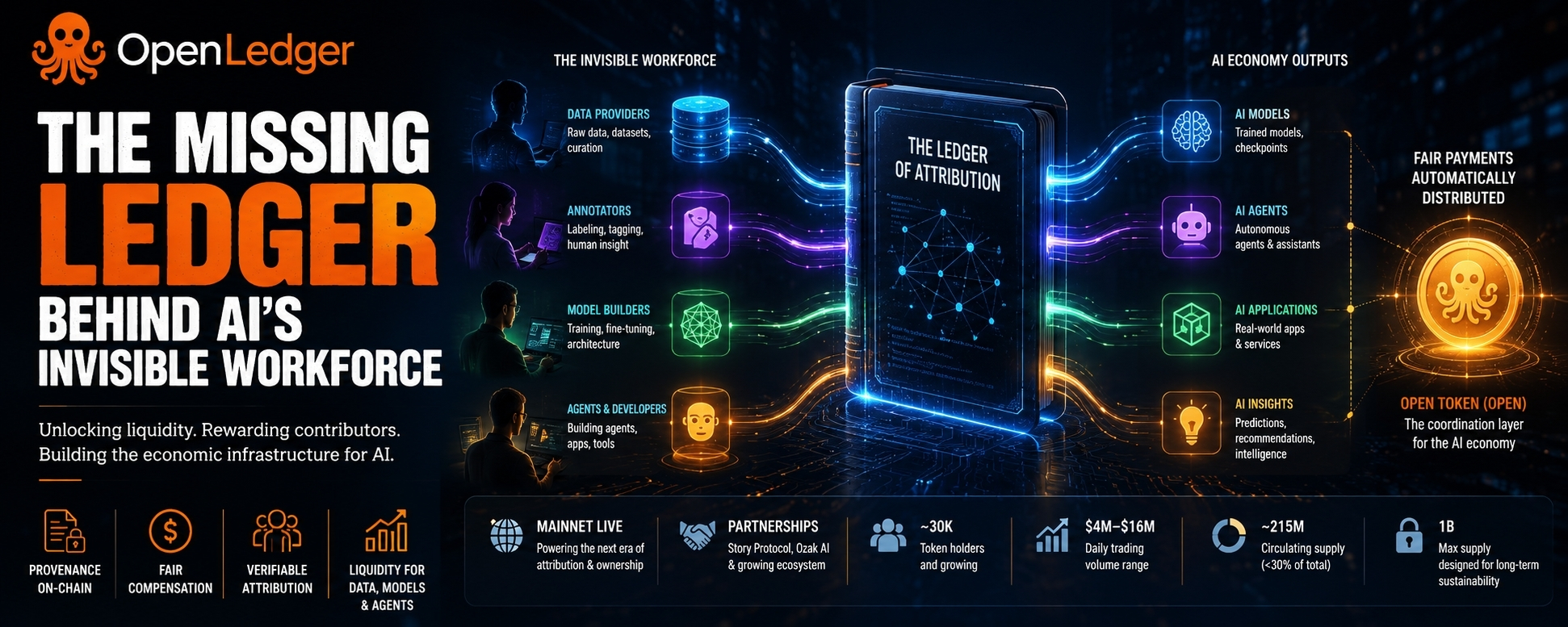
A useful way to think about OpenLedger is to forget, for a moment, that it is a blockchain project. Imagine instead that it is trying to solve a problem that has quietly followed the AI industry from the beginning: everyone talks about the models, but very few people talk about the ingredients. Data providers, niche experts, annotators, model creators, and increasingly autonomous agents all contribute pieces to the final product, yet once intelligence is produced, the trail often disappears. OpenLedger’s vision feels less like building another AI network and more like creating a ledger for the invisible supply chain behind intelligence itself.
That idea becomes more relevant today than it would have been two years ago. The AI conversation has changed. The industry is no longer obsessed solely with who has the largest model or the fastest inference speed. Questions about ownership, attribution, licensing, and compensation are becoming harder to ignore. Companies want proof of where data came from. Creators want proof that their work is not being absorbed into systems without recognition. Regulators are beginning to ask uncomfortable questions about transparency. In that environment, OpenLedger is betting that the future value of AI may not come only from generating intelligence, but from proving where intelligence originated.
The project’s recent evolution reflects that shift. The launch of its mainnet was important not simply because another blockchain went live, but because it moved the attribution concept from theory into infrastructure. Attribution is a nice idea when it exists in a whitepaper. It becomes economically meaningful when contributors can potentially be tracked, measured, and compensated automatically. That transition matters because systems that can account for value often become more durable than systems that merely create value.
Its collaboration with Story Protocol pushed this narrative even further. Most observers looked at the partnership and saw another integration announcement. The more interesting interpretation is that it hints at a future where AI training data, creative works, and model outputs may carry embedded economic rights. In other words, OpenLedger appears less interested in building another AI destination and more interested in becoming part of the financial plumbing that sits underneath AI ecosystems.
An analogy comes to mind. During the growth of global trade, shipping containers were not the glamorous part of the story. Consumers cared about products, not containers. Yet containers transformed commerce because they standardized movement and accountability. OpenLedger seems to be pursuing a similar role. The datasets, models, and agents may receive most of the attention, but standardized attribution could become the mechanism that allows those components to interact economically at scale.
Another analogy is that of a music royalty system. Most listeners focus on the song itself. Behind the scenes, however, there is an entire infrastructure that tracks who wrote the lyrics, who composed the melody, who owns publishing rights, and who receives payment when the music is played. OpenLedger appears to be attempting something similar for AI. The intelligence generated by a model may be the final song, but the network wants to track the contributors who made that outcome possible.
Looking at the numbers reveals why the project remains both intriguing and speculative. The token’s circulating supply remains well below total supply, meaning future unlock schedules will continue to influence market dynamics. Trading activity is relatively healthy compared with overall valuation, suggesting there is meaningful market interest. At the same time, the token has experienced a severe decline from peak levels, indicating that investors are no longer willing to reward AI narratives alone. The market is demanding evidence that real economic activity exists beneath the story.
This is where OpenLedger becomes different from many AI-related crypto projects. The central question is not whether AI will grow. That seems increasingly likely. The real question is whether attribution itself becomes a valuable service. If datasets, models, and agents begin generating measurable revenue that can be tracked and distributed through the network, then OpenLedger’s infrastructure could become increasingly important. If attribution remains an afterthought, the thesis becomes much weaker.
The token is essentially designed to act as a coordination layer among participants who would otherwise have competing interests. Data contributors want compensation. Model developers want access to resources. Application builders want usable infrastructure. Agents need mechanisms to transact. OpenLedger’s token economy attempts to connect these groups through a common accounting system. Whether that creates sustainable demand ultimately depends on how much activity occurs on the network rather than how much excitement exists around the narrative.
What many people miss is that OpenLedger may not actually be an AI bet in the traditional sense. The contrarian view is that it is a governance and compliance bet disguised as an AI project. The future winners of AI may not simply be the organizations that create intelligence most efficiently. They may be the organizations that can prove ownership, trace provenance, and distribute value fairly. If that future emerges, attribution layers could become as important as the models themselves.
There are still significant uncertainties. Adoption remains the largest challenge because attribution systems become powerful only when enough participants agree to use them. Competition is intense, with numerous projects pursuing marketplaces, agent frameworks, decentralized compute networks, and data economies. There is also the ongoing question of whether token demand can grow faster than supply expansion. These are not minor details; they sit at the center of the investment case.
For now, OpenLedger feels like a project operating slightly ahead of the market conversation. While much of the industry remains focused on generating intelligence, it is asking what happens after intelligence is generated. Who contributed? Who gets paid? Who owns the output? Those questions sound administrative today, but history often shows that infrastructure built around accountability becomes more valuable as ecosystems mature.
The story of OpenLedger is therefore less about AI becoming smarter and more about AI becoming accountable. If the next phase of artificial intelligence is defined by ownership, licensing, and economic coordination, then OpenLedger is attempting to build the record book that keeps score. Whether that record book becomes essential infrastructure or remains a niche experiment will depend on one simple thing: can it turn attribution into an economy rather than just a feature.
