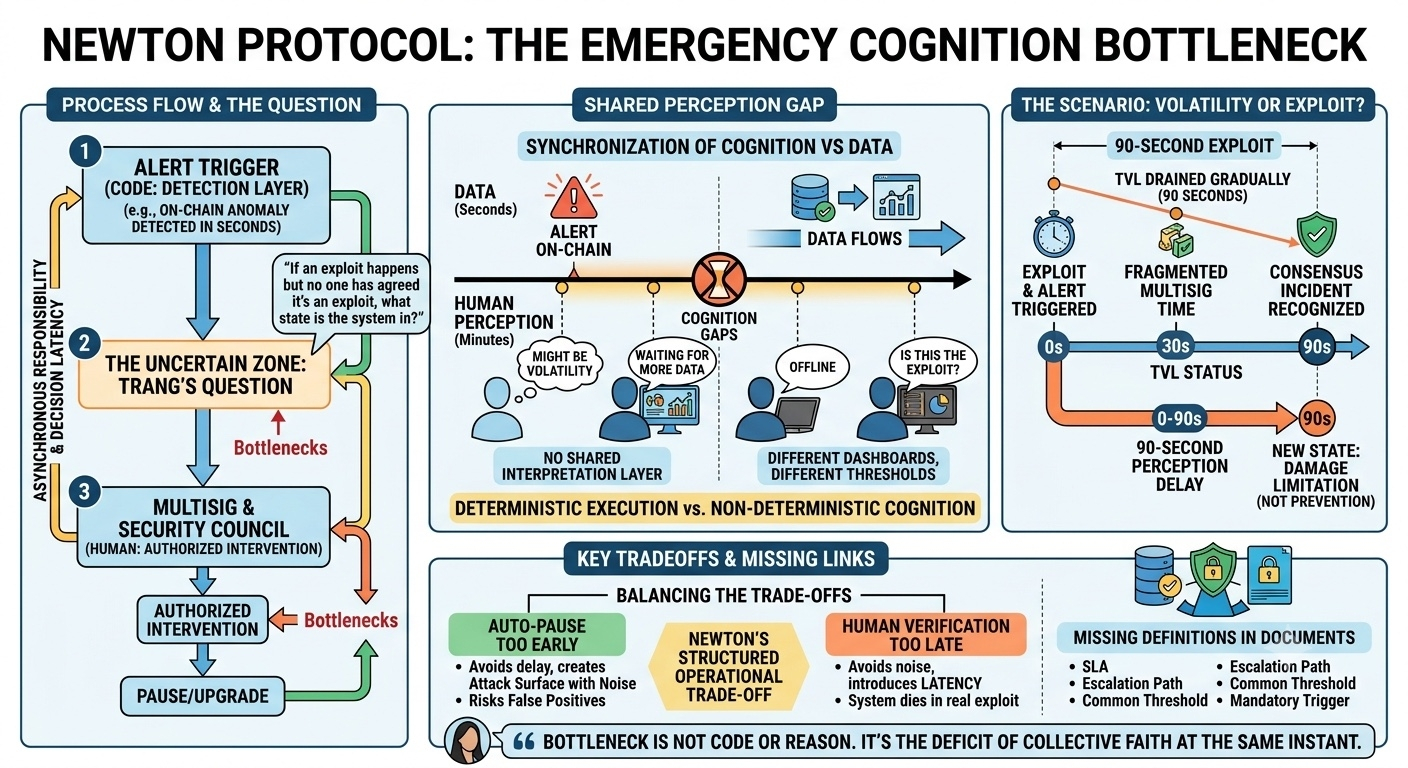
In the meeting on Tuesday, I don’t remember exactly who in the discussion started to change tone first. I just remember Trang staring at the screen longer than usual, then asking: “If an exploit occurs but no one has agreed it is an exploit yet, then what state is the system in?”
No one answered right away. Because the Newton Protocol doesn’t define that state in any layer. It only defines the permissions to act after a state has been recognized.
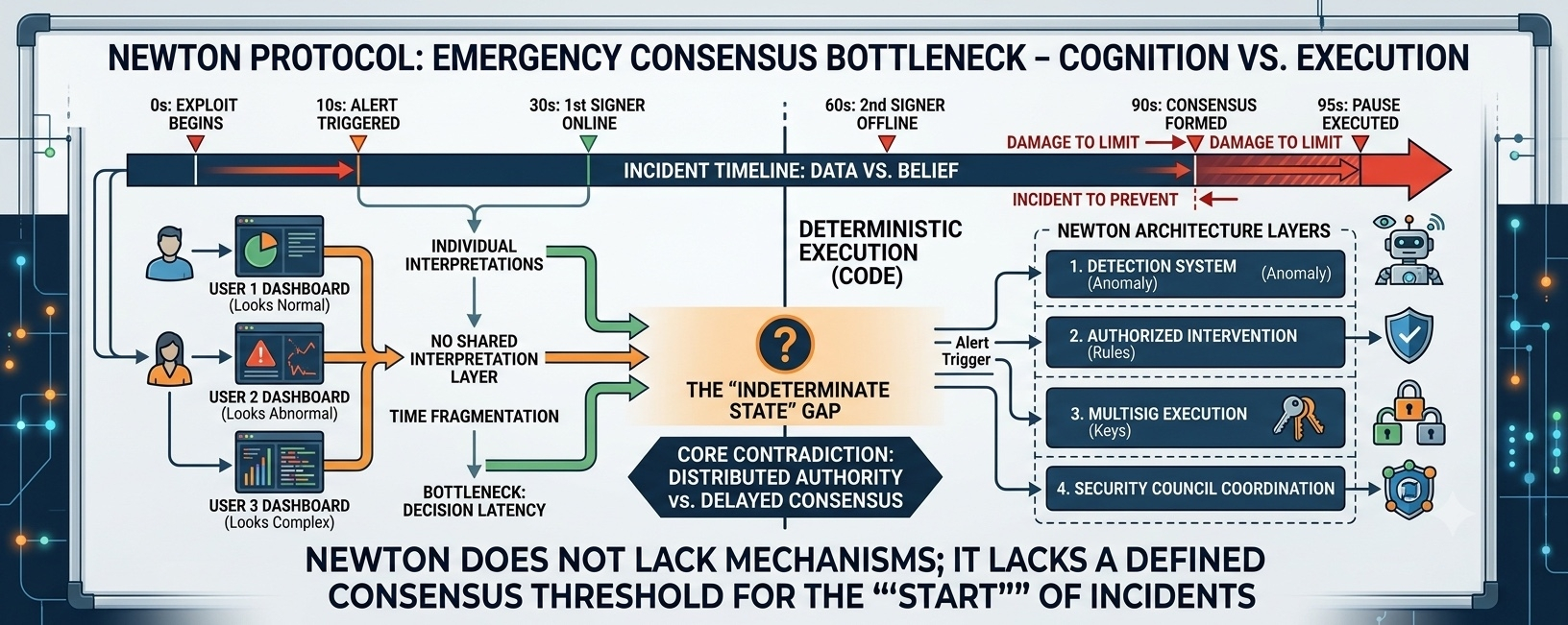
In Newton’s architecture, emergency response is spread across multiple layers: a detection system, multisig execution, and security council coordination. Each layer has a clear role, but none of them is responsible for defining the “starting point” of an incident.
This gap isn’t a lack of technical capability. It’s a lack of a consensus threshold in cognition. And in DeFi, cognition is always slower than data.
The page points to the “authorized intervention” section in the docs: core contributors and the security council have the power to pause or upgrade when anomalies are detected. Sounds complete, even safe. But the word “detection” isn’t anchored to any hard condition. There’s no SLA, no common threshold, no mandatory trigger. Only authority, no timing.
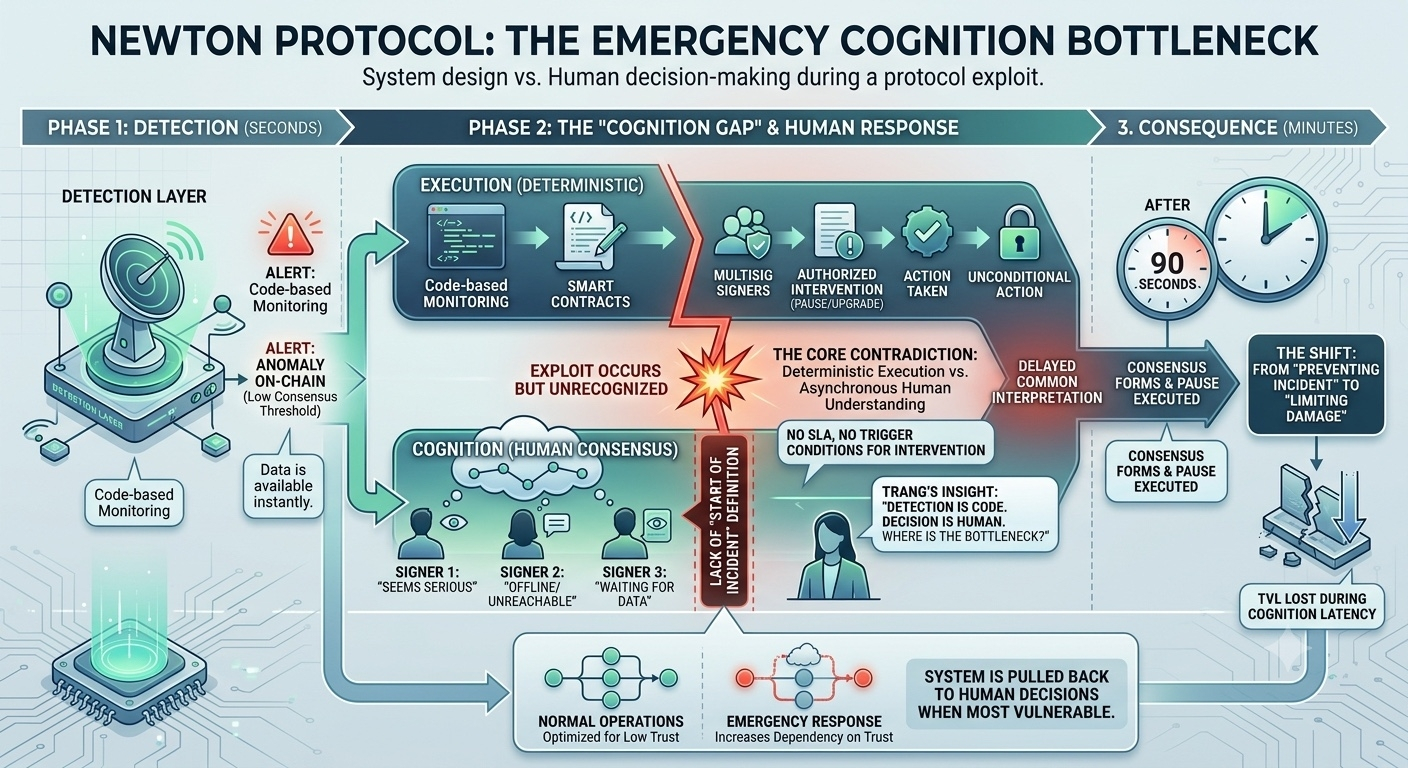
The detection layer can fire an alert within a few seconds when it sees an on-chain anomaly. But an alert isn’t a decision—it’s just an un-interpreted signal. After an alert, a chain of people must look at the data together and decide whether it’s volatility or an exploit.
One person, one dashboard. One person, one threshold. There is no shared interpretation layer in the first moment.
In Newton, the multisig is seen as the last safety layer before irreversible action occurs. But the multisig doesn’t only slow execution. It fragments the decision timeline.
One signer thinks it’s serious. Another isn’t sure. A third is offline. No one is wrong, but no shared action happens immediately.
I start to see the core contradiction clearly: execution in Newton is deterministic, but emergency cognition isn’t. The system is optimized to reduce trust in normal operations, but it increases dependence on trust when the system is under stress.
Not a small contradiction. This is where the system gets pulled toward humans at the most dangerous moment. The page says a line that derails the debate: “Detection is code. Decision is human. So where is the real bottleneck?”
There’s no clean answer. Because if you increase automation, the system is easily plagued by spam false positives to trigger a pause. If you increase human verification, the system dies by latency. Newton doesn’t choose one side. It keeps both—and turns the trade-off into an operating structure.
We try to build a more concrete scenario. An exploit occurs at a time when liquidity is high. A bot starts withdrawing assets in a few blocks. The monitoring system detects it almost immediately and fires an alert. But the alert is in the “could be volatility” zone and hasn’t crossed the auto-pause threshold yet.
One signer sees the alert but hasn’t signed. The second person is offline. The third is waiting for more verification data. No one is opposing action, but no action is being taken either.
During those 90 seconds, TVL begins to be gradually withdrawn. Not because the system didn’t detect it. But because the system hadn’t reached a consensus state that it was under attack yet. After 90 seconds, when consensus forms, the state has already changed.
No more “incidents to prevent.” Only “damage to limit.” The page goes quiet for a moment, then asks: “So what is the system optimizing—avoiding mistakes, or reacting quickly?” This question doesn’t have a fixed answer in Newton. And that’s why the system chooses not to take an extreme one-sided path.
Auto-pause too early creates an attack surface made of noise. Too much manual confirmation creates unacceptable latency for a real exploit.
The docs mention security council coordination, but there’s no SLA, no escalation path, and no definition of “who must respond first.” This creates flexibility in the design, but at the same time creates a gap in responsibility time. No one is wrong for reacting slowly. But the system doesn’t know how long is too long.
The page calls this “asynchronous responsibility.” I think it’s more accurate to say it’s a state where action authority is distributed, but time pressure is not. In a normal system, distributing authority is an advantage. In an incident, distributing time is a weakness.
I start to see Newton’s emergency system not as a pipeline, but as a process of synchronizing cognition. It isn’t the system deciding when there’s an incident. Instead, multiple people must simultaneously believe the incident is happening. And synchronizing belief always lags behind data.
The clearest analogy is an airport where radar automatically detects unfamiliar objects. The radar reports correctly, but the decision to close the runway doesn’t come from the radar.
It comes from multiple people confirming that the signal isn’t noise. In the first 30 seconds, no one is wrong. But if it’s a real exploit, those 30 seconds are enough to change the entire outcome. The most important point doesn’t lie in detection speed, but in the speed of reaching consensus on detection. And this is something that isn’t written in the Newton Protocol architecture diagram.
The page says one final sentence before the debate stops: “Maybe the problem isn’t who presses pause, but that the system doesn’t define when everyone has to start believing the same thing.” That sentence reaches no conclusion. But it clarifies the whole design: Newton isn’t missing emergency mechanisms. It’s missing a precise definition for the moment when many people begin to call the same occurrence an “incident.”