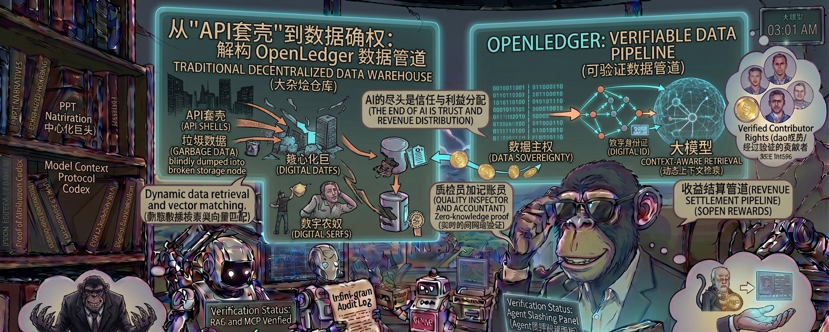
这几年在Web3底层协议里摸爬滚打,听够了那些动辄要重塑世界、颠覆一切的PPT。尤其是AI和Crypto结合的赛道,点进去十个有九个是“API套壳”。买几台显卡开个矿池,或者租个海外服务器接个开源模型,就敢管自己叫去中心化人工智能。把投资人当韭菜,把开发者当傻子。
所以我刚看到 @OpenLedger 的时候,第一反应也是直接划走。直到我翻完他们底层设计里关于**Verifiable Data Pipeline(可验证数据管道)**和**动态有向无环图(Dynamic DAG)**在数据溯源上的结合,我才觉得这帮人总算开始聊点真问题了。
币圈现在最缺的不是算力,也不是模型。算力可以靠堆钱解决,模型有各大厂在开源卷。现在真正的死穴是数据。高质量的数据快被大模型喂干了,而剩下的私域数据、垂直领域数据,谁也不敢轻易拿出来。凭什么我辛辛苦苦清洗、标注的高价值数据集,喂给AI之后,收益全被中心化巨头拿走,我连个水花都看不见?
$OPEN 想要解决的,就是这个“数据打工人”的困境。
通俗点说,以前的去中心化数据网络就像一个大杂烩仓库,大家把数据往里一扔,分布式存储就完事了。但AI训练不是收破烂。垃圾数据进去,出来的也是垃圾。OpenLedger做的事情,是在数据进入大模型之前,安插了一个“无感知的高级质检员加记账员”。
这里面有个很有意思、但之前很少被讨论的技术,叫做**时空上下文图谱数据流机制(Spatio-Temporal Contextual Graph Flow)**。
别被这个长名词吓到,用大白话翻译:这玩意就像给每一条数据发了一张“数字身份证”,而且这张身份证还是动态的。比如你贡献了一段关于加密货币交易的专业分析,这个机制不仅会记录你“说了什么”,还会记录你是在“什么时间节点”、“基于哪些前置市场信息”说出来的。
通过动态DAG的拓扑结构,这些数据被编织成一张网。大模型在调用你的数据时,不是盲目地抓取,而是顺着这张网的脉络去理解上下文。更重要的是,这个过程是高度隐私和可验证的。你不需要把自己的底层底牌全亮给对方,通过零知识证明的变体,网络就能确认你数据的真实性和含金量。
这就直接切中了AI训练的两个核心痛点:数据质量和数据确权。
吐槽归吐槽,现在的项目哪怕技术再硬,如果代币模型是一坨屎,最后也只能落个“起个大早赶个晚集”的下场。OpenLedger把代币和这个数据管道深度绑定。在这种设计下,数据不再是一锤子买卖。只要你贡献的数据在图谱中持续被大模型检索、调用、作为训练权重,你就能顺着那条“数据管道”不断获得奖励。这其实是用Crypto的经济学结构,在给AI时代的数字生产力做一次利益重新分配。
当然,作为老韭菜,我不会盲目吹捧。OpenLedger 现在的挑战依然巨大。动态DAG和图谱机制对节点的带宽和计算同步要求极高,怎么在完全去中心化的环境下保证这种高频数据流不卡顿,开发团队还有硬仗要打。如果后续工程落地变成“减速带”,那再漂亮的架构也是空中楼阁。
但这至少指明了一条务实的路径:AI的尽头不是无休止的机器竞赛,而是关于“信任”和“利益分配”的博弈。
往深了说,大模型越来越像一个被中心化巨头豢养的、无所不知的黑盒。我们每天在互联网上产生的每一句话、每一个行为,都在无偿地给这个黑盒提供养分,最终它再反过来变成信息茧房统治我们。这是一种新时代的数字雇佣兵体制。
技术不应该变成囚禁创造力的牢笼。通过这种数据管道的尝试,把数据的控制权和收益权从黑盒手里夺回来,让每个独立的个体重新拥有数字主权,这或许才是我们在代码世界里不断折腾的终极理由。