El mayor problema de los constructores en IA hoy en día no es el acceso a modelos. Es la confianza en los datos.
La mayoría de los constructores ya pueden acceder a modelos potentes a través de APIs. El desafío más complicado comienza cuando necesitan datos confiables para mejorar esos modelos, ajustar casos de uso específicos o construir agentes especializados. Los datos provienen de muchas fuentes, la calidad varía drásticamente, la propiedad a menudo no está clara y los contribuyentes rara vez tienen una razón directa para seguir proporcionando información útil con el tiempo.
Esto crea una situación extraña. Los constructores quieren mejor inteligencia, pero el flujo de trabajo utilizado para producir esa inteligencia está fragmentado. Los proveedores de datos, los constructores de modelos y los desarrolladores de aplicaciones a menudo operan en capas separadas con incentivos diferentes. El resultado es fricción, ciclos de iteración más lentos y incertidumbre sobre si los datos subyacentes siguen siendo útiles a medida que los proyectos escalan.
Lo que muchas personas malinterpretan sobre OpenLedger es que lo ven principalmente como otro proyecto de IA compitiendo por atención en un mercado ya saturado.
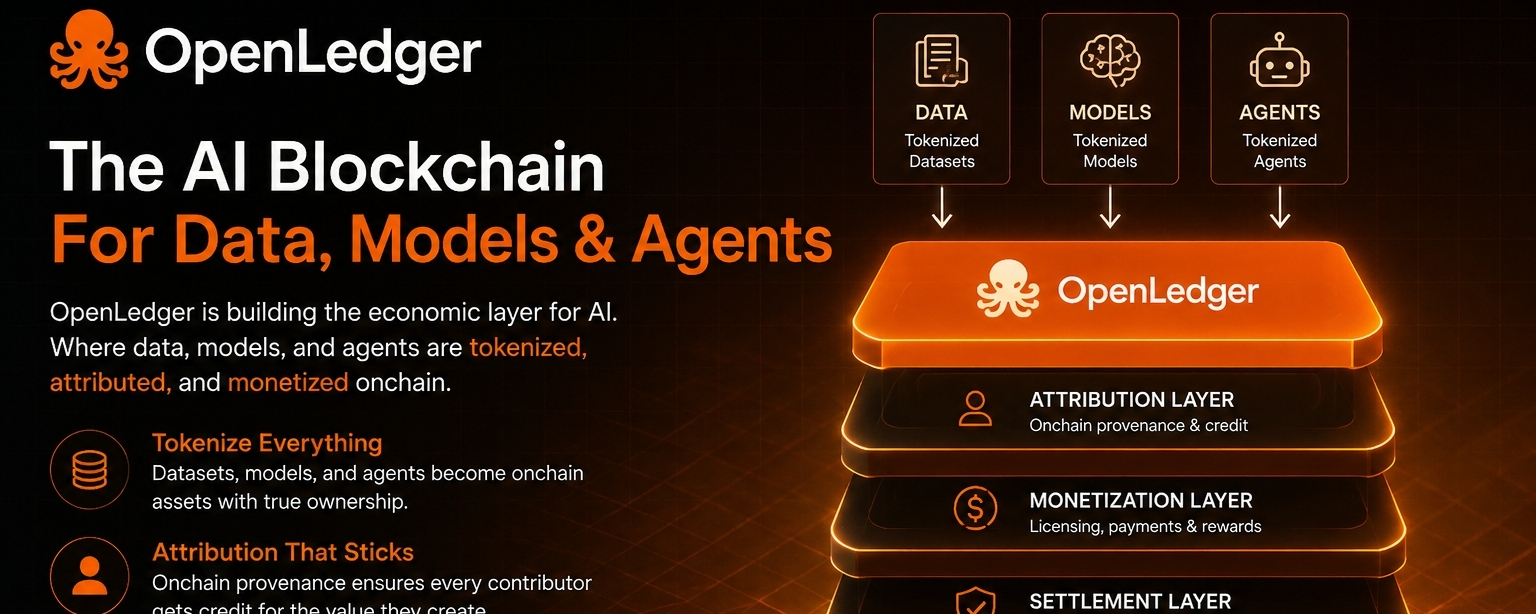
El ángulo más interesante es que OpenLedger parece estar enfocado en la capa de coordinación económica detrás del desarrollo de IA. El proyecto no solo pregunta cómo crear modelos. Pregunta cómo los contribuyentes, los conjuntos de datos, los modelos y las aplicaciones pueden interactuar de una manera donde la creación de valor sea medible y la participación siga siendo sostenible.
Esa distinción importa.
El flujo de trabajo tradicional a menudo trata los datos como un recurso de una sola vez. Los datos se recopilan, procesan y se absorben en modelos. Una vez que eso sucede, la conexión entre el contribuyente original y la generación de valor futuro se vuelve difícil de rastrear. Los constructores obtienen inteligencia, pero las estructuras de atribución e incentivos se vuelven cada vez más opacas.
OpenLedger intenta reducir esta fricción al introducir infraestructura donde los datos, modelos y agentes de IA pueden existir dentro de un marco diseñado para la atribución y la monetización. En lugar de ver los datos como una entrada desechable, el sistema los trata como un activo que puede seguir generando valor a lo largo del ciclo de vida de las aplicaciones de IA.
La parte que más me destaca es que esto cambia la conversación de solo el rendimiento del modelo a la responsabilidad de la contribución.
Los constructores hablan frecuentemente sobre mejores modelos. Pasan menos tiempo discutiendo cómo sucede realmente la producción de datos sostenible. Sin embargo, muchos productos de IA terminan siendo limitados por la calidad de los datos en lugar de la capacidad bruta del modelo. Si los contribuyentes no tienen razones para seguir participando, la calidad de los datos se deteriora. Cuando la calidad de los datos se deteriora, el rendimiento de la aplicación eventualmente sigue.
Aquí es donde existe el punto de presión de adopción.
Para que OpenLedger importe, los constructores deben decidir que la atribución y la alineación de incentivos son lo suficientemente importantes como para integrarlas en sus flujos de trabajo. La tecnología en sí es solo parte de la ecuación. El desafío más grande es el comportamiento. Los desarrolladores están acostumbrados a los canales existentes, conjuntos de datos centralizados y herramientas de IA establecidas. Cualquier nueva infraestructura debe reducir suficiente fricción para justificar el cambio de esos hábitos.
Si ocurre ese cambio, los constructores obtienen algo valioso: un camino más claro entre la contribución y la recompensa. Los proveedores de datos tienen razones más fuertes para participar. Los creadores de modelos obtienen acceso a fuentes de información potencialmente más ricas. Los desarrolladores de aplicaciones operan sobre un sistema donde los flujos de valor pueden ser rastreados de manera más transparente.
Considera un escenario práctico.
Un equipo que construye un asistente de salud especializado necesita conocimiento específico del dominio que los modelos de propósito general no pueden proporcionar de manera confiable. Requieren contribuciones continuas de expertos, investigadores y fuentes de datos de nicho. Bajo estructuras tradicionales, mantener el compromiso de los contribuyentes se vuelve difícil porque la relación entre la contribución y el valor futuro es débil.
Un marco como OpenLedger intenta crear una estructura donde las contribuciones permanezcan visibles y económicamente conectadas a la inteligencia que se produce. En lugar de reconstruir constantemente la participación desde cero, los constructores pueden operar potencialmente dentro de un sistema diseñado para alentar la contribución a largo plazo.
Eso no soluciona automáticamente el problema.
Sigue existiendo un riesgo honesto.
La infraestructura puede crear mecanismos de atribución, pero no puede forzar una participación significativa. Si los contribuyentes de alta calidad, los constructores de modelos y los desarrolladores de aplicaciones no utilizan activamente la red, el diseño económico se vuelve menos relevante. Los sistemas de coordinación se vuelven poderosos solo cuando suficientes participantes acuerdan coordinarse a través de ellos.
Por eso la adopción de la red importa más que la arquitectura técnica sola.
La tesis más fuerte sobre OpenLedger no es que ayuda a crear IA. Muchos proyectos ya persiguen ese objetivo. La tesis más fuerte es que intenta reducir una de las ineficiencias estructurales más persistentes de la IA: la desconexión entre aquellos que contribuyen con inteligencia y quienes capturan su valor. Si los constructores cada vez ven la atribución de datos y la alineación de incentivos como infraestructura necesaria en lugar de características opcionales, el enfoque de OpenLedger se vuelve mucho más fácil de entender.
