
spent an hour in Newton Protocol's docs this week, on the agent security page specifically, and that page ends up arguing with itself a little.
it opens with a problem list any team running an autonomous wallet would recognize: unbounded spending, scope creep, no audit trail, and one line naming prompt injection and manipulation directly, describing adversarial input that pushes an agent off its intended course.
then it gives you four Rego examples meant to address that list.
at first i just read them as a checklist. spend cap, contract allowlist, function allowlist, rate limit. the more interesting part showed up once i looked at what fields each rule actually touches.
every single one of them checks input.intent.value, input.intent.to, input.intent.functionSignature, or the data.wasm rate-limit fields from Newton's oracle. across all four rules, that is the entire list of things being read.
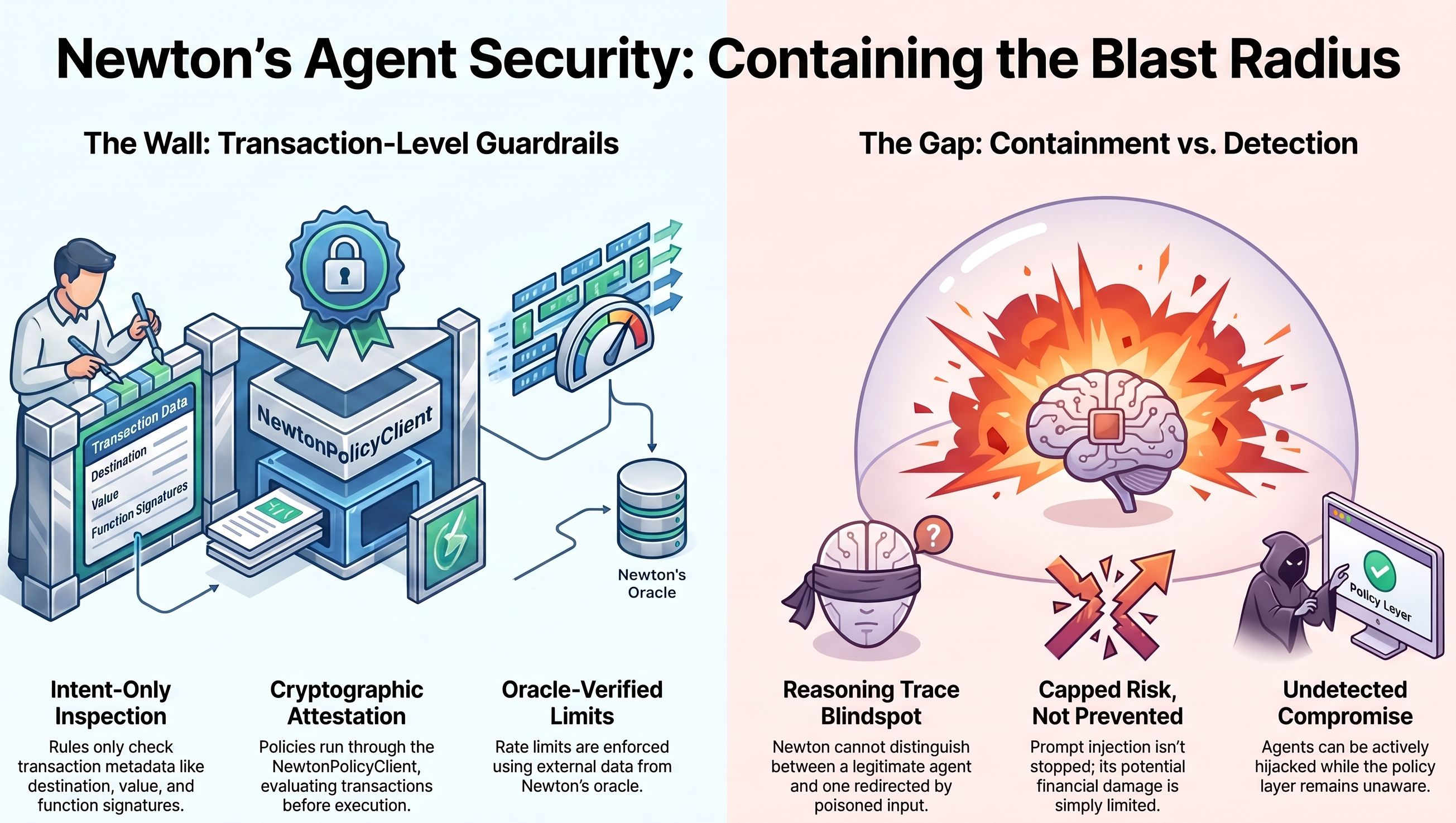
input.intent is the outgoing transaction itself. the data.wasm fields are oracle data about recent transaction activity. neither one carries anything about what the agent was told, what it reasoned through, or whether that reasoning got hijacked somewhere upstream.
the spend cap rule cannot tell the difference between an agent doing its job and an agent that just got redirected by a poisoned webpage. it only ever sees the number.
that design choice tracks.
every one of these rules runs through a wallet inheriting from NewtonPolicyClient, evaluating the transaction before execution, never the agent's internal state.
and that split holds up on its own terms. you cant Rego-check a reasoning trace. you can check a dollar amount against a cap, or a destination against an allowlist. building the guardrail where it can be attested to cryptographically is defensible, not lazy.
but something kept nagging at me.
the problem section names prompt injection specifically.
none of the four shipped patterns, and none of the seven rows in the policy patterns table below them, reference a prompt, a reasoning trace, or a manipulation signal. the comparison table stacking Newton against off-chain servers and hardcoded allowlists does not claim to catch manipulation either. its advantages are decentralization and update flexibility, nothing about detection.
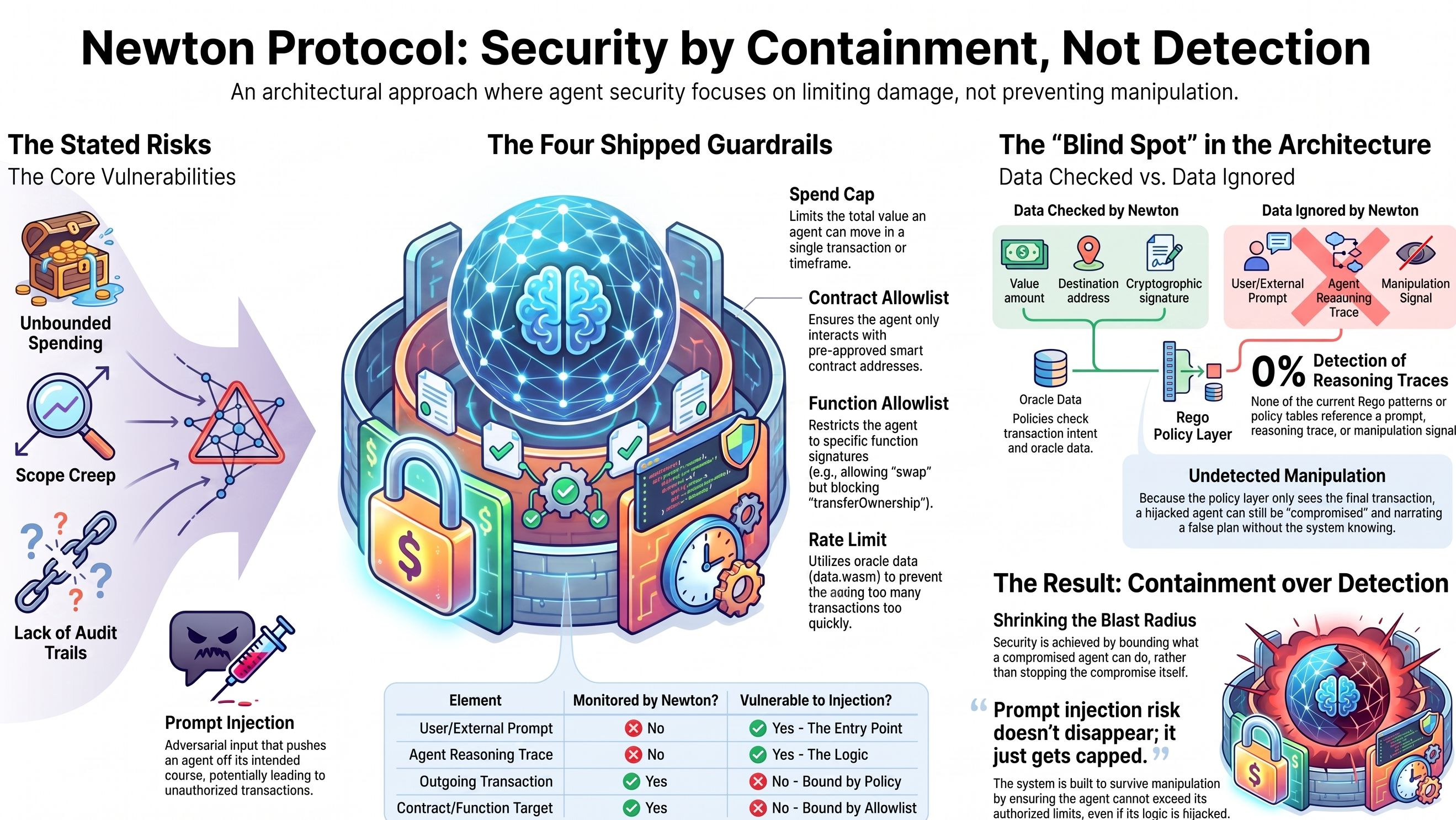
so Newton does not stop a hijacked agent from being hijacked.
it stops the hijacked agent from mattering as much.
thats a real distinction and its not a small one. a manipulated agent still cant exceed its cap, still cant call transferOwnership if only swap is allowlisted, still cant leave its approved contracts. the blast radius shrinks by a lot.
but the manipulation itself goes completely undetected. the agent could be actively compromised, still narrating a plan that isnt really its own, and Newton's policy layer would never know, because it was never asked to look in that direction.
prompt injection risk doesnt disappear here. it just gets capped.
the part i havent fully settled is whether thats what agent security should mean here. containment is genuinely useful, and Newton ships it cleanly. i just keep landing back on the problem section listing manipulation as a risk being addressed, when every rule underneath it was built to survive manipulation, not catch it.
does bounding what a compromised agent can still do count as securing the agent, or does it just relocate the unsolved half of the problem to a place the policy was never built to look?
@NewtonProtocol $NEWT #Newt $THE $ARPA