Hay algo raro sucediendo en la IA en este momento.
Todo se siente poderoso. Suave. Casi demasiado suave.
Tú lanzas algo, y responde. Ajustas un modelo, y mejora. Conectas herramientas, y se convierte en un agente. Fácil. Limpio. Un poco sospechoso si es que realmente has construido sistemas antes.
¿Y debajo de todo eso? Un desorden silencioso que nadie quiere nombrar completamente.
Los datos entran. El valor sale. Y en algún lugar en el medio… la atribución desaparece.
Simplemente desaparece.
Esa es la parte que me sigue molestando.
OpenLedger básicamente está tratando de poner un libro mayor donde nadie lo pidió. No porque esté de moda. Más bien porque la ausencia de eso ya está comenzando a doler.
Y sí, sé cómo suena eso. Otro pitch de 'IA x cripto'. He puesto los ojos en blanco en suficientes de esos ya.
Pero aún.
La Prueba de Atribución es engañosamente simple.
Rastrear qué datos realmente dieron forma a la salida de un modelo. No solo usados. No solo sentados en un conjunto de datos en algún lugar. Sino influyentes de manera significativa.
Pausa en eso.
Porque si eso funciona aunque sea parcialmente, toda la textura de la IA cambia.
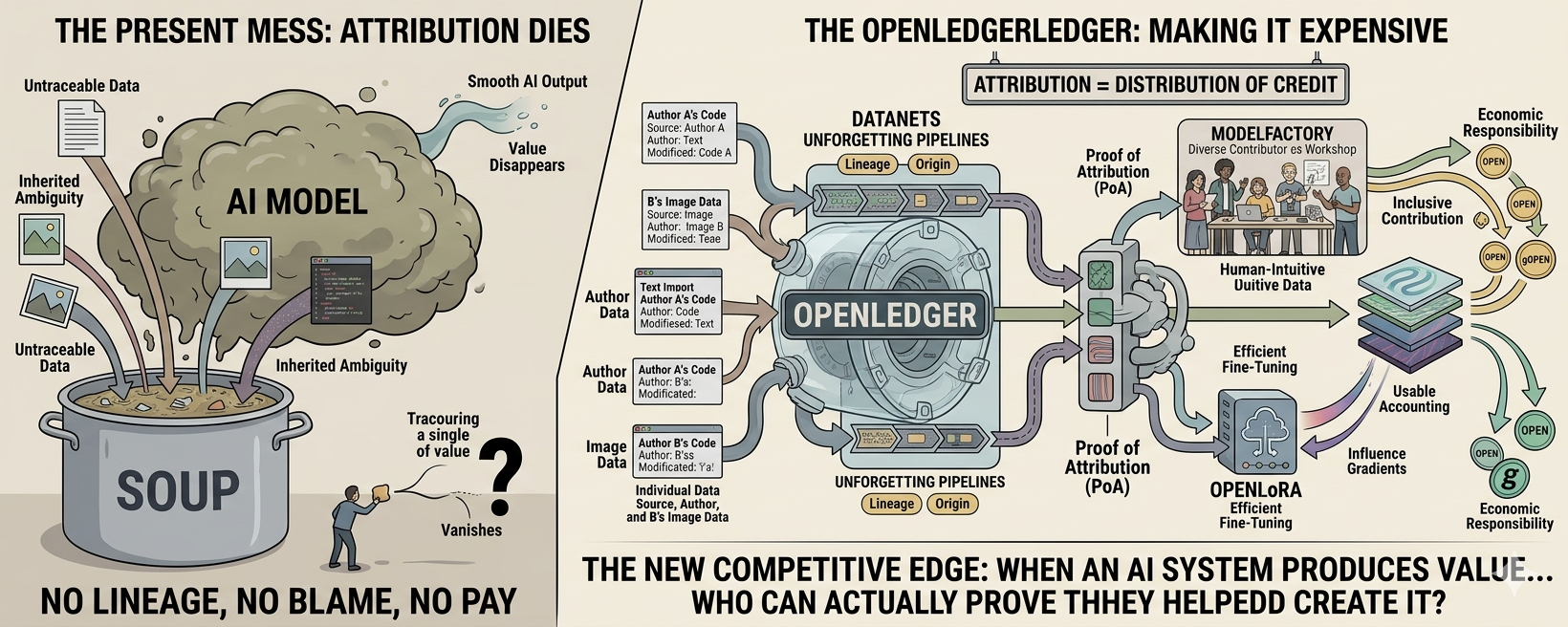
Ahora mismo, los conjuntos de datos son como ingredientes arrojados en una olla. Obtienes sopa. Genial. ¿Quién contribuyó la sal? ¿El caldo? No tengo idea. Nadie recuerda.
La Prueba de Atribución básicamente dice: deberíamos recordar.
Y, más incómodamente, deberíamos pagar por recordar.
Se siente obvio. También se siente como un problema.
Los datanets suenan como infraestructura que nadie quiere pensar.
Pero importan más de lo que deberían.
Piensa en tuberías que se niegan a olvidar. Cada transformación, cada paso, cada aumento — etiquetado y encadenado de vuelta al origen.
Y ahí es donde la realidad se vuelve complicada.
Porque una vez que comienzas a rastrear el linaje correctamente, te das cuenta de cuánto de la IA moderna está construida sobre ambigüedad heredada. No fraude. No malicia. Solo capas de transformación donde el origen se difumina a propósito o por accidente.
Los datanets intentan hacer que esa borrosidad sea cara.
O al menos visible.
OpenLoRA y ModelFactory son las partes que la gente subestima.
A simple vista, parecen herramientas. Relleno de infraestructura. Fácil de ignorar.
Pero OpenLoRA importa porque los sistemas de atribución mueren si el ajuste fino es caro. Si cada actualización cuesta demasiado en computación, nadie participa a gran escala.
ModelFactory es más interesante.
Asume algo que la mayoría de los sistemas ignoran silenciosamente: no todos los que contribuyen valor son técnicos. Algunas personas entienden mejor los datos que el código. Algunos están simplemente más cerca del problema.
Así que les das una forma de entrar. No perfecto. Solo usable.
Eso es menos elegancia. Más instinto de supervivencia.
Luego está la capa de token — OPEN y gOPEN — donde las cosas dejan de ser técnicas y comienzan a ser políticas.
Porque una vez que la atribución existe, incluso imperfectamente, la gobernanza se convierte en distribución de crédito.
¿Quién recibe recompensas por la salida del modelo?
¿Quién decide el peso de la contribución?
¿Quién escribe las reglas que definen los datos 'útiles'?
De eso es de lo que se trata esto. No tokenomics. Asignación de crédito a gran escala.
Y sigo pensando en lo rápido que la gente argumentará una vez que ese crédito se vuelva visible. Lo harán. Garantizado.
Ahora, aquí está la parte que no se siente cómoda.
La IA hoy está obsesionada con el rendimiento. Inferencia más rápida. Computación más barata. Modelos más grandes. Todo bien.
Pero casi nadie quiere enfrentarse a la pregunta más difícil:
¿Quién es responsable de lo que el modelo aprendió?
No moralmente. Económicamente.
La atribución en redes neuronales no es limpia. Es probabilística, entrelazada, ruidosa. No obtienes cadenas causales ordenadas. Obtienes gradientes de influencia y aproximaciones.
Así que la contabilidad perfecta es una fantasía.
Pero una contabilidad usable? Eso es suficiente para construir sistemas.
Y tal vez ese sea el verdadero punto.
No creo que esta sea una idea terminada. Ni siquiera cerca.
Creo que es un intento de arrastrar la responsabilidad a un espacio que históricamente la ha evitado muy bien.
Y eventualmente, la evasión deja de funcionar cuando el dinero escala.
Las filtraciones se vuelven visibles. Y las filtraciones visibles se parchean.
No porque sea elegante. Porque duele.
Y sigo volviendo a esto.
La próxima ola de IA no se definirá por quién tiene el modelo más inteligente.
Esa parte ya se está deslizando hacia territorio de mercancía.
Se definirá por algo más incómodo.
Cuando un sistema de IA produce valor...
¿quién puede demostrar que ayudó a crearlo?
\u003cm-67/\u003e\u003ct-68/\u003e\u003cc-69/\u003e
