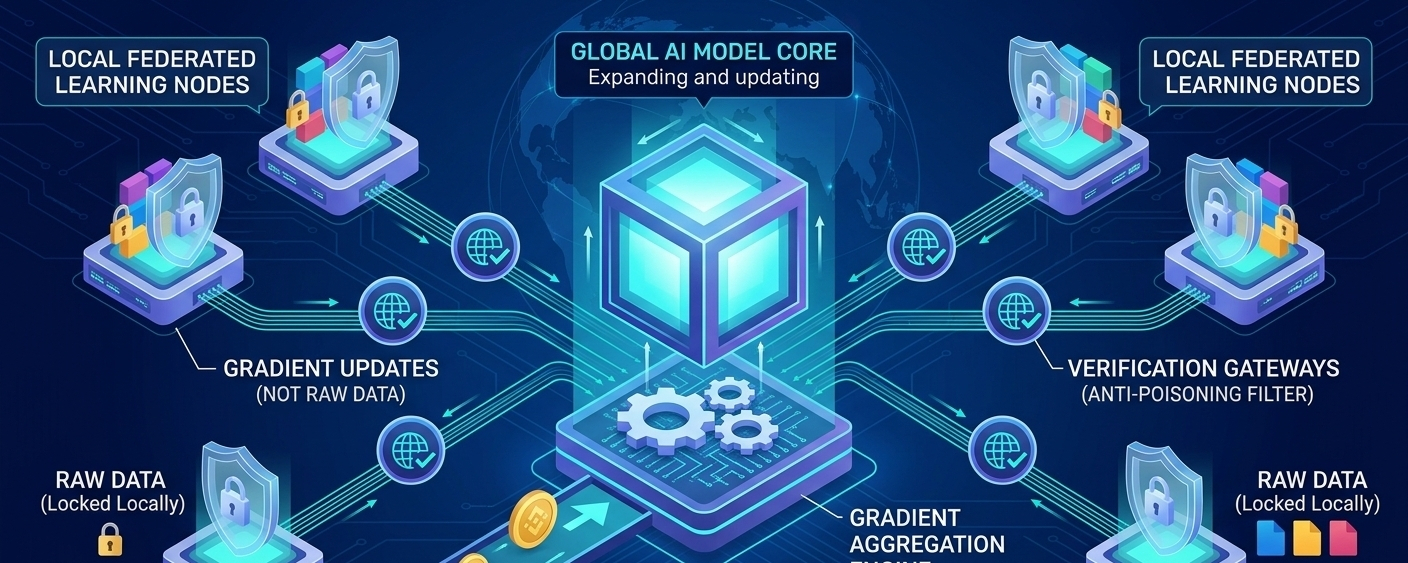
In the evolution of decentralized AI ecosystems, the core challenge in distributed machine learning (Distributed ML) is how to collaboratively train a large model with globally dispersed compute nodes without centralizing raw data. Traditional network architectures often suffer from bandwidth limitations, node dropouts (Stragglers), and data heterogeneity (Non-IID), leading to very low synchronization efficiency in distributed training. Evaluating the tech foundation of @OpenLedger reveals that the introduction of 'federated learning' and 'local gradient aggregation' mechanisms provides a viable engineering solution for large-scale node collaborative training.
From the perspective of the operational logic of the distributed architecture, $OPEN the network is changing the path through which data and models flow. Under this architecture, the global foundational model (Global Model) is distributed to each independent edge or data node. Each node performs local training using its own private dataset. After training is completed, the node does not need to upload large volumes of original data that also involves privacy concerns; it only needs to submit to the network the "gradient updates (Gradients)" or changes in parameter weights generated by the training.
The engineering challenge of this design lies in the "aggregation stage." #OpenLedger Using its decentralized validation matrix, it adopts an efficient asynchronous gradient aggregation algorithm. Validation nodes in the network will mathematically weight and calibrate the gradients coming from tens of thousands of nodes worldwide, exclude potentially malicious poisoning data (Malicious Gradient Attacks), and then merge the correct gradients to update the global model on the main chain. This approach not only significantly relieves the network bandwidth burden, but also ensures the precision of model iteration.
Moreover, the commercial value of this mechanism lies in achieving efficient decoupling between compute power and data. Through an automated attribution engine, the network can accurately record the contribution ratio of the gradients uploaded by each node to the convergence of the global model. This means that regardless of whether it is the research and development team providing the core algorithm, the end users contributing local data, or the validation nodes participating in gradient verification, all can receive compensation that is fully equivalent to their engineering contributions within a layered architecture.
In summary, competition in decentralized AI has shifted from mere storage to in-depth distributed computation and collaborative processing. When a network can securely and efficiently organize heterogeneous nodes worldwide to conduct federated learning and gradient calibration, it has the underlying capability to withstand centralized supercomputing centers. This underlying network—solving real training bottlenecks with precise cryptography and distributed engineering, and driving the evolution of an open-source AI ecosystem—clearly presents fundamental factual evidence that is more worth long-term, objective, rational tracking by industry observers.