
He estado pensando en algo que noté mientras navegaba por la actividad en la cadena de bloques a altas horas de la noche, el tipo de hábito que desarrollas cuando intentas entender hacia dónde se dirige realmente la infraestructura, en lugar de solo ver cómo se mueven los precios. No es trading, no es farming, solo observando cómo las wallets interactúan con sistemas que rara vez se explican claramente.
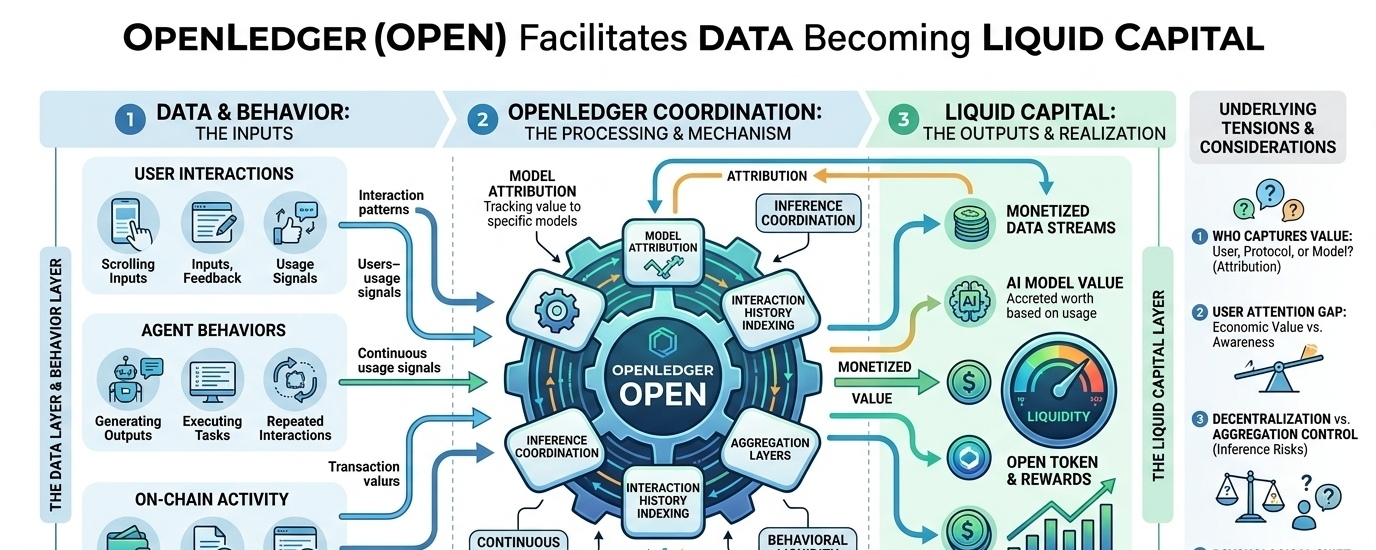
Está ocurriendo un cambio silencioso donde los datos ya no son solo un efecto secundario de usar aplicaciones cripto. Están empezando a comportarse más como una capa de activo por sí sola. Ahí es donde OpenLedger (OPEN) seguía volviendo a mi mente, no por el hype, sino por cómo enmarca los datos, modelos y agentes como algo que puede llevar liquidez.
Recuerdo cuando los datos en crypto significaban principalmente dashboards, herramientas de análisis, o tal vez métricas de DeFi si estabas lo suficientemente inmerso en ello. Ahora la conversación se siente más pesada de una manera que es difícil de ignorar. Se trata menos de observar datos y más de quién posee el flujo que los genera.
OpenLedger se encuentra en este incómodo espacio intermedio donde los datos no solo se recopilan, sino que se tratan como algo que se puede monetizar a través de sistemas de IA. La idea de que modelos y agentes pueden participar en estructuras de liquidez aún me parece un poco extraña. No es incorrecta, solo lo suficientemente desconocida como para que siga releyéndola.
Quizás estoy sobrepensando, pero sigo preguntándome quién realmente captura el valor cuando un agente de IA genera resultados a través de interacciones repetidas. ¿Es el usuario que proporciona la entrada, el protocolo que lo coordina, o el modelo mismo? La respuesta aún no parece clara, al menos no de una manera limpia.
Lo que destaca es cómo la liquidez, en este marco, comienza a extenderse más allá de los tokens y los pools, hacia comportamientos y patrones de interacción. Suena abstracto en papel, pero comienza a tener sentido cuando piensas en cómo los sistemas de IA ya aprenden continuamente de las señales de uso.
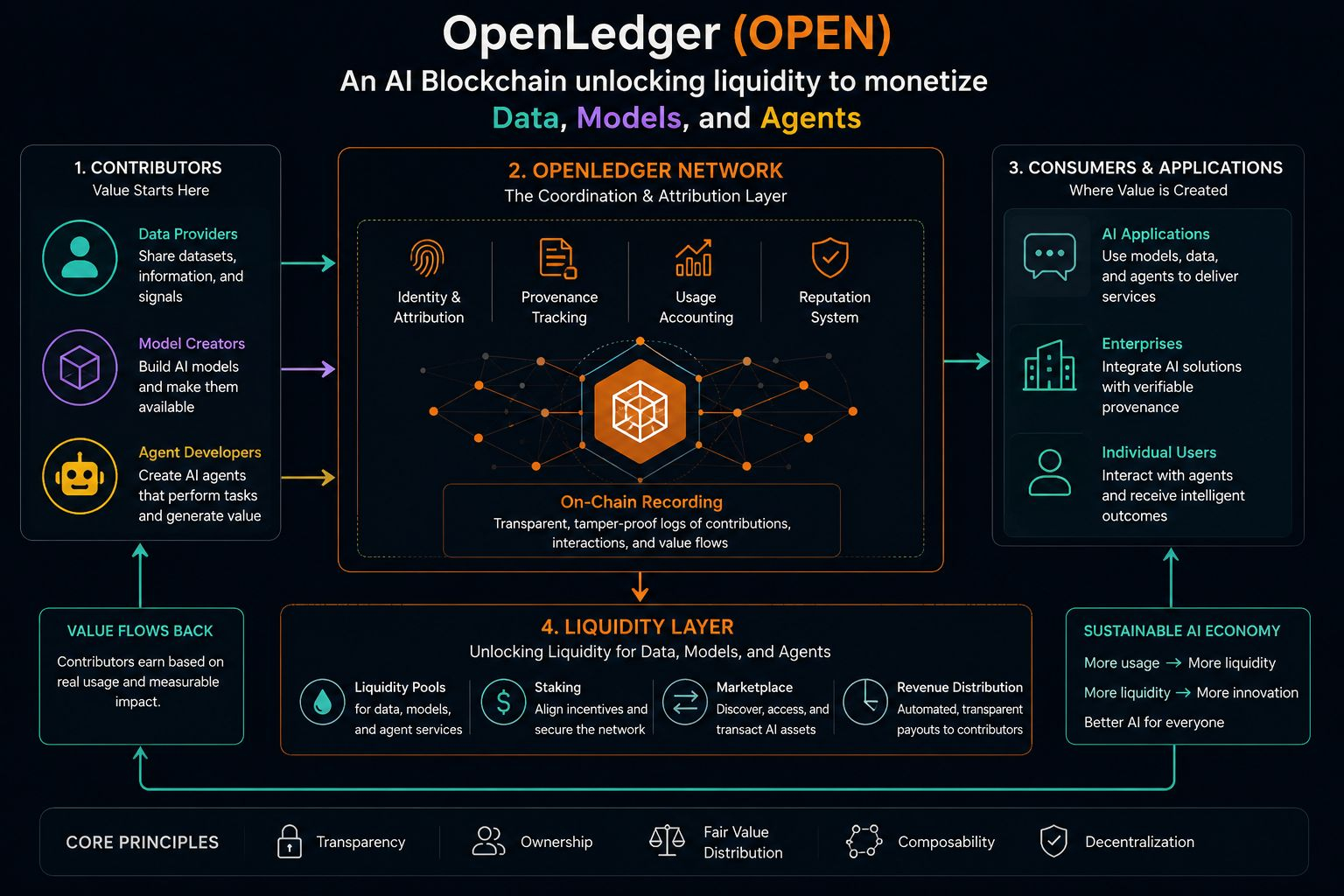
He visto versiones anteriores de esta idea en formas fragmentadas a través de mercados de datos y capas de incentivos, y generalmente enfrentan la misma fricción. La gente quiere la propiedad de sus datos, pero también quiere sistemas que no les obliguen a pensar en la propiedad en cada paso. Esa tensión nunca desaparece realmente.
OpenLedger parece estar intentando una especie de compresión de esa tensión, donde la contribución de datos, la interacción del modelo y la atribución no son capas completamente separadas. Sin embargo, no estoy totalmente convencido de cuán limpiamente funciona eso en el uso real. Se siente como una de esas ideas que solo revela su verdadera forma una vez que se alcanza la escala.
Al mismo tiempo, me pregunto si los usuarios alguna vez se preocuparán por la atribución a nivel de modelo. La mayoría de la gente no rastrea a dónde va su data hoy en día, incluso cuando claramente tiene valor. Esa brecha entre el valor económico y la atención del usuario podría ser más difícil de cerrar que la tecnología misma.
Sin embargo, la incorporación de agentes de IA en herramientas cotidianas cambia esa área de superficie. Una vez que los sistemas comienzan a tomar decisiones o ejecutar tareas en nombre de los usuarios, el historial de interacción se vuelve económicamente relevante, ya sea que los usuarios piensen activamente en ello o no.
Recuerdo una sensación similar durante los primeros experimentos de DeFi, donde los incentivos estaban ligados a comportamientos que al principio no parecían naturales. Pasó tiempo antes de que esos patrones se volvieran normales. No estoy seguro de si OpenLedger es lo mismo, pero el cambio psicológico se siente algo familiar.
También hay una incertidumbre continua sobre si este modelo introduce nuevas formas de centralización bajo la superficie. Incluso si el sistema es descentralizado estructuralmente, las capas de agregación o los puntos de control de inferencia aún podrían concentrar la influencia de maneras que no son inmediatamente visibles.
Lo que hace que sea más difícil de definir es si esto es una evolución natural de la infraestructura crypto o algo que está siendo moldeado principalmente por la demanda de IA. Podría ser que ambos se alimenten mutuamente, pero no creo que el límite entre ellos esté completamente definido aún.
No tengo una conclusión clara aquí. Sigo volviendo a la idea de que los datos están comportándose lentamente menos como información estática y más como algo más cercano al capital, pero en una forma que aún no hemos aprendido a valorar, hablar de ello, o incluso notar completamente en tiempo real.
