Quiero cambiar la mentalidad de la mayoría de las personas en cuanto a cuál es la propuesta de valor principal de OpenLedger.
El tema de la historia común es la equidad. Pagar a los contribuyentes de datos. Democratizar la IA. Pagar a las personas que crearon los modelos.
Eso es real, y importa.
Pero siento que pasa por alto el tema más importante (económico) que OpenLedger tiene como solución.
No es compensación de datos. Desbloqueo de datos.
Aquí está el problema de datos del que nadie está hablando lo suficientemente claro.
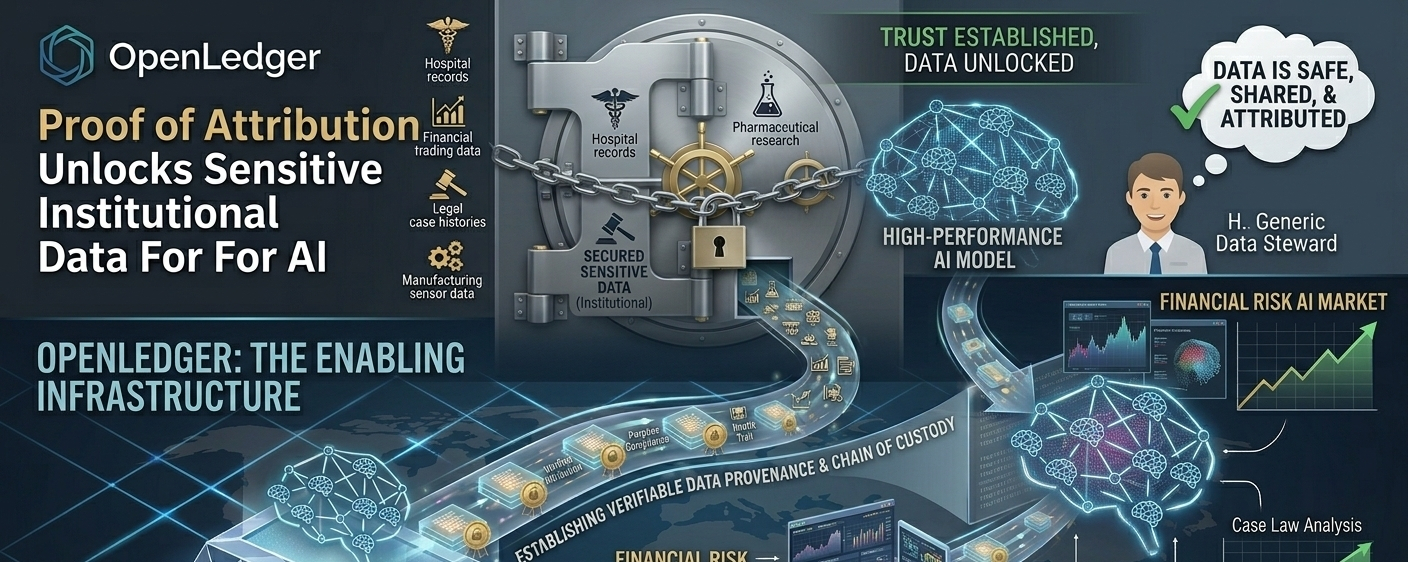
La mejor información de entrenamiento en el mundo no está en la web.
Es donde los sistemas hospitalarios no pueden compartir registros de pacientes sin romper la HIPAA. Está en bases de datos de investigación farmacéutica, bajo acuerdos de confidencialidad. Está almacenado en instituciones financieras, que tienen décadas de datos de trading propietarios. Tiene que estar en firmas legales donde los historiales de casos le darían a la IA un razonamiento legal que sería un cambio revolucionario. Está en plantas de manufactura donde los datos de sensores llevarían el mantenimiento predictivo a un nuevo nivel.
Estos datos existen. Son genuinamente valiosos. Los sistemas que entrenan sobre ellos serían significativamente más poderosos que aquellos entrenados con datos disponibles públicamente en internet.
Prácticamente ninguno de ellos puede ser utilizado para el entrenamiento de IA.
No debido a restricciones técnicas. Debido a problemas de confianza.
Si el hospital comparte información del paciente, no pueden asegurar lo que realmente sucederá con la información después de ser compartida. Pero nadie puede probar que es atribuible a la compañía farmacéutica y sobre quién puede ejercer control en cuanto al uso posterior. La institución financiera no podrá proporcionar datos de trading ya que no podrá mantener las rutas de auditoría adecuadas requeridas por los reguladores.
No son problemas técnicos. Estos son problemas de calidad y trazabilidad.
¿Quién usó estos datos? ¿Con qué propósito? ¿Podemos probarlo? ¿Podemos auditarlo? ¿Hay alguna forma de hacerlo disponible bajo ciertas condiciones?
Los datos permanecen inaccesibles si no se conocen las respuestas a esas preguntas.
Aquí es donde la infraestructura de OpenLedger llama la atención de todos de una manera interesante, más allá de solo 'pagar a los contribuyentes de manera justa'.
La Prueba de Atribución no solo crea rieles de pago. Produce un linaje de datos que puede ser verificado.
Cada conjunto de datos añadido a una Datanet incluye un registro criptográfico de su origen, su uso y su contribución a la salida de los modelos. Se registra en la cadena, fuera de la base de datos de cualquier organización individual y puede ser auditado por cualquier parte que tenga acceso a los registros.
Para el hospital que está pensando en contribuir con información de pacientes desidentificados, esta es una cadena de custodia que garantizará que la información pueda ser legalmente rastreada hasta la contribución del hospital.
Esa es evidencia de atribución para la compañía farmacéutica que sirve para proteger la investigación propietaria.
Ese es el papeleo regulatorio que permite a la institución financiera usar IA.
Esto desbloquea un mercado que es mucho más grande que el mercado de compensación a los contribuyentes individuales de datos.
La próxima frontera de mejora en la capacidad de IA son los datos empresariales, los datos cerrados, de alto valor y específicos de dominio que existen en sistemas institucionales.
Las organizaciones que tienen esos datos no los están reteniendo por alguna negativa a participar. Muchas personas realmente quieren. Los están reteniendo porque no tienen la confianza, el origen y la auditoría que necesitan para un intercambio de datos responsable.
La infraestructura podría ser la clave que encaja en esta cerradura.
Quiero ser claro sobre lo que esto significa.
La adopción de infraestructura basada en blockchain es lenta en la empresa. Los procesos de adquisición tienen una larga duración. Se realiza una gran cantidad de revisión legal.
Pero hay algo de gallina y huevo al respecto. La infraestructura a gran escala es una prueba en la que las instituciones se integran. El valor de la infraestructura se demuestra por la extensión de la integración de suficientes instituciones.
Para romper este ciclo, hay una de dos opciones: un adoptador temprano de gran nombre dispuesto a dar el primer paso o presión regulatoria que haga que el costo de no adoptar una nueva infraestructura sea mayor.
Ambos son progresivos. Ambos siguen faltando.
Sin embargo, no puedo sacarme esto de la mente.
Cuando la gente comenzó a compartir información a través de internet, su potencial no se realizó completamente. Demostró su valor cuando instituciones como bancos, minoristas, empresas de medios y gobiernos se construyeron sobre ella.
La capa base es la capa de contribuyentes individuales de OpenLedger. Fascinante, auténtica, construible.
La escala económica se sitúa en la capa institucional.
Si OpenLedger puede desarrollar la red de confianza necesaria para hacer viable el intercambio institucional, entonces, si el entorno regulatorio sigue evolucionando hacia una dirección que haga del origen verificable un requisito de cumplimiento, entonces $OPEN no está valorado para ese mercado accesible.
Ni siquiera cerca.
O una gran oportunidad, eso es.
O una tesis que toma un período de tiempo más largo para materializarse que la mayoría de $OPEN titulares pueden mantener.
Realmente no estoy seguro de cuál.
Estoy prestando más atención a las señales de adopción institucional que a las señales de adopción de contribuyentes individuales.
Ahí es donde está el verdadero mercado.
¿Crees que el desbloqueo de datos empresariales es la mejor oportunidad de éxito de OpenLedger, más significativa que la compensación a los contribuyentes individuales?