
For many developers and users, decentralized storage remains an abstract idea. It is often described in terms of protocols, incentives, and cryptography, but rarely in terms of what actually happens when an application tries to save something real. A file, a game state, a piece of content, or a record of activity is not a theoretical object. It is something that must survive network failures, software updates, and the slow passage of time. Understanding how this works in practice is where infrastructure stops being a concept and starts being a system.
Imagine a decentralized application built on Sui that needs to store a large piece of data. This could be a media file, a complex dataset, or a snapshot of an application’s evolving state. The first important point is that this data is not treated like a normal on-chain object. Putting it directly into the blockchain would be inefficient and unnecessary. Instead, the application prepares this data as a blob, a large structured object designed to live in a specialized storage layer rather than in the execution layer itself.When this blob is sent to Walrus, it does not simply get copied and placed onto a single machine or even a small group of machines. The system immediately begins to process it using erasure coding. This transforms the original data into a set of fragments in such a way that the full blob can later be reconstructed even if some of those fragments are missing. This is a critical shift from traditional replication. Instead of relying on complete copies scattered around the network, the system relies on a mathematically defined structure of partial information.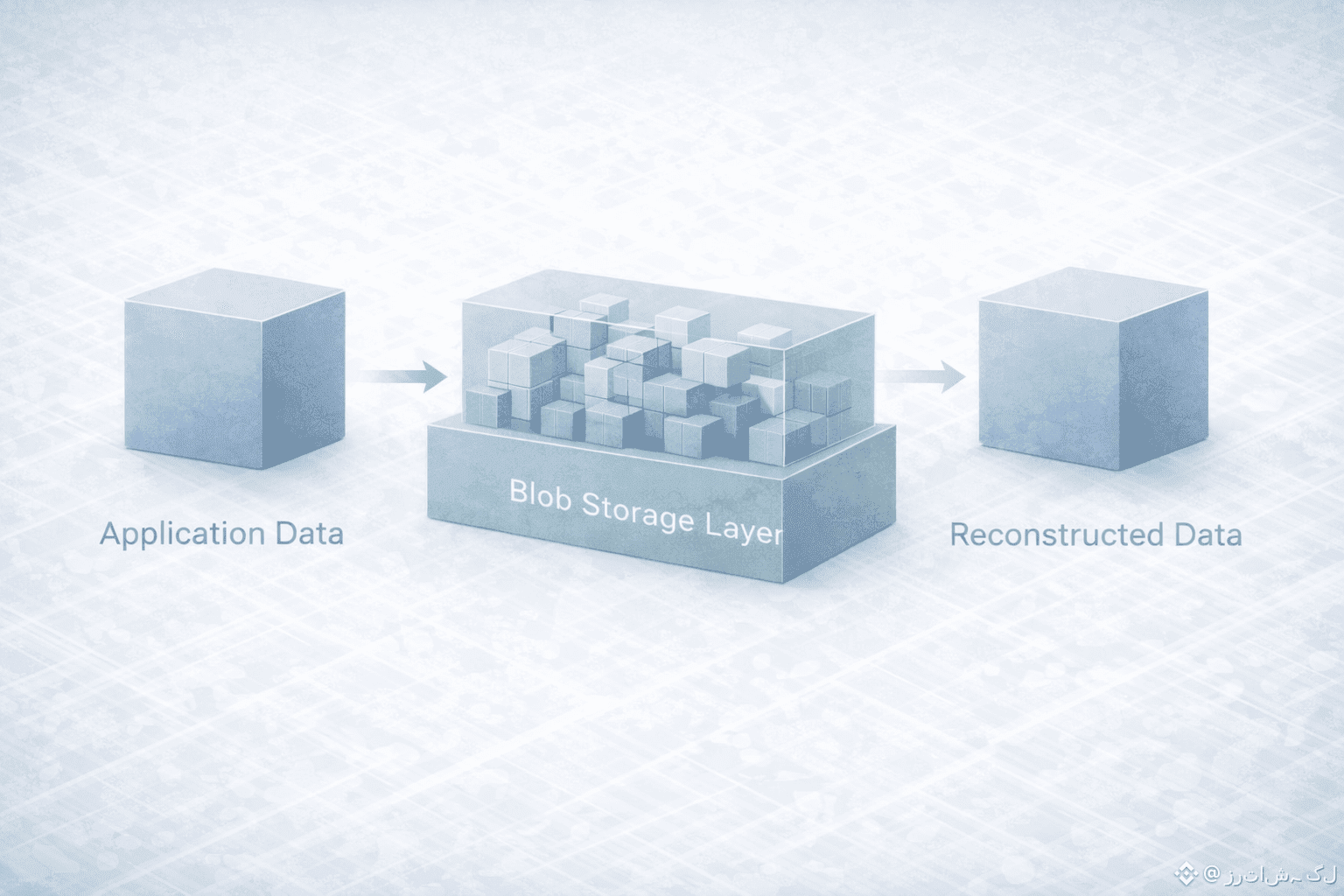
These fragments are then distributed across the Walrus storage network. Each node holds only a piece of the overall picture, and no single node is essential for the blob to survive. From the outside, this process is invisible. The application does not need to track where each fragment lives or which machines are responsible for them. What it gets back is a reference, a way to point to that blob and prove that it exists in the system.This is where the relationship with Sui becomes important. The reference to the blob can be managed and verified within the on-chain logic of the application. The blockchain does not need to store the data itself, but it can still reason about it. It can check that the blob exists, that it has not been altered, and that it is the same object that the application expects to be using. In this way, execution and storage remain separate, but they are no longer disconnected.
When the application or a user later needs to access the data, the process runs in reverse. The system retrieves enough fragments from the network to reconstruct the original blob. It does not need all of them. It only needs a sufficient subset. This makes the system naturally tolerant to outages, slow nodes, and partial failures. From the user’s perspective, the data is simply there. From the infrastructure’s perspective, it is being continuously reassembled from a distributed and changing set of components.What makes this approach especially important is how it changes the failure model. In many traditional systems, losing a specific server or a specific data center is a serious event. In a system built around erasure coding and distribution, failure is not an exception. It is a normal condition that the system is designed to live with. Nodes can come and go, and the data remains accessible because no single node ever had the full responsibility for it.
Over time, this also changes how applications can be designed. Developers no longer need to think in terms of a fragile storage backend that must be carefully protected and monitored. Instead, they can think in terms of a persistent data layer that is resilient by construction. This does not remove the need for good design or careful engineering, but it does remove an entire category of hidden risk that has followed decentralized applications since their earliest days.There is also an important privacy dimension to this flow. Because data is fragmented and distributed, no single storage provider has a complete view of what is being stored. Access control and application-level logic still matter, but the underlying structure already avoids the most obvious forms of centralized visibility and control. This is not about secrecy for its own sake. It is about reducing unnecessary exposure and concentration of information.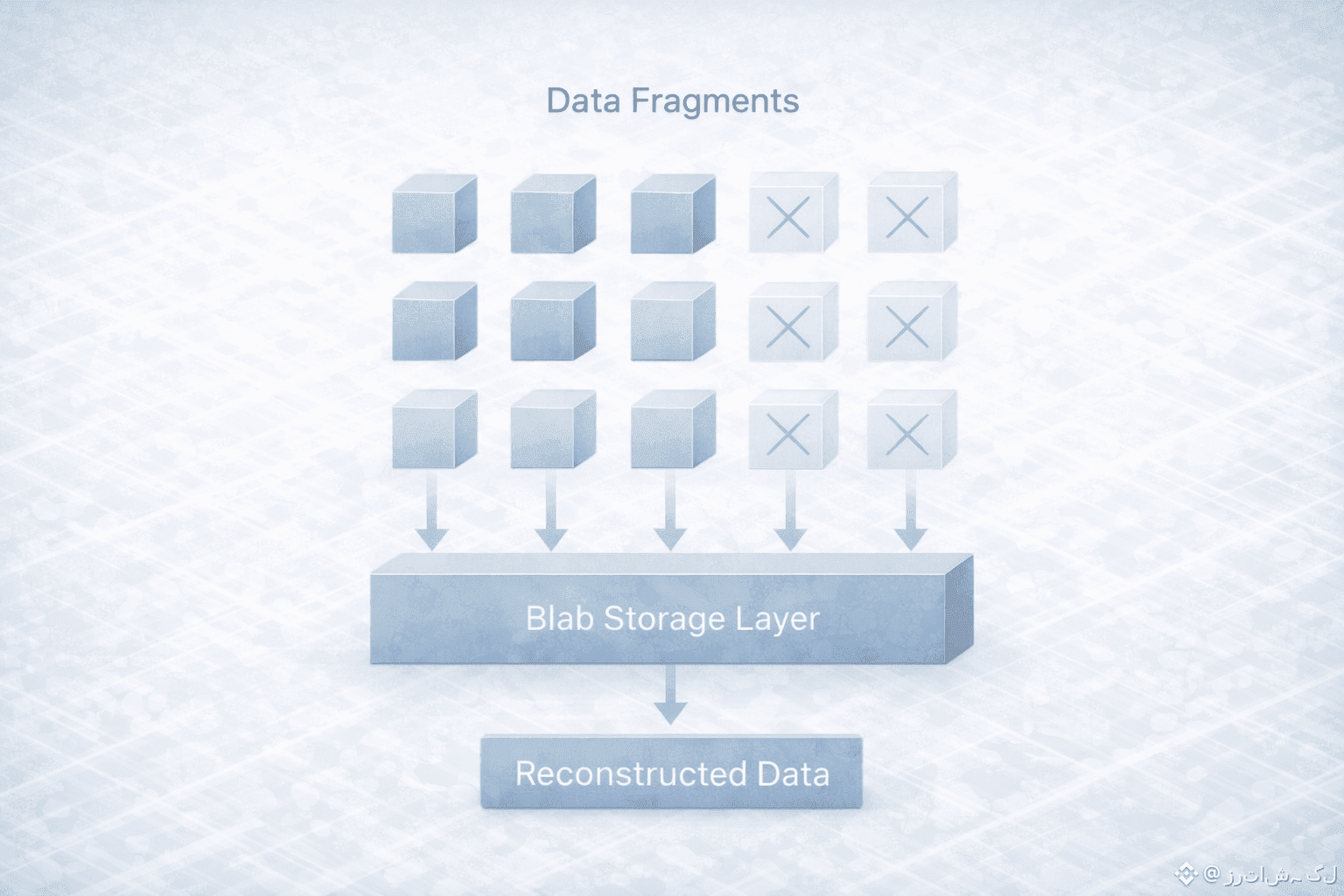
From the outside, all of this looks deceptively simple. An application stores data. Later, it reads data. But under the surface, what is happening is a carefully designed choreography between execution and memory, between on-chain logic and off-chain persistence, and between individual nodes and the network as a whole.This is why systems like Walrus are best understood not as products, but as environments. They do not change what applications want to do. They change how safely and reliably they can do it. And in infrastructure, that difference often takes years to be fully appreciated, because the real value only becomes obvious when things go wrong and nothing breaks.
In the long run, this is what mature decentralized systems begin to look like. Not spectacular, not dramatic, but quietly dependable. Data goes in, data comes back out, and the network absorbs the complexity in between. That is not the end of the story of Web3 storage, but it is a sign that the story is finally becoming more grounded in reality.
