Most Web3 products do not fail loudly. They stay online. Pages load. Transactions appear successful. From the outside everything seems normal. Inside the system pressure starts forming very early. This pressure does not come from massive traffic. It comes from small uneven behavior that slowly changes how storage reacts. Walrus is built by focusing on this early phase where systems still look healthy but foundations are already shifting.
In the first weeks after launch traffic feels manageable. Requests arrive at a steady pace. Nodes respond quickly. Builders feel confident. As more users arrive behavior changes slightly. Certain data becomes more popular. Some reads repeat more often. A few nodes respond faster and start receiving more requests. Other nodes stay quiet. This imbalance feels harmless at first. Nothing breaks so no action is taken.
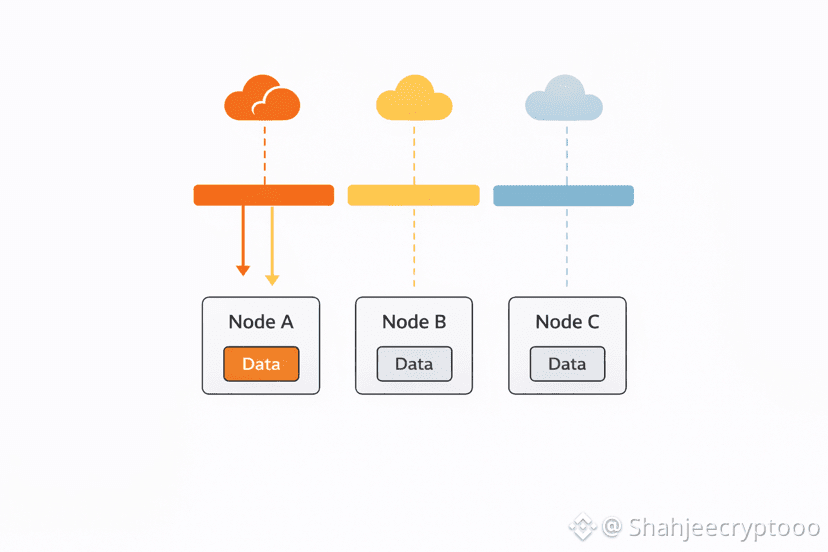
This early imbalance is dangerous because it trains systems into bad habits. Faster paths get reused again and again. Slower paths fall behind. Over time retries increase on the same routes. Storage begins amplifying stress instead of absorbing it. Walrus is designed to prevent this training effect. It spreads access pressure intentionally so no single path quietly becomes dominant.
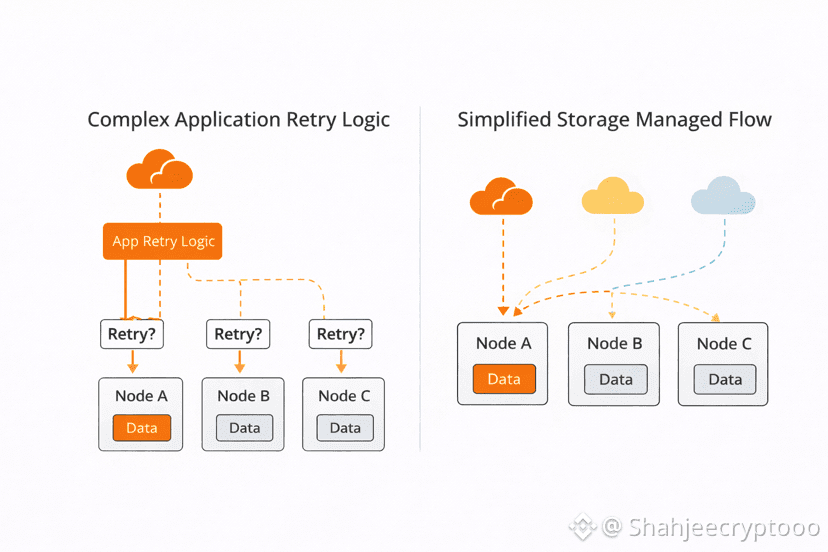
Retry behavior is another hidden contributor. When a request does not respond instantly systems retry. This looks like resilience but it often makes things worse. Retries usually hit the same stressed node. This doubles pressure without solving the cause. As usage grows retries multiply silently. Walrus treats retries as part of normal operation not as exceptions. It manages them inside the storage flow instead of leaving them to application logic.
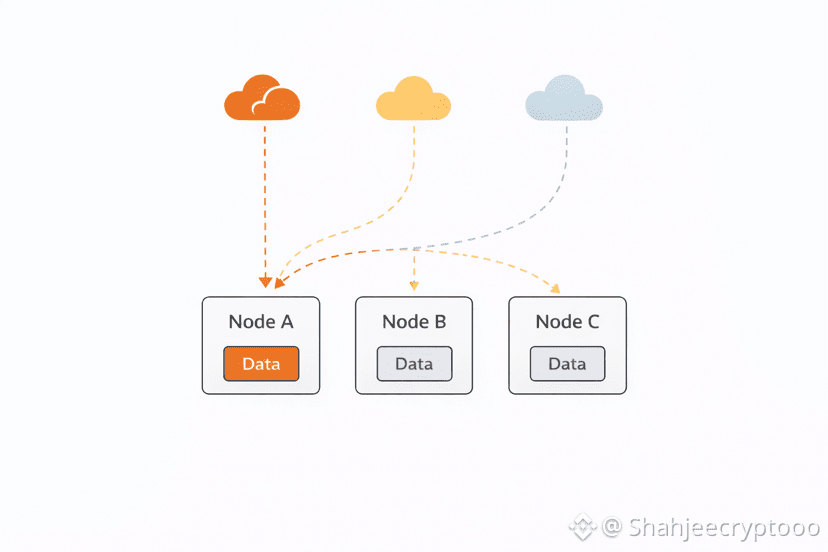
Most dashboards hide retry amplification. Metrics show more reads which teams interpret as growth. The real reason behind those reads stays unclear. Builders feel surprised when performance drops without obvious causes. Walrus reduces this confusion by keeping storage behavior predictable. Load grows in visible ways. Systems act consistently under pressure. This helps teams plan rather than react.
Cost pressure follows the same pattern. Each retry consumes bandwidth and resources. Expenses rise faster than user activity. Teams feel their product becoming expensive without understanding why. Walrus focuses on efficiency early. It avoids unnecessary operations so cost growth matches real usage. This protects long term sustainability instead of rewarding short bursts.
User experience is where these problems surface first. Pages hesitate. Content loads inconsistently. Buttons respond with slight delays. Users do not analyze metrics. They feel friction and leave. This is why storage design is not just infrastructure. It is product behavior. Walrus absorbs instability inside the system so users feel smooth interactions even when conditions are imperfect.
Developers also feel the impact. When storage is unpredictable teams write defensive code. Extra checks extra retries extra conditions. Complexity grows. Bugs increase. Maintenance slows. Walrus simplifies this by providing stable access patterns. Developers trust the storage layer and write cleaner logic. This reduces long term technical debt and burnout.
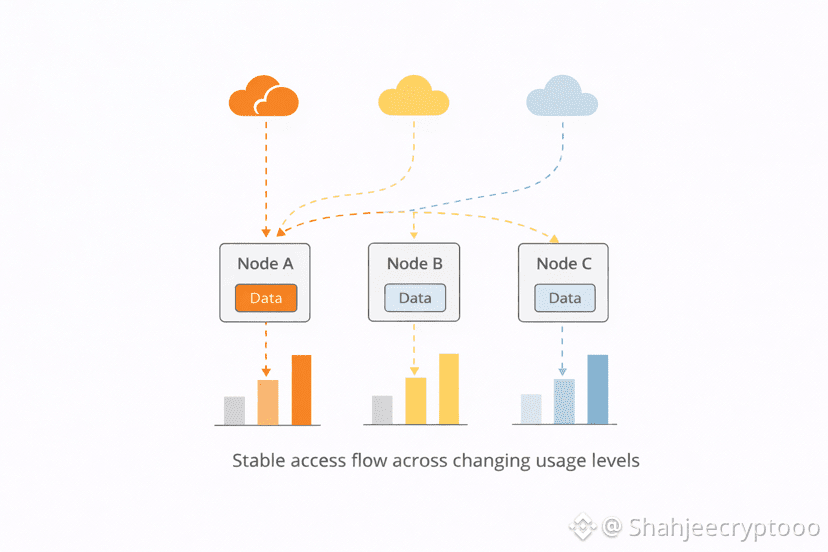
Another overlooked aspect is node fairness. In many systems a small group of nodes receives most of the load because they respond quickly. Over time they degrade or drop out. This harms network health. Walrus distributes access evenly. Nodes participate without fear of being overloaded unexpectedly. This creates a healthier environment where contributors stay long term.
Growth itself changes systems. What works at low usage may not work later. Walrus does not assume ideal conditions. It assumes constant change. Access patterns shift. Popular data changes. Network conditions vary. Storage remains steady through these changes. This resilience protects products during transitions not just at peak moments.
Many failures start small. A few delays. A few retries. Over months they become serious issues. Walrus focuses on stopping this growth early. By managing access pressure retry behavior cost efficiency and fairness it prevents small inefficiencies from becoming structural weaknesses.
$WAL aligns incentives around consistency and reliability. It supports participation that improves availability rather than exploiting temporary advantages. This shapes a network focused on long term health. Calm systems outperform chaotic ones over time.
Walrus is not built to impress during demos. It is built to survive normal usage where most products slowly lose quality. By focusing on early imbalance and quiet pressure it protects apps before damage becomes visible. Users may never know why things feel smooth. Builders will know because their systems continue working while others quietly struggle.