

Something breaks early in the usual AI scaling story
Most AI systems look powerful from the outside. Big models, fast responses, clean APIs. But underneath, the structure is still simple: centralized compute, centralized control, centralized failure points.
OpenGradient moves in a different direction, but not in a “clean upgrade” way. It feels more like a re-routing of pressure inside the system — where computation, verification, and settlement stop living in the same place.
That shift is what the Hybrid AI Compute Architecture is really about.
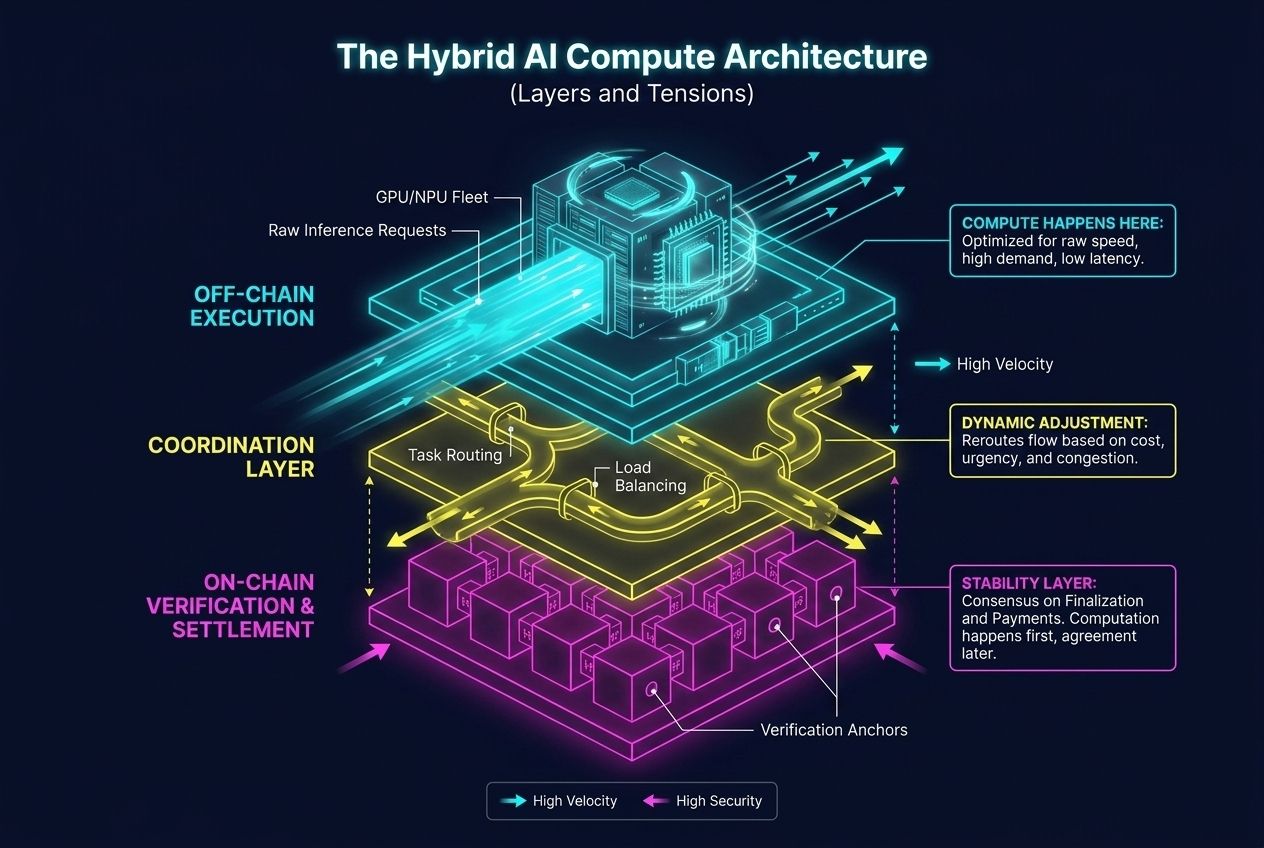
Hybrid AI Compute Architecture is not a single system — it’s a split behavior
Instead of treating AI execution as one pipeline, the architecture breaks it apart into uneven layers:
compute happens off-chain where speed matters
verification shifts into controlled checkpoints
coordination sits somewhere in between, constantly adjusting flow
But this separation is not stable. It changes depending on demand, task value, and verification intensity.
So what looks like architecture is actually behavior under load.
Sometimes it feels distributed. Sometimes it collapses back into tighter coordination when validation pressure increases.
That tension is important.
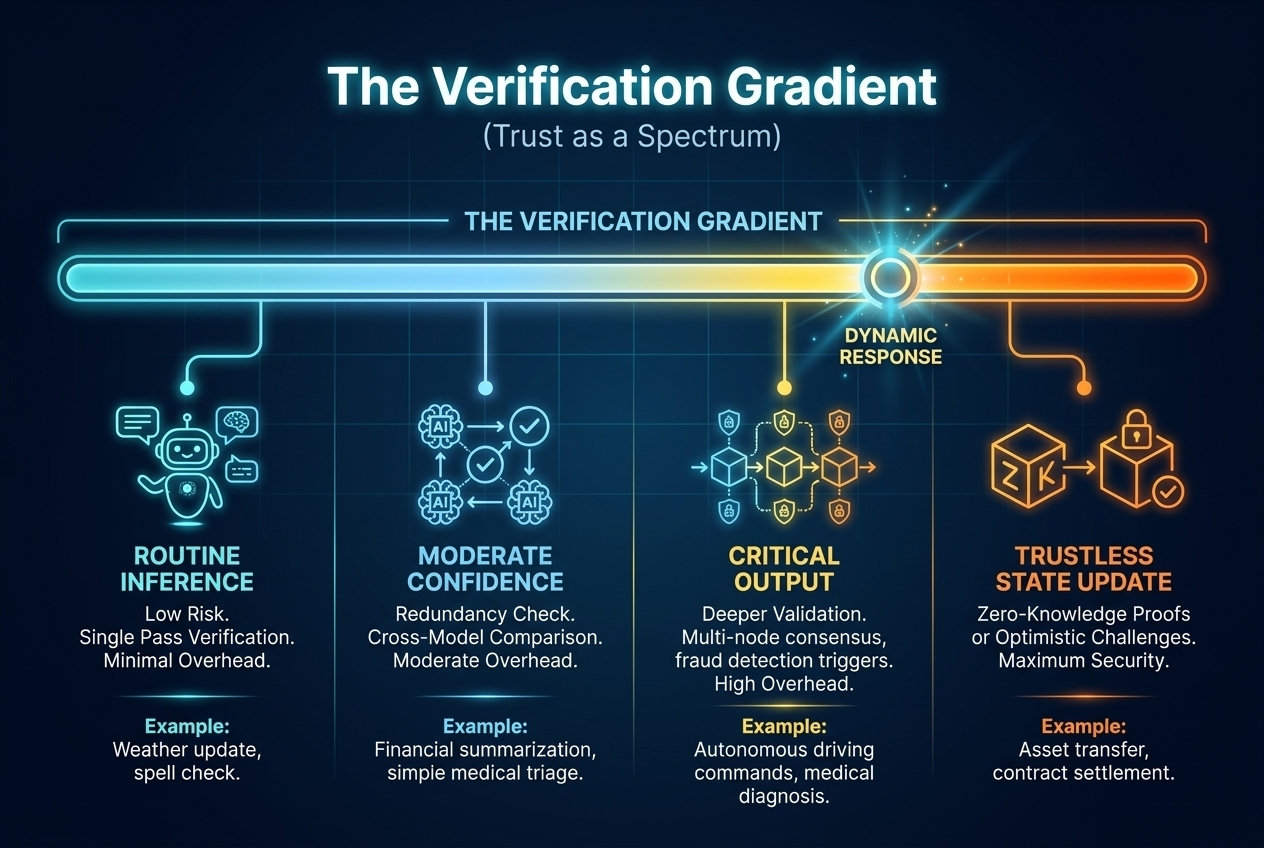
The real shift: trust stops being binary
Traditional systems assume a simple idea: either output is trusted or it is not.
OpenGradient doesn’t stay in that binary space. It introduces what is closer to a verification gradient, where trust is applied unevenly.
some outputs pass through lightly
some are double-checked through redundancy
some trigger deeper validation mechanisms when risk increases
But this isn’t a neat ladder. It behaves more like a sliding response system.
And that sliding behavior changes everything about how AI execution is priced, verified, and accepted.
Node roles are not fixed — they drift under demand
The network is described through node categories, but in practice the boundaries are not rigid.
compute nodes execute inference
verifier nodes check outputs
coordinator nodes route tasks
storage nodes hold memory and metadata
But under real workload pressure, these roles start to overlap. A compute node can behave like a verifier under certain conditions. A coordinator can start acting like a bottleneck filter.
It’s not a clean modular machine. It’s a shifting workload map.
That’s where scalability starts to appear — not from structure, but from redistribution.
Consensus is not about computation — it’s about settling reality
A key misunderstanding would be to treat consensus here as classical blockchain logic.
It isn’t.
Consensus mainly appears at two points:
when tasks are finalized
when payments are settled
Everything else happens off-chain, outside strict agreement mechanisms.
This separation creates speed, but also introduces something subtle: computation happens first, agreement happens later.
That ordering matters more than it looks.
x402 changes AI from access model to execution economy
One of the more direct shifts is the introduction of payment-gated inference.
Instead of subscription access or static API usage, computation becomes transactional:
request → payment verification → execution → output
It sounds simple, but the implication is deeper. AI stops behaving like a service and starts behaving like a metered system where every inference has economic weight.
This changes how demand flows through the network.
It also changes what “usage” means.
PIPE pushes AI closer to on-chain execution, but not fully
There is an attempt to connect machine learning execution with blockchain state through PIPE.
But it doesn’t fully merge the two worlds. Instead, it creates controlled interaction points where AI outputs can influence on-chain logic without fully living inside it.
That boundary is intentional.
If everything becomes fully on-chain, cost and speed collapse. If nothing connects, AI becomes isolated again.
PIPE sits in that unstable middle.
Model Hub is less marketplace, more routing layer
At first glance, it looks like a model marketplace.
But functionally, it behaves more like a routing decision system:
which model handles which request
how load is distributed
how inference cost is balanced
Users don’t just “choose models.” The system constantly negotiates model assignment behind the scenes.
That negotiation is invisible, but it defines performance.
MemSync changes the assumption that AI forgets
Persistent memory is not new as an idea, but the structure here is different.
MemSync introduces continuity across sessions, meaning AI behavior is no longer isolated per request.
That creates something subtle:
AI stops resetting after each interaction.
Instead, it accumulates state — selectively, not fully.
And selective memory is more powerful than full memory in distributed systems, because it avoids total data centralization.
Twin systems turn identity into executable objects
Digital twins are not just avatars here.
They behave more like operational entities:
persistent behavior profiles
reusable decision patterns
evolving interaction models
It becomes less about representation and more about persistence of behavior across environments.
But the open question is how stable these twins remain when underlying models change.
That part is still unresolved.
Token economics is not just incentive design — it is load shaping
The economic layer is not separate from compute. It actively shapes how computation flows.
When execution is tied to payment:
demand becomes self-regulating
high-cost inference gets filtered naturally
low-value compute does not overload the system
So token logic is not just financial. It becomes infrastructure pressure control.
What OpenGradient actually shifts (if you zoom out)
The surface story is decentralization.
But the deeper shift is different:
computation is fragmented instead of centralized
verification is probabilistic instead of absolute
execution is economically gated instead of freely accessible
memory is persistent but partial
None of these are fully new on their own. The change is in how they are combined.
Not a perfect system. A controlled imbalance system.
Closing thought
Hybrid AI compute doesn’t feel like a finished architecture.
It feels like a system learning how to distribute pressure without breaking under it.
OpenGradient sits inside that transition phase — where AI is no longer just about intelligence output, but about how computation is negotiated, verified, and paid for in motion.
Not stable. Not fully defined. But already structurally different from the systems that came before it.
@OpenGradient $OPG #OPG