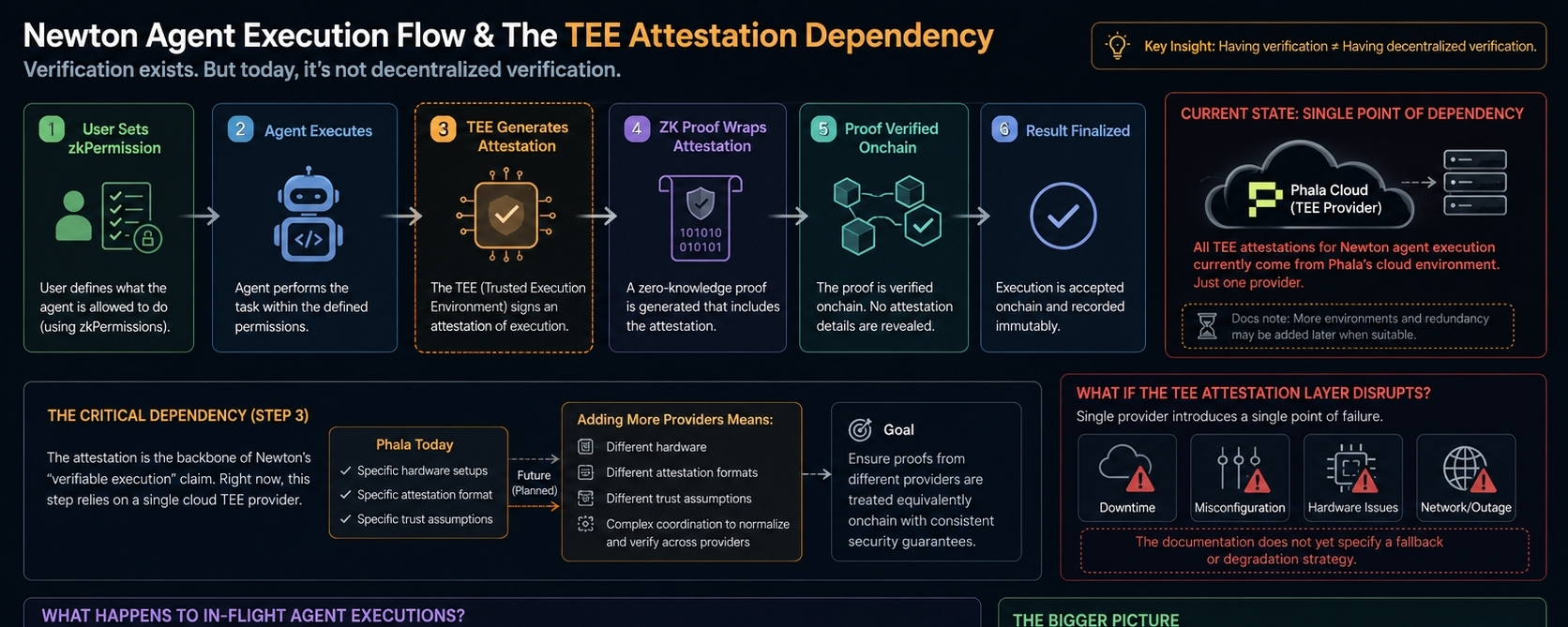
I was casually reading through Newton’s TEE documentation today — not testing anything, just exploring — when one line caught my attention.
It mentioned that TEE attestation for agent execution currently runs through Phala’s cloud environment. Just one provider. The docs add that more environments and redundancy may be added later when suitable.
At first, I thought: fair enough. It’s still in mainnet beta, so a single provider isn’t surprising. Controlled rollout, fewer variables.
But that explanation felt a bit too convenient.
Because TEE attestation isn’t just a small technical detail — it’s the backbone of Newton’s whole “verifiable execution” claim. When the protocol says an agent executed correctly within a user’s permissions, that proof ultimately comes from the TEE attestation. And right now, that path depends on one provider.
So the real question isn’t about whether Phala is reliable or not. It’s about what “verifiable” actually means when the verification layer itself has a single point of dependency.
I realized I had been mixing up two ideas:
having verification ≠ having decentralized verification.
They sound similar, but they’re not the same.
If you look at the full flow, it’s more complex than it first appears:
A user sets a zkPermission → an agent executes → a TEE generates an attestation → a ZK proof wraps that attestation → the proof is verified onchain.
Each step needs to work. But the attestation step — right in the middle — currently relies on one cloud TEE provider.
So what happens if that layer has issues? Downtime, misconfiguration, anything unexpected? The documentation doesn’t really explain a fallback yet.
The word that keeps sticking with me is “redundancy.” They mentioned it themselves, which suggests they’re aware this is a gap. What’s unclear is how long that gap exists — and what the user experience looks like if something goes wrong before it’s addressed.
There’s another layer to this that’s harder to reason about. TEE attestation is tied to hardware. Phala uses specific hardware setups. If Newton adds more providers in the future, those will likely involve different hardware, different attestation formats, maybe even slightly different trust assumptions.
Bringing all of that together — making sure a proof based on one provider’s attestation is treated the same as another’s — isn’t simple. It’s a coordination challenge.
I think what this really exposed for me is a pattern in how I interpret systems. Earlier this week, I made a bad trade partly because I assumed “audited” meant “fully live and redundant.” Different situation, same mistake.
I tend to treat the existence of a system as if it’s already operationally complete.
And that’s not always true.
What I still can’t fully figure out from the outside is this:
If the TEE attestation layer gets disrupted during high activity, what happens to in-flight agent executions?
Do they pause? Fail? Retry? Or just hang until the system recovers?
Right now, that part feels like a black box.
