter agents, cleaner automation. Fine. Those things matter. But after a point, it starts to feel like everyone is shouting about the machine while ignoring the fuel.
OpenLedger is poking at the fuel.
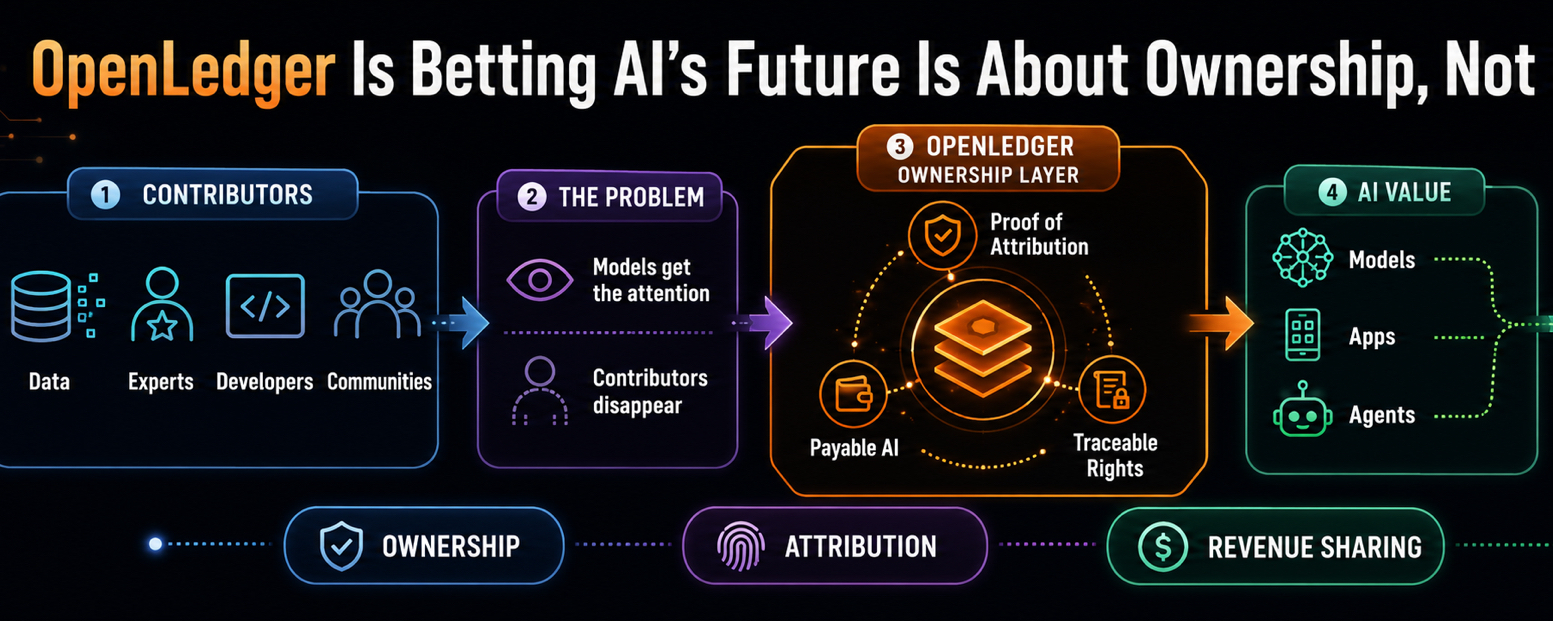
Who owns the data?
Who gets credit when that data makes a model useful?
Who gets paid when an AI system starts producing value from contributions it did not create by itself?
That is the uncomfortable part. And crypto, for all its scams and broken promises, is still weirdly good at forcing uncomfortable ownership questions into the open.
A model does not become useful because someone waved a wand over a server rack. It is built from data, feedback, corrections, human judgment, examples, domain knowledge, and all the boring work nobody wants to mention when the demo looks smooth. The final output feels clean. The supply chain underneath is messy.
That mess is where value hides.
Most AI systems today treat contribution like something disposable. Data goes in. The model improves. The contributor disappears. Maybe they get a thank-you in spirit. Maybe not even that. The upside moves somewhere else.
That pattern feels familiar because crypto has its own version of it. Communities create attention, liquidity, memes, testing, feedback, and early demand. Then insiders, funds, and operators capture most of the value while the crowd gets a slogan and a vesting schedule they did not read closely enough.
Different machine. Same smell.
OpenLedger is trying to argue that AI needs a better accounting layer. Not accounting in the boring spreadsheet sense, although that matters too. Accounting as in memory. Receipts. Attribution. A record of who added value before the system became valuable.
I like that idea.
I also do not trust it easily.
Because attribution is hard. Really hard. It is one thing to say a dataset helped a model. It is another thing to prove how much it helped, when it helped, and whether that contribution deserves a real share of future value. AI does not use data like a vending machine uses coins. Influence gets blended. It spreads. It becomes statistical fog.
That fog is where weak projects hide.
They can say “contributors will be rewarded” without explaining who decides quality. They can say “ownership layer” without showing whether ownership has teeth. They can say “AI agents” because the market still reacts to that phrase, even after half the sector has turned it into recycled noise.
So when I look at OpenLedger, I am not asking whether the story sounds good.
It does.
The real test, though, is whether this thing breaks out of story mode.
Can actual builders use it without feeling like they are dragging a blockchain-shaped weight behind their AI stack? Can contributors trust the attribution logic? Can useful datasets form around it without turning into spam farms? Can the network reward quality instead of activity theater? Can the token have a role that survives after the first wave of attention moves on?
That is where I’m looking.
Because the idea of “payable AI” is interesting, but markets do not pay forever for interesting. They pay for pressure. They pay when a project sits in the middle of a real bottleneck and becomes annoying to ignore.
AI does have a bottleneck here.
The industry has been eating from a giant table of human contribution while acting like the meal cooked itself. Writers, coders, researchers, communities, labelers, users, specialists, documentation nerds, open-source people — all of them helped train the systems that now compete with them, replace parts of their workflow, or monetize their knowledge without much of a return path.
That cannot stay invisible forever.
As AI moves deeper into money, media, work, research, trading, and automated agents, the question gets heavier. It is no longer just “can this model answer well?” It becomes “where did the answer come from?” and “who had the right to use that input?” and “who gets paid if the output creates revenue?”
This is where OpenLedger has a real angle.
Not a clean win. Not yet. But an angle.
It is trying to make AI value traceable. Data, models, apps, agents — all connected by attribution instead of floating around as anonymous machinery. That sounds dry until you realize how much of the next AI economy may depend on clean rights, clean inputs, and clean reward paths.
And still, I keep coming back to the grind.
The grind is adoption. The grind is proving this is not just another infrastructure layer waiting for users who never arrive. The grind is making attribution useful enough that serious people care. The grind is surviving the market’s boredom after the AI narrative cools for five minutes.
Crypto does not forgive slow clarity. It rewards noise first, then punishes anyone who cannot turn noise into usage.
OpenLedger is early in a conversation that probably matters. That is the best compliment I can give it without pretending the hard part is solved.
Maybe the future of AI is not just bigger models. Maybe it is models with receipts. Intelligence with ownership trails. Agents that can show what shaped their decisions. Data contributors who do not vanish the second their work becomes useful.