

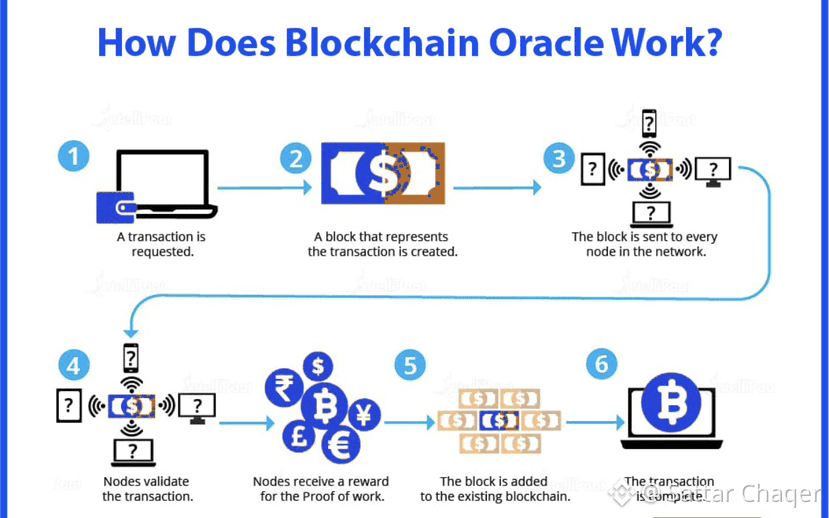
On-chain data is often treated as inherently trustworthy. If it exists, it is assumed usable. This assumption is one of the quiet failure points in decentralized systems.
Data can be available and still be wrong. It can be timely and still be misleading. Reliability requires context, verification, and redundancy.
APRO separates these concerns deliberately. Data is collected, validated, and distributed through distinct processes. This reduces correlation risk and prevents single-source failures from defining outcomes.
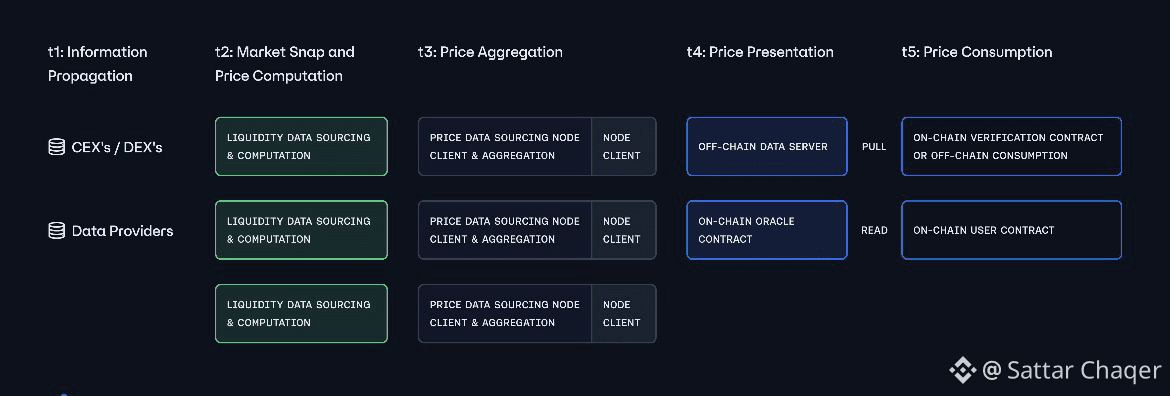
Reliability is not a feature that can be added later. It must be architectural. APRO reflects that discipline by treating data as infrastructure, not input.

