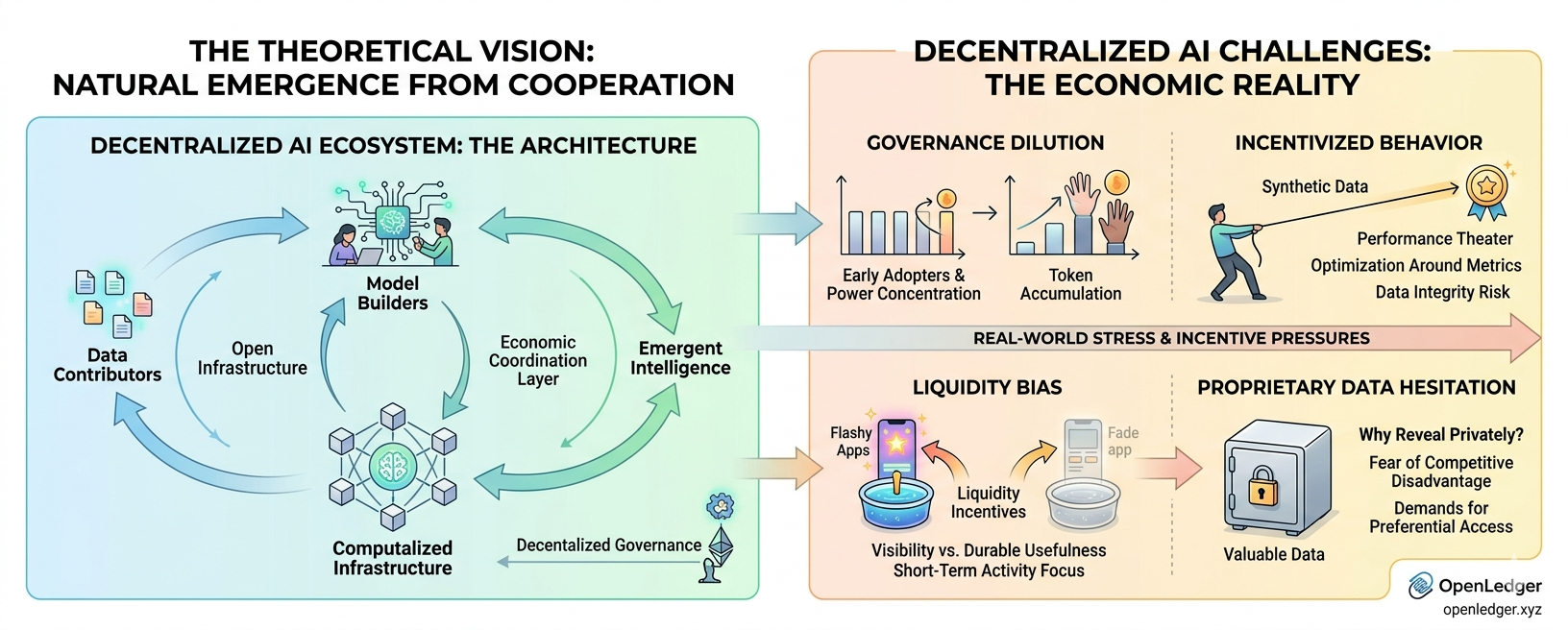

Sigo notando que la mayoría de los sistemas de IA descentralizados dependen silenciosamente de una suposición muy optimista: si suficientes personas participan abiertamente, una mejor inteligencia de alguna manera surge naturalmente de la red. Entiendo la lógica detrás de eso, pero no estoy seguro de que la historia de la coordinación humana realmente respalde esa conclusión.
Esa tensión es parte de por qué he estado dedicando más tiempo a pensar en OpenLedger.
La arquitectura en sí es interesante. OpenLedger está tratando de crear una capa de coordinación económica para la IA, donde los conjuntos de datos, modelos y agentes interactúan a través de una infraestructura compartida en lugar de permanecer atrapados dentro de plataformas centralizadas. La idea tiene sentido estructuralmente. Los contribuyentes de datos, constructores de modelos y participantes de infraestructura se convierten en partes visibles del mismo ecosistema en lugar de dependencias ocultas por debajo de él.
Pero una vez que los incentivos se vuelven medibles, el comportamiento cambia.
Por ejemplo, la descentralización de la gobernanza suena limpia al principio, sin embargo, la mayoría de los sistemas basados en tokens gradualmente acumulan influencia alrededor de los primeros participantes que ya entienden el sistema mejor que los que entran después. La concentración de influencia no siempre aparece a través del control directo. A veces surge a través de la familiaridad, ventajas de coordinación o simplemente estando lo suficientemente temprano como para darle forma a las normas antes de que todos los demás lleguen.
Luego está la cuestión empresarial que no puedo resolver completamente.
¿Por qué las empresas contribuirían con conjuntos de datos propietarios genuinamente valiosos en una infraestructura abierta sin esperar eventualmente acceso preferencial, apalancamiento en la gobernanza o privilegios invisibles? La participación abierta suena justa hasta que la información estratégica se vuelve económicamente significativa. En ese punto, la neutralidad se vuelve difícil de mantener.
El intento del protocolo de verificar la autenticidad de los datos del mundo real a gran escala también se siente más complicado de lo que la gente admite casualmente. La integridad de los datos no es solo un tema técnico. Se convierte en un comportamiento muy rápido. Si la participación está incentivada, la presión de contribución sintética inevitablemente aparece en algún lugar del sistema. Los humanos han estado optimizando métricas mucho antes de que los agentes de IA entraran en la escena. Industrializamos el teatro de rendimiento hace décadas.
Otra cosa en la que sigo pensando es si los incentivos de liquidez distorsionan sutilmente lo que se construye. Las aplicaciones que generan actividad medible pueden terminar recibiendo una atención desproporcionada incluso si no están produciendo utilidad duradera. Los sistemas a menudo recompensan la visibilidad antes que la utilidad porque la visibilidad es más fácil de cuantificar.
Y, honestamente, todavía me pregunto por qué los contribuyentes revelarían conjuntos de datos de nicho de alto valor públicamente en lugar de extraer ventajas en privado primero. Los ecosistemas abiertos dependen en gran medida de suposiciones cooperativas que sobreviven al contacto con la realidad económica.
El estrés del mundo real probablemente exponga estas tensiones rápidamente. Ciclos de adopción más lentos, intentos de manipulación de datos, fatiga de gobernanza o presión empresarial podrían remodelar gradualmente el ecosistema sin que ocurra un colapso dramático en absoluto.
Esa es la parte que encuentro más interesante.
No se trata de si OpenLedger funciona perfectamente, sino de si los sistemas de IA descentralizados pueden mantenerse significativamente abiertos una vez que la inteligencia misma se vuelva estratégicamente económica.@OpenLedger
