Azu wrote that the phrase 'support 40+ chains' is most prone to failure, not because of its truthfulness, but because it resembles a hollow poster slogan: readers will nod after reading it, then forget it the next second. If you want to write APRO's 'multi-chain resume' in a way that is not empty, the key is to break down 'multi-chain' into three verifiable items: exactly which chains it can be used on, what services can actually be used on these chains, and whether the evidence I provide can be clicked through to verify against the contract address or data. Once the content shifts from a slogan to a checklist and evidence, it transforms from 'promotion' to 'usable information,' making readers more willing to share.

First, clarify the most common confusion: multi-chain is not one dimension, at least two dimensions are superimposed. One is 'network coverage/integration scope', such as some public information using 'supporting 40+ public chains, 1400+ data feeds' to describe ecological expansion; the other is 'the range of services that are online and directly callable', such as APRO's documentation states very specifically: currently providing 161 Price Feed services, covering 15 major chain networks, and the Data Service is divided into Data Push and Data Pull models. When writing a resume, make sure not to mix these two types of numbers into a mush, otherwise readers will think you are playing word games. The most stable way to write is to align them in the same sentence: for example, 'the ecological integration dimension emphasizes 40+ chains and a larger scale of data supply; while the directly connectable price feed is given in the document side with a verifiable list of 15 mainnet and 161 feeds', which immediately increases credibility.

Then there is the matter of 'which chains', don't just make up a list of mainstream chain names, the best evidence is actually on the APRO contract documentation page. Its Price Feed Contract page directly presents the Supported Chains, and under each chain, it provides specific trading pairs, deviation thresholds, heartbeat frequencies, and contract addresses; this kind of information is the hardest 'resume attachment', because readers can directly check the address on the chain. When you write about multi-chain coverage, you can turn 'supporting 40+ chains' into 'the price feed contract has provided verifiable entry points on these chains', and conveniently remind readers: don't just look at the promotional page, check the contract table, that's where the resume's ID card is.

Furthermore, the second trick to make the resume 'not empty' is to upgrade 'supporting many chains' into 'supporting different data forms on different chains', which is what you said: price feeds, PoR, AI data should not be mixed. For example, PoR (Proof of Reserves) has its own page in the APRO documentation and clearly states that the currently supported chain range includes Bitlayer, Ethereum, BNB Smart Chain, Plume, and lists specific PoR contract addresses; this means when you write 'APRO does RWA/PoR', it's best to clarify 'where PoR can be used directly on which chains' instead of just saying 'we also support PoR'. Similarly, the Runes price feed is also listed separately in the documentation, directly showing the related pairs and contract addresses on Bitlayer; NFT price feeds are provided on the BNB Smart Chain with specific pairs for BTC's price feed and contract addresses. When these pieces of information are put together, your 'multi-chain resume' will naturally develop a sense of hierarchy: it's not 'I do everything', but 'I have implemented different data products on different networks to verifiable contract layers'.
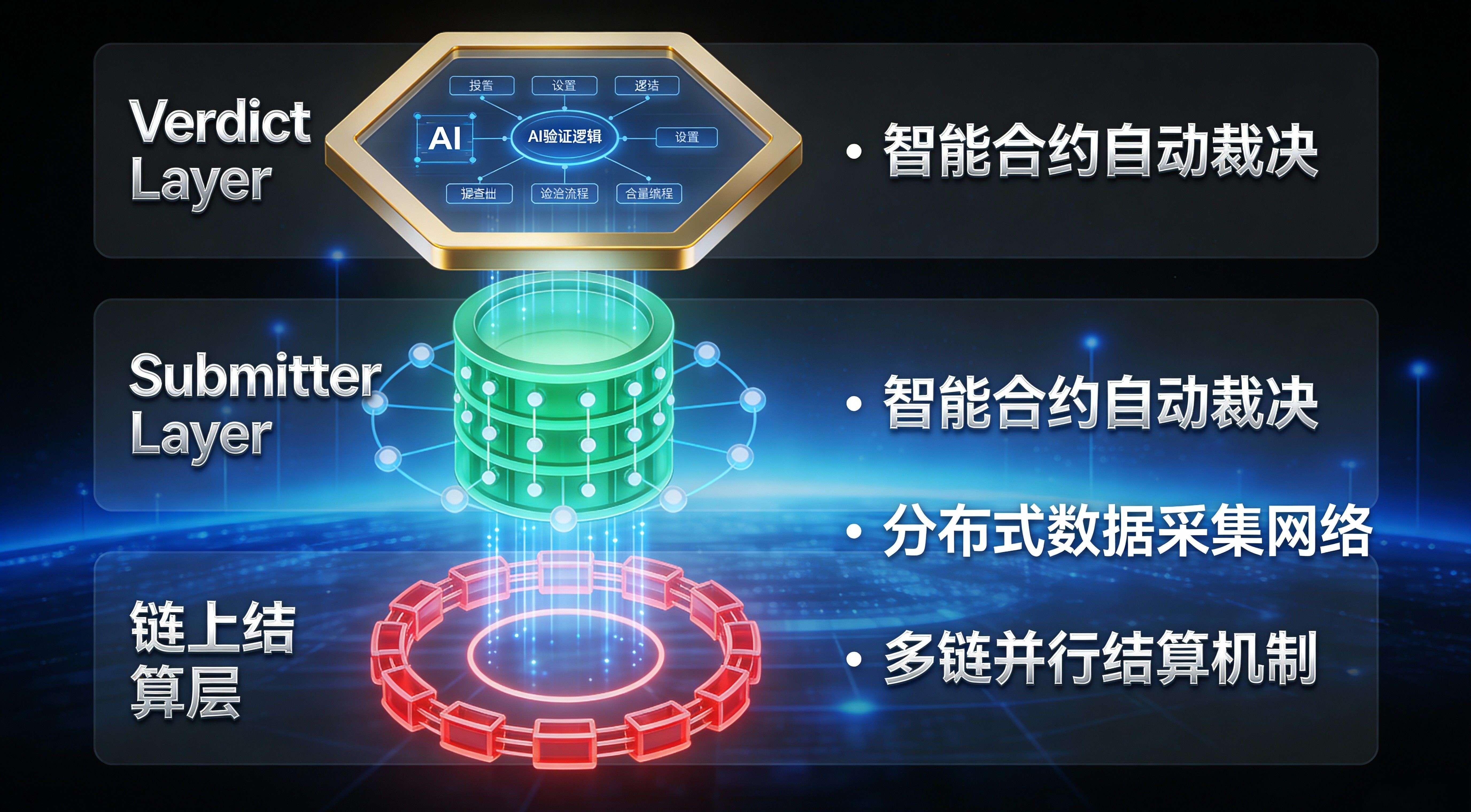
This also corresponds to today's rule change: content standards are shifting from 'slogan narrative' to 'list and evidence narrative'. Previously, when writing about oracles, everyone liked to compare 'faster, more accurate, more decentralized'; now writing about multi-chain, readers want to know 'can I actually use it on the chain you care about, which ones can I use, and where are the entry points'. The reason APRO is suitable for this writing style is that its structure inherently emphasizes the combination of 'off-chain processing + on-chain verification', and explains the network layers very clearly: the Verdict Layer uses LLM agents to handle conflicts, the Submitter Layer handles submission and verification, and finally, the on-chain settlement layer delivers to applications. Once you write the resume in the way of 'chain type + service type + evidence link', you are essentially translating its architectural narrative into 'a list language usable by developers'.

The impact on readers is very tangible: the judgment of APRO's real coverage will become faster, and may not even require too much technical understanding. Previously, readers had to rely on impressions to distinguish 'is this another project riding on multiple chains', but now that you have produced a 'chain list + scenario breakdown', they can come to a conclusion after just a glance: do I use the chain; is my business price feeding, PoR, or more focused on AI/unstructured data; can I directly click to see contract addresses and corresponding information. The document clearly outlines the two paths of Data Push / Data Pull, and also reminds readers: high-frequency scenarios like trading/derivatives care more about on-demand pulling and low latency; APRO's Data Pull is aimed at this; while more general price feeding and multi-asset coverage can be checked from the contract table of Data Push.



