
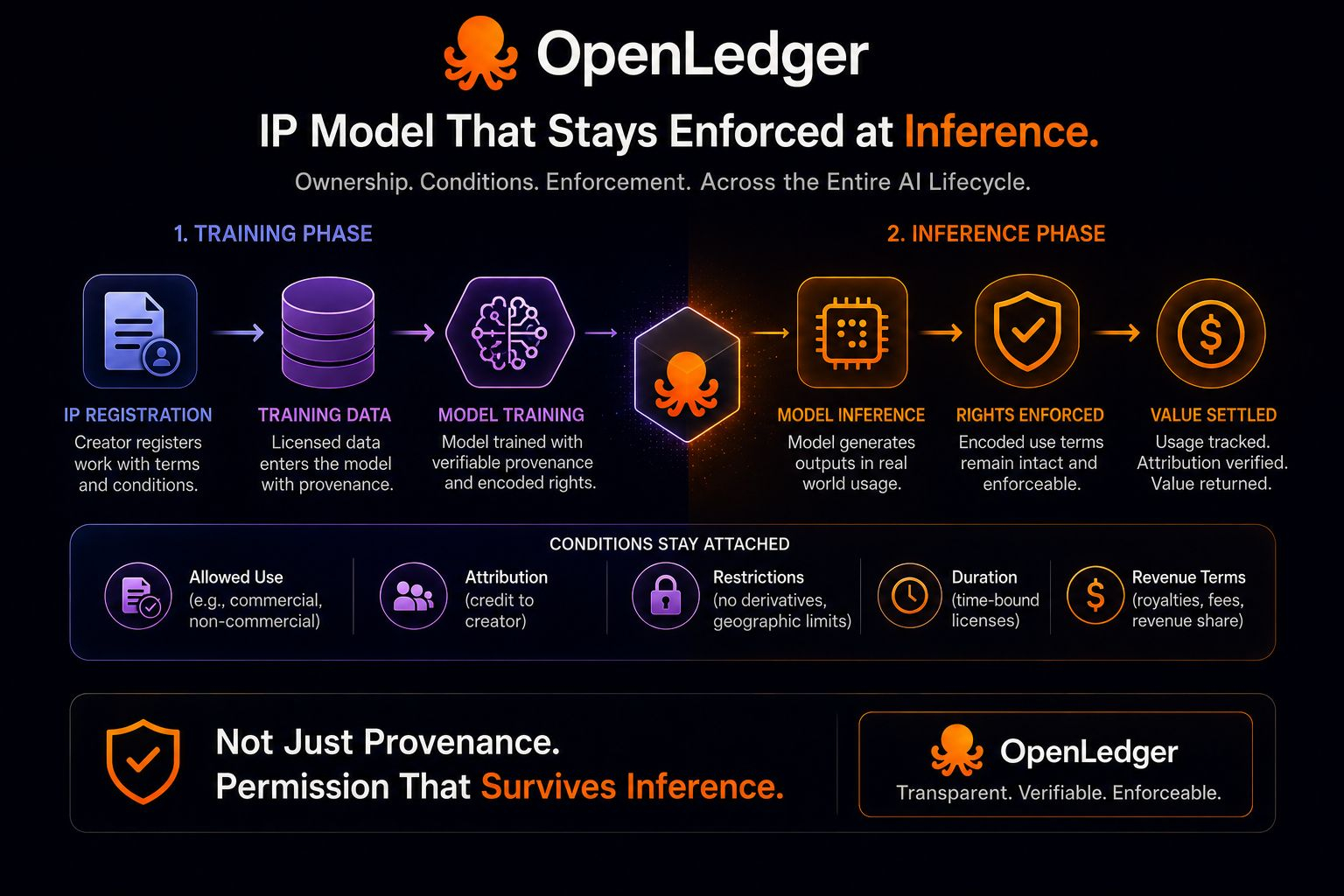
The first time I read about OpenLedger’s IP infrastructure, I thought the main point was provenance.
Training data, models, and intellectual property entering AI systems with ownership attached instead of disappearing into opaque pipelines afterward. Honestly, that already sounded useful on its own. A creator could at least prove where something entered the route and under what condition it became available.
At first I treated that entry point as the hard part.
If ownership stays visible at the beginning, if the asset carries readable provenance before training starts, then the system already feels more accountable than most AI pipelines today. The work doesn’t begin as anonymous input anymore.
But then I stopped at the part about encoding allowed use across both training and inference.
That changed the way I looked at the whole thing.
Because training is only one stage where permission matters. The more difficult moment arrives later, when the model is actually being used. Inference is where outputs get generated, decisions get made, value gets created, and where the original conditions attached to a work either remain meaningful or quietly fade into the background.
That’s where OpenLedger’s claim becomes much bigger than registration infrastructure.
A clean provenance record at entry is useful, but it does not fully solve the coordination problem by itself. A rights holder may allow their work into a system under specific conditions, but if those conditions become unreadable once the model begins operating, then the important part of the permission path breaks exactly where the economic activity starts happening.
And OpenLedger’s wording matters here because it explicitly extends the logic beyond provenance alone. The integration isn’t described only as ownership tracking around training data and models. It describes allowed use remaining encoded across training and inference together.
That means the inference stage is not some extra issue added afterward.
It’s the actual pressure test for whether the permission structure survives once the model enters real usage.
The more I sat with that idea, the more OpenLedger stopped feeling like a simple registration layer to me and started feeling more like an attempt to make AI permission flows stay legible after deployment instead of only before it.
And honestly, that’s probably a much harder infrastructure problem than most people realize at first glance.