
@Vanarchain He notado un cambio en la forma en que las personas hablan sobre los agentes de IA en el último año. La conversación solía estar obsesionada con el modelo: ¿cuál es más inteligente, cuál es más barato, cuál puede programar? Ahora las preguntas suenan más como ansiedad operativa. “¿Cómo evito que mi agente olvide?” “¿Cómo llevo el contexto a través de herramientas sin tener que explicarme de nuevo?” “¿Cómo demuestro que el agente no inventó cosas en silencio cuando las apuestas son reales?” Ese es el estado de ánimo al que se enfrenta la API de Memoria de Neutron, y es por eso que la idea de almacenar el contexto del agente como “Semillas”, buscar por significado y opcionalmente anclar pruebas de integridad en la cadena se siente de repente relevante en lugar de teórica.
Vanar enmarca a Neutron como una capa de memoria semántica, y ese marco importa porque trata “memoria” como más que una base de datos. En la documentación, la unidad básica de Neutron es un Seed: un bloque compacto de conocimiento que puede incluir texto, visuales, archivos y metadatos, enriquecido con embeddings para que sea buscable por significado en lugar de por palabras exactas. Esa es la clave psicológica para los agentes. Los humanos no recuerdan por nombres de archivos y carpetas..
La memoria no son notas perfectas—es la esencia: el punto, el estado de ánimo y la limitación importante. Cuando un agente encuentra información por intención y similitud, se convierte en más que un escritor inteligente. Se convierte en un ayudante confiable que entiende lo que está sucediendo. “Seeds” también implica algo sutil sobre cómo debe crecer el contexto. No quiero que la memoria de mi agente sea un solo despliegue largo que eventualmente se vuelva inutilizable. Quiero que sea lo suficientemente granular para reutilizar, recombinar y citar. Las propias descripciones de Vanar se inclinan hacia esta idea de “objeto de conocimiento”: los archivos se convierten en objetos consultables; puedes hacer preguntas a un PDF; los datos dejan de ser estáticos y comienzan a activar lógica. Ya sea que compres cada parte de esa ambición o no, la dirección es consistente: una unidad de memoria debe ser lo suficientemente pequeña para recuperar con precisión, pero lo suficientemente estructurada para seguir siendo significativa más tarde.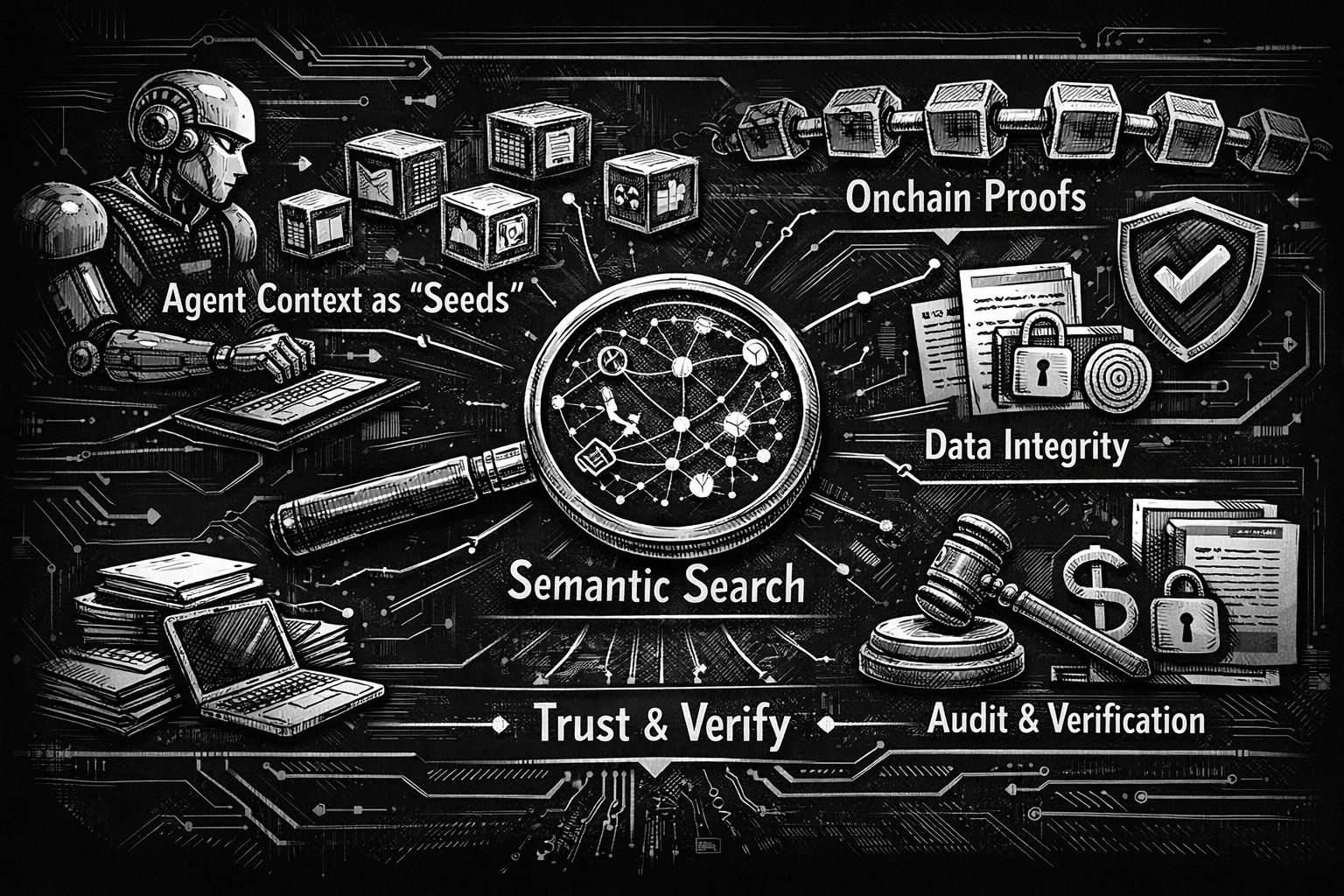
La parte práctica se muestra cuando observas cómo se presenta la API de Memoria a los desarrolladores. La página de consola de Neutron demuestra un flujo simple: POST un Seed con contenido y metadatos, luego consulta Seeds con un prompt en lenguaje natural y un límite. Eso puede sonar básico, pero en el trabajo de agentes, lo básico es poderoso. La mayoría de los fallos de agentes que veo no son “el modelo es tonto.” Son “el modelo es ciego.” No tenía la preferencia única, la decisión anterior, la restricción oculta en un documento, el detalle de “ya intentamos esto” que evita bucles. Una API de memoria que es fácil de llamar se convierte en un hábito habitual, y el hábito es lo que convierte prototipos en sistemas.
También hay una expectativa de rendimiento muy actual incrustada en la posición de Neutron de Vanar: búsqueda semántica que sea lo suficientemente rápida como para sentirse como un pensamiento, no como una solicitud de red. La mensajería de consola de Neutron afirma explícitamente búsqueda semántica de menos de 200 ms, y se especifica sobre elecciones de implementación como pgvector y configuración de embeddings. No estoy citando eso para fetichizar herramientas; lo cito porque la latencia es emocional. Si la recuperación toma demasiado tiempo, los usuarios dejan de confiar en ella. Comienzan a volver a explicar “por si acaso,” lo que derrota todo el propósito. Cuando la recuperación es casi instantánea, la gente se relaja. Comienzan a hablar de manera natural nuevamente, y ahí es cuando el agente realmente puede ayudar.
Ahora, el título que diste añade una capa de integridad: pruebas opcionales en la cadena. Aquí es donde la historia de Neutron se convierte en más que “RAG con mejor marca.” La documentación de Vanar describe un enfoque híbrido: los Seeds se almacenan fuera de la cadena por defecto para rendimiento y flexibilidad, y pueden ser almacenados opcionalmente en la cadena para verificación, propiedad e integridad a largo plazo. También describen la capa en la cadena como la que añade metadatos inmutables y seguimiento de propiedad, hashes de archivo cifrados para verificación de integridad, y auditorías transparentes. Eso no es solo una característica de seguridad. Es una característica de gobernanza para la memoria.
Si alguna vez has tenido un agente que da una respuesta segura y no puedes decir de dónde proviene, has sentido el verdadero problema: no es inteligencia, sino responsabilidad. La documentación de Neutron sobre “citas de fuente” y trazabilidad—ser capaz de ver qué Seeds se utilizaron en una respuesta—apunta directamente a esa brecha de confianza. Y cuando combinas trazabilidad con anclaje opcional en la cadena, obtienes un espectro: memoria barata y rápida para el trabajo diario, y memoria de “demuéstralo” para momentos en los que la integridad importa. El punto no es que todo debe ir en la cadena. El punto es que tú decides qué memorias merecen ser tratadas como registros.
Esto está en tendencia ahora por tres razones que sigo viendo en flujos de trabajo reales. Primero, las ventanas de contexto y la fragmentación de herramientas siguen siendo el impuesto silencioso sobre la productividad de la IA. La propia posición de MyNeutron de Vanar es básicamente una confesión de lo que los usuarios avanzados experimentan: cambiar de plataformas, perder contexto, comenzar desde cero. Incluso si los modelos se vuelven más grandes, los usuarios aún se mueven entre chats estilo ChatGPT, documentos, correos electrónicos y herramientas de equipo. La memoria tiene que viajar, o no es memoria.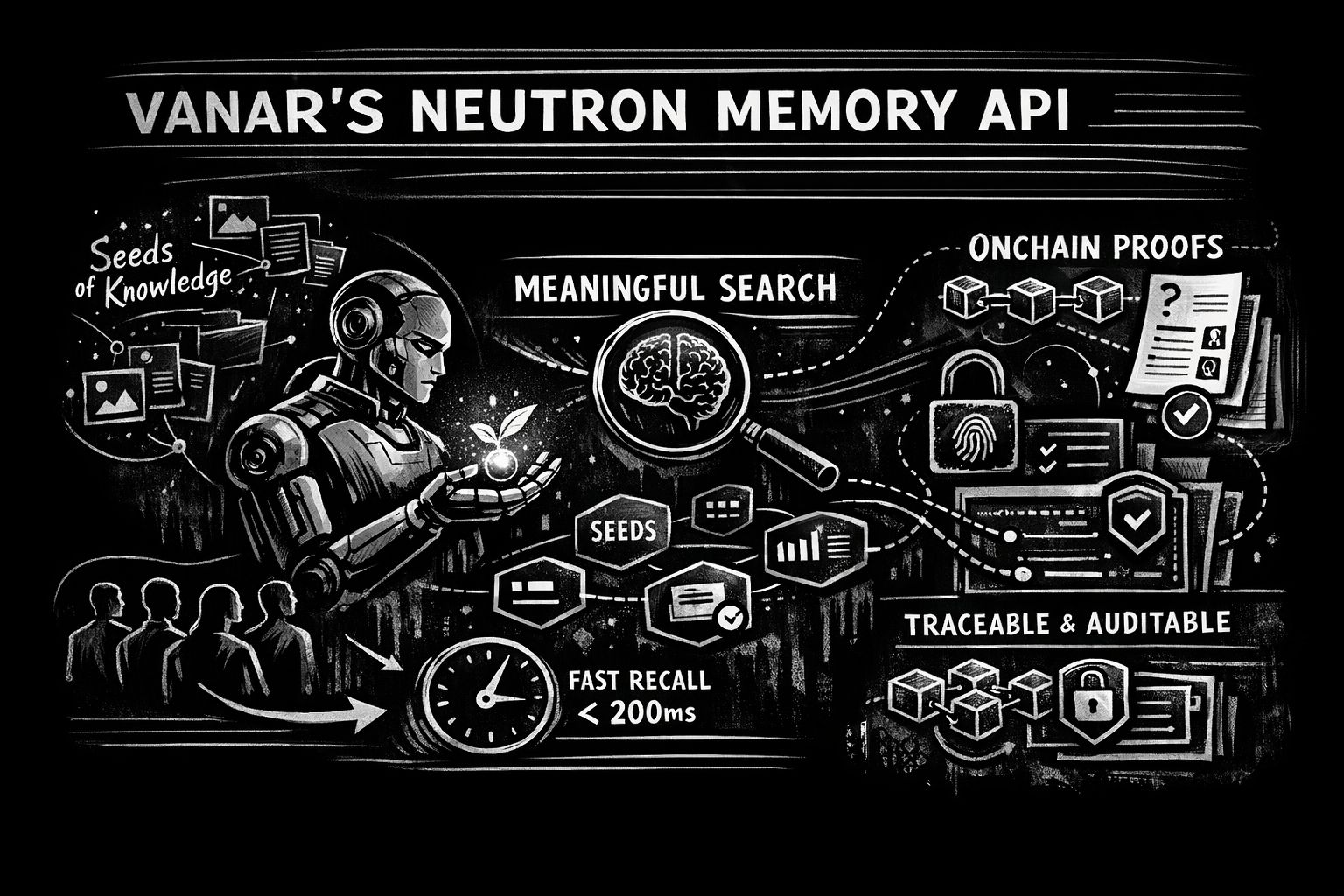
En segundo lugar, la IA agentiva está pasando de “autonomía de juguete” a “autonomía de tarea,” y la autonomía de tarea requiere continuidad. Un agente que reserva, negocia, redacta y da seguimiento durante días necesita una narrativa interna estable de lo que sucedió. Los Seeds de Neutron se describen como persistentes y amigables entre canales, y la hoja de ruta de integraciones nombra explícitamente las superficies donde la continuidad se rompe hoy—Gmail, Drive ahora, y luego herramientas estilo Slack/Teams/Notion/Jira después. Este es exactamente el lugar donde los proyectos de agentes o maduran o mueren: ¿pueden mantener el contexto a través de los lugares desordenados donde los humanos realmente trabajan?
En tercer lugar, la crisis de confianza en torno al contenido generado se está volviendo más costosa. Cuando las salidas de IA se utilizan para cualquier cosa financiera, legal, operativa o reputacional, “suficientemente cerca” se vuelve peligroso. El marco más amplio de Vanar incluso menciona a los Seeds como una capa de compresión semántica para datos legales, financieros y basados en pruebas, con la idea de que esto puede vivir directamente en la cadena. Nuevamente, no tienes que estar de acuerdo con cada afirmación arquitectónica para entender el motivo: hacer que la memoria sea auditable cambia quién está dispuesto a confiar en ella.
Lo que me gusta del marco de “Seeds + búsqueda de significado + pruebas opcionales en la cadena” es que respeta dos realidades diferentes a la vez. La primera realidad es que los agentes necesitan recuperación rápida y flexible para ser útiles. Esa es la razón por la que existe el almacenamiento predeterminado fuera de la cadena. La segunda realidad es que algunas memorias necesitan sobrevivir a disputas. Cuando el dinero se mueve, cuando hay cumplimiento involucrado, cuando un equipo discute sobre “quién aprobó qué,” la memoria se convierte en evidencia. Ahí es donde los metadatos inmutables, el seguimiento de propiedad y los hashes de integridad dejan de ser decoraciones técnicas y comienzan a convertirse en barandas de seguridad operativas.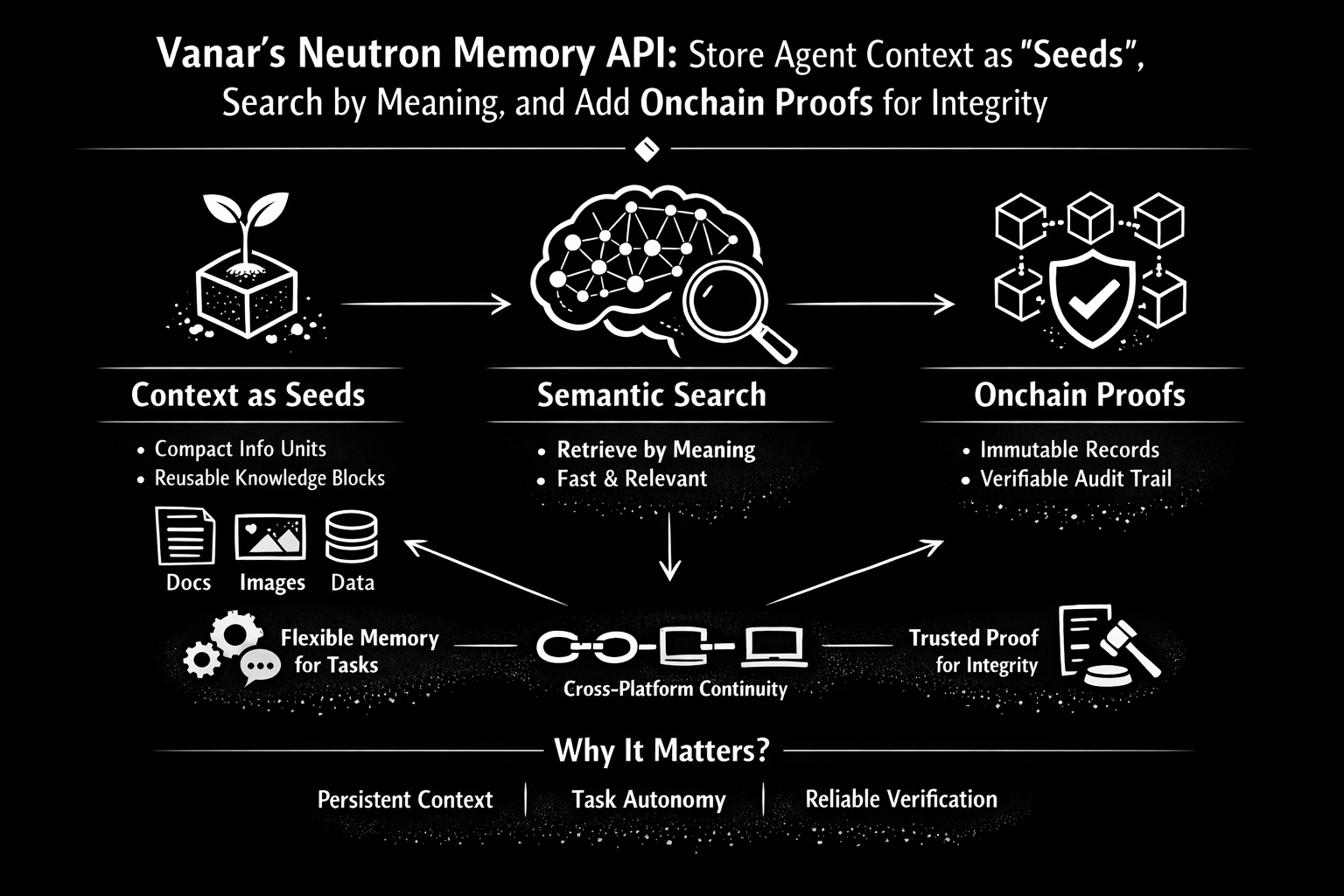
Mi conclusión, después de observar cómo las personas realmente usan la IA día a día, es que la memoria se convertirá en el verdadero límite del producto—no los modelos. verifícalo cuando las apuestas son altas.
Modelos más inteligentes vienen de cualquier manera. Los ganadores serán los sistemas que puedan mostrar su trabajo con calma: lo que recuerdan, por qué está en la memoria, de dónde se extrajo y cómo puedes probar que es preciso cuando lo necesites. El enfoque de Neutron—comprimir la experiencia en Seeds, recuperar por significado y opcionalmente anclar pruebas para integridad—se alinea claramente con ese futuro, porque trata la memoria como un problema de rendimiento y un problema de confianza, sin pretender que esas son la misma cosa.
\u003cm-18/\u003e\u003ct-19/\u003e\u003cc-20/\u003e
