Mira Network makes more sense when you stop seeing it as an AI project and start approaching it like a trust project.
The team is effectively arguing this: AI will keep giving answers that seem confident even when they are incorrect, and that single weakness limits the move from assistant to autonomous operator in any real context. Instead of offering a model that never slips, Mira seeks to construct a verification layer that sits above models and converts their output into something other systems can depend on. Their own framing is that the network translates outputs into independently verifiable claims, then several models collectively assess if each claim holds up.
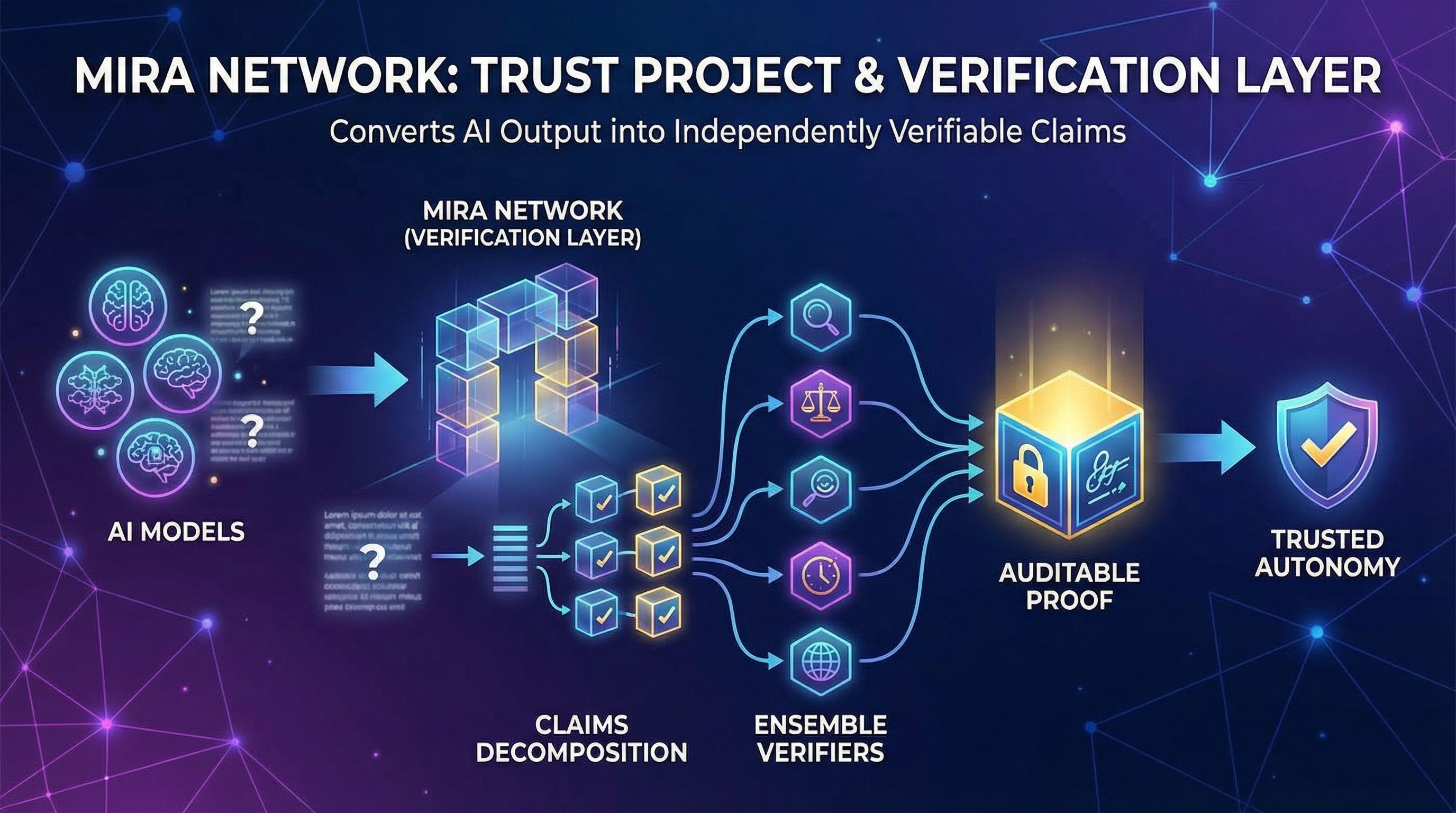
If you go to what they’re shipping publicly, the message is consistent. Mira Verify is marketed as a developer-facing tool where various models cross-check assertions, and the outcome is supposed to be auditable rather than received on trust. Scrolls by Mira looks like the companion layer that helps onboard individuals into how the network thinks about verification and participation.
Where the project becomes intriguing, and where most surface-level perspectives miss the point, is that #Mira is not confirming “answers.” It’s confirming claim units. That seems like semantics until you imagine how this really works in the real world.
When a model creates a paragraph, it frequently blends multiple sorts of claims. Some are factual. Some are inferred. Some rely on definitions. Some rely on time. Some depend on location. Mira’s method is to separate that paragraph into smaller bits that can be verified independently, and then send those pieces out to independent verifiers. The purpose is not to make language lovely. The idea is to make language testable.
That breakdown stage is also the first place I would check if I were attempting to grasp what $MIRA actually is.
Because whomever controls how material is separated into claims silently controls the kind of truth the network can perceive. If a deconstruction system reduces a complicated statement into a stark yes-or-no assertion, it may create a false certainty. If it breaks an argument into pieces that lose their connection, it may certify each fragment while the overall conclusion remains unsubstantiated. The whitepaper considers translation into verifiable assertions as a basic design stage, not an optional add-on, which is why it matters so much.
This is the contrarian argument that people miss because it’s not exciting: decentralizing the verifiers does not immediately decentralize the decomposition layer. In the early phases, it’s normal for the transformation pipeline to be constructed and controlled in a more centralized approach simply because someone needs to ship it. Mira’s roadmap language acknowledges progressive decentralization in multiple components. That is normal, but it poses a simple issue you should keep asking as the project evolves: is the network decentralizing the portion that determines what gets verified, or largely decentralizing the part that votes on what was previously decided?
Now assuming decomposition is done correctly. The second challenging issue is what unanimity implies when the voters are models.
Mira’s approach is simply ensemble verification with economic pressure. Multiple models check the same claim, their findings are pooled, and the network reaches a decision based on a threshold. In theory, it lowers one-off hallucinations and pushes assertions to survive more than a single model’s internal logic.
But consensus is not a synonym for truth. It’s a filter. A beneficial filter, frequently, but still a filter.
There are at least three failure types that seem “healthy” from the outside because the system is performing as expected.
One is shared blind spots. If the verifier pool is dominated by similar model families, trained on comparable corpora, or reliant on similar retrieval sources, you may obtain robust agreement that is not independent confirmation, it’s correlated error. Mira’s own point is that variety between models and operators should minimize statistical bias and increase dependability. That is conceivable, but it is also something the network needs to actively preserve, since cost pressure always drives systems toward whatever verifier is cheapest and quickest.
A second pattern is time sensitivity. Many statements are accurate until they aren’t. If verifiers are even little behind reality, they may safely agree on something that used to be right. That matters a lot for any “autonomous” system, since obsolete accuracy may be just as hazardous as plain nonsense.
A third pattern is contextual accuracy. A claim might be legitimate in one jurisdiction and incorrect in another. It may be true under one meaning and untrue under another. If the claim format doesn’t convey enough information, verifiers are obliged to answer a simplified query that reality doesn’t truly support.
This is why the certificate notion is the element of Mira that I take most seriously. If you’re going to depend on verification, you need more than a green light. You need a record that reflects what was checked, under what circumstances, and how agreement was obtained. Mira’s public material leans on cryptographically verifiable outputs and auditability as a differentiator, which is the ideal route if they want downstream systems to regard verification findings as proof rather than feelings.
Then there’s incentives, which is where Mira is attempting to shift verification out of the merely “trust us” area.
The whitepaper presents node behavior as economically directed, with measures meant to render dishonest or low-effort verification illogical. That helps with the lazy-node issue, where operators could attempt to predict or shortcut computation. But incentives also generate a quieter risk: if rewards are mostly connected to imitating the majority, the safest choice becomes conformity. Over time, a system might slide toward rewarding “being aligned” more than “being correct.” To prevent that, the network requires techniques to detect and reward proper disagreement, not merely penalize bad disagreement. That’s not a marketing bullet. That’s the difference between a verification market and a consensus machine.
So if you want a realistic vision centered on the project, this is what I believe Mira is actually aiming to become.
Not a magic remedy for hallucinations. Not a new foundation layer narrative. More like a verification tool that developers may plug into when they cannot afford quiet failure. That is what Mira Verify is attempting to achieve right now: a practical verification layer that can sit in a process and lower the probability that an application acts on unsubstantiated assertions.
If Mira succeeds, it probably appears uninteresting from the outside. Teams start considering model output as untrusted input by default. The output is transformed into claims. Claims are reviewed by various independent verifiers. Only then does the system authorize an action or publish a response. When anything goes wrong, you may track the chain of verification and discover what the network really decided, not what it was meant to determine.
If $MIRA fails, it typically fails in one of three non-dramatic ways. The verification overhead is too costly or too sluggish for genuine goods. The decomposition layer creates a bottleneck that never really decentralizes. Or the verifier pool converges toward a limited, correlated group where agreement seems high but is less independent than it looks. @Mira - Trust Layer of AI
