@Mira - Trust Layer of AI #Mira
Durante años, la conversación en torno a la inteligencia artificial se ha centrado casi en su totalidad en la capacidad: modelos más grandes, inferencias más rápidas, más datos y resultados cada vez más impresionantes que parecen, al menos en la superficie, aproximarse al razonamiento humano. Sin embargo, debajo de este rápido progreso se encuentra una pregunta más silenciosa y difícil que la industria solo ha comenzado a confrontar seriamente recientemente: ¿cómo determinamos cuándo un sistema de IA es realmente confiable? No simplemente convincente, no solo seguro, sino confiable de una manera que las instituciones, los mercados y la infraestructura crítica puedan depender sin dudar.
El desafío existe porque los sistemas de IA modernos no producen conocimiento en el sentido tradicional; generan probabilidades moldeadas por patrones en sus datos de entrenamiento. Un modelo puede sonar autoritario mientras fabrica silenciosamente una cita, malinterpreta una cláusula regulatoria o combina fragmentos de información en algo que parece lógico pero se basa en fundamentos inestables. Estas fallas rara vez aparecen de manera dramática. En cambio, se manifiestan como distorsiones sutiles que pasan desapercibidas hasta que sus consecuencias surgen en informes financieros, resúmenes de investigación o decisiones automatizadas que dependen de la salida del modelo como si fuera un hecho verificado.
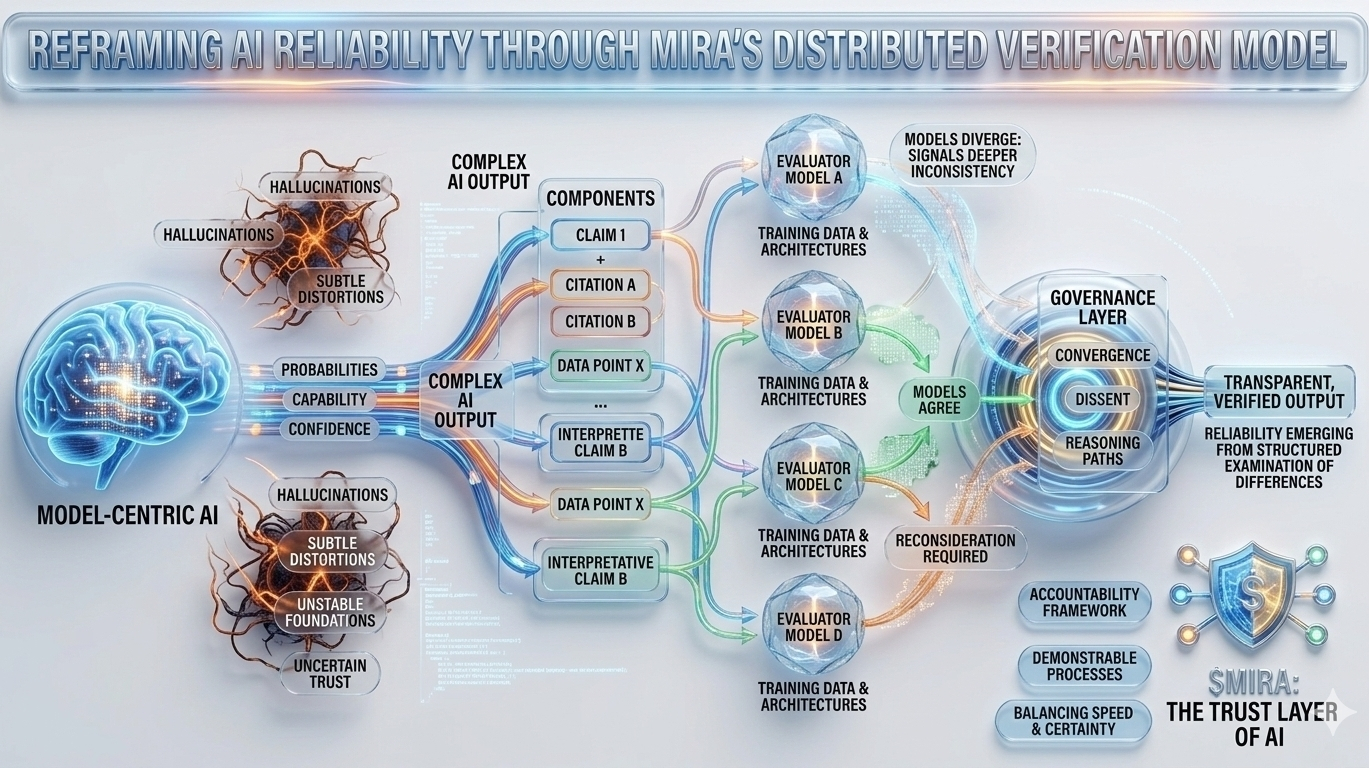
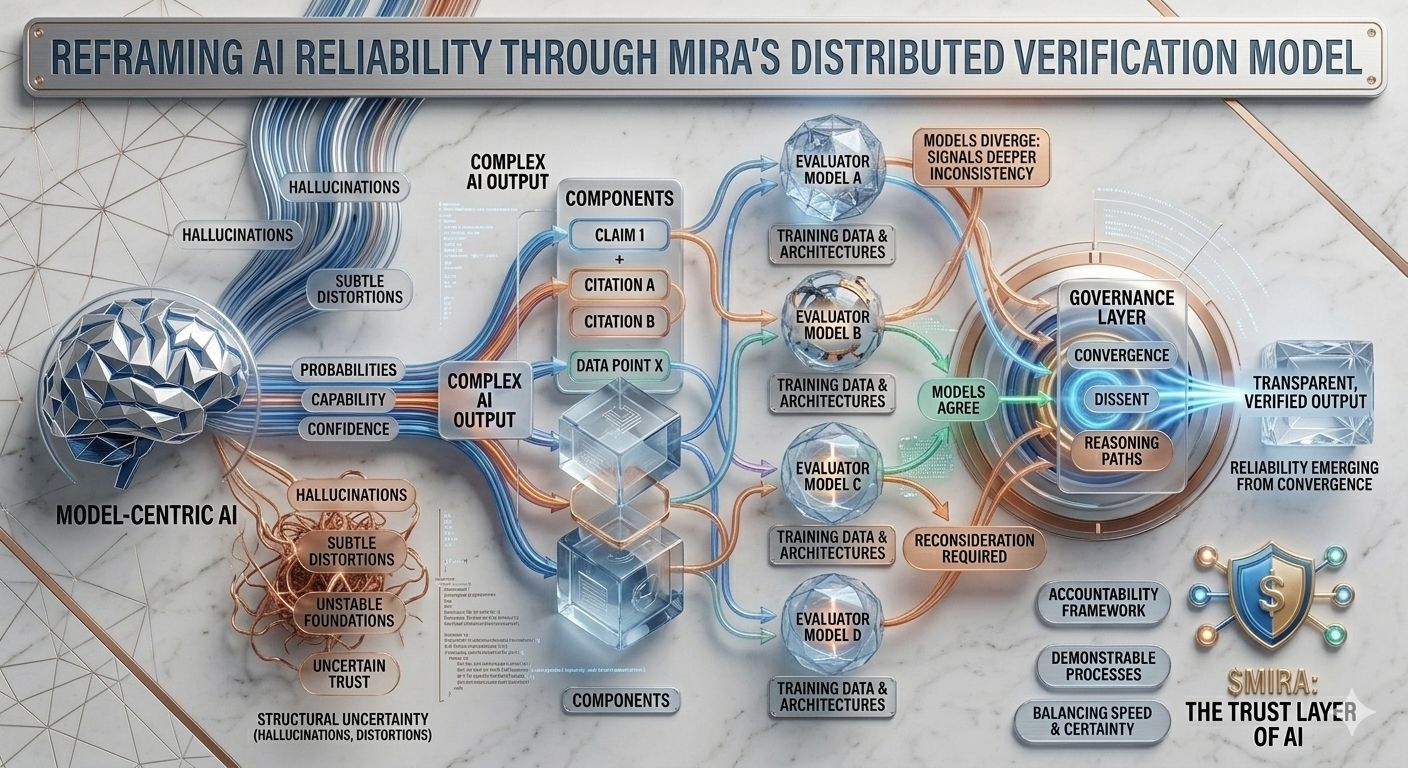
Esta incertidumbre estructural es precisamente el problema que Mira intenta abordar, no exigiendo perfección de un solo modelo, sino repensando todo el proceso a través del cual se producen y validan las respuestas de IA. En la arquitectura de Mira, una salida de IA se trata menos como una conclusión terminada y más como una hipótesis que entra en un pipeline de verificación. En lugar de confiar en el camino de razonamiento de un modelo, el sistema distribuye la evaluación entre múltiples modelos independientes que examinan la misma afirmación desde diferentes perspectivas, cada una moldeada por distintos corpora de entrenamiento, arquitecturas y sesgos internos.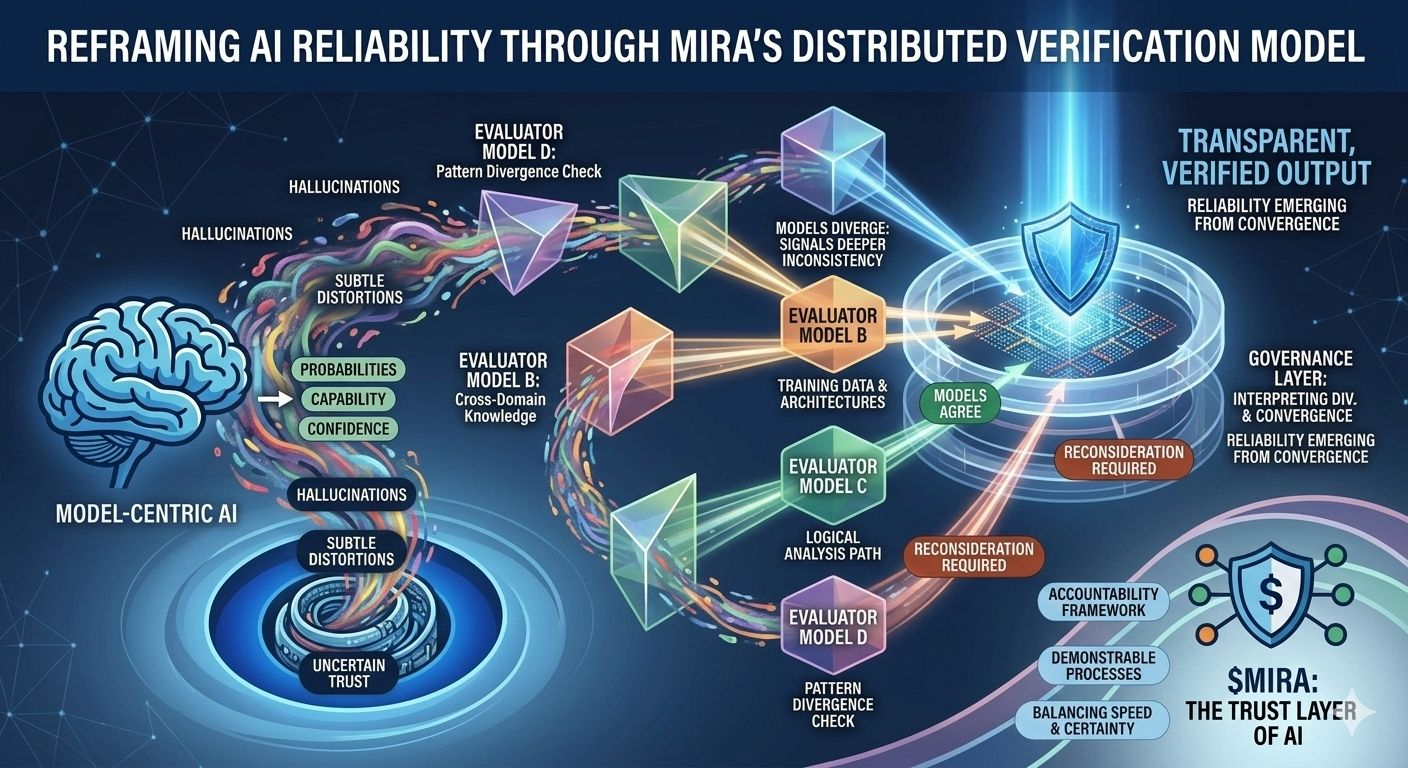
Lo que hace que este enfoque sea particularmente interesante es que el objetivo no es el acuerdo ciego entre modelos. La votación por mayoría simple ofrecería solo una tranquilidad superficial, ya que los modelos entrenados en datos superpuestos a menudo heredan suposiciones y puntos ciegos similares. El marco de gobernanza de Mira, en cambio, se centra en interpretar cómo los modelos coinciden, dónde divergen y si el desacuerdo señala una inconsistencia más profunda dentro de la afirmación misma. En otras palabras, la fiabilidad no surge de respuestas uniformes, sino del examen estructurado de las diferencias en el razonamiento.
Para hacer esto posible, las salidas complejas de IA deben primero descomponerse en componentes verificables más pequeños. Un resumen de investigación generado se convierte en una serie de declaraciones rastreables, una explicación legal se transforma en una secuencia de afirmaciones interpretativas, un análisis financiero se separa en afirmaciones cuantificables que pueden ser verificadas de manera independiente. Cada uno de estos fragmentos puede luego ser evaluado por modelos separados, permitiendo que el sistema mapee no solo si la respuesta general parece correcta, sino qué elementos específicos resisten el escrutinio y cuáles requieren reconsideración.
Este cambio puede parecer sutil, pero representa un cambio profundo en dónde reside la confianza dentro de un sistema de IA. Los pipelines tradicionales concentran la autoridad dentro del modelo mismo: si el modelo funciona bien, el sistema funciona bien; si falla, todo el proceso colapsa. Mira distribuye esa responsabilidad a través de una capa de gobernanza que evalúa afirmaciones antes de que se solidifiquen en salidas. En este entorno, la credibilidad no proviene de la puntuación de confianza de un modelo, sino de la convergencia de caminos de razonamiento evaluados de manera independiente.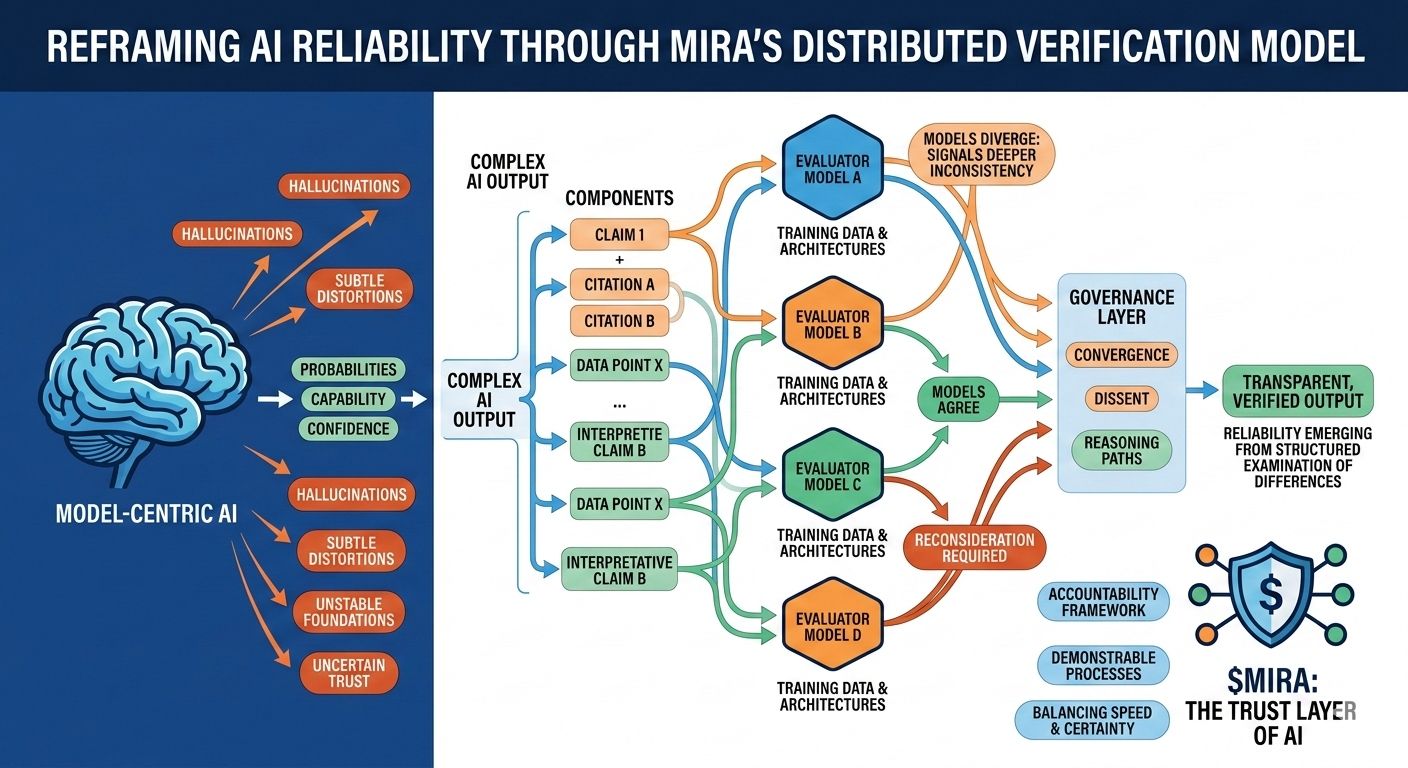
Por supuesto, distribuir la verificación no elimina todas las formas de error. Los modelos entrenados en conjuntos de datos similares pueden seguir reproduciendo información desactualizada y los sofisticados mensajes adversariales pueden explotar debilidades sistémicas compartidas entre arquitecturas. El consenso multi-modelo reduce la probabilidad de alucinaciones aleatorias, pero no puede prevenir completamente el error coordinado que surge de suposiciones compartidas incrustadas en el ecosistema de IA más amplio. Por esa razón, la transparencia se vuelve tan esencial como la verificación misma. Los usuarios deben entender si los modelos de verificación realmente representan perspectivas independientes o meras variaciones del mismo sistema subyacente.
Otra dimensión de este diseño radica en sus implicaciones económicas. La verificación no es gratuita: cada llamada adicional de modelo introduce costos computacionales, latencia y complejidad en la infraestructura. A medida que los sistemas de IA integran cada vez más capas de verificación, los desarrolladores deben tomar decisiones deliberadas sobre cuándo la validación profunda es necesaria y cuándo las respuestas rápidas son suficientes. Las aplicaciones construidas sobre IA verificada, por lo tanto, evolucionan en gestores de fiabilidad, equilibrando constantemente velocidad, costo y certeza mientras determinan qué salidas requieren un examen más profundo o supervisión humana.
Estos compromisos probablemente darán forma a cómo compiten las plataformas de IA en los próximos años. La capacidad por sí sola ya no definirá los sistemas más fuertes. En cambio, la capacidad de demostrar procesos de verificación transparentes, comunicar claramente la incertidumbre y exponer con gracia el desacuerdo entre modelos puede convertirse en las características definitorias de una infraestructura de IA confiable. Los sistemas que reconocen sus limitaciones mientras contienen sistemáticamente errores serán, en última instancia, más valiosos que aquellos que simplemente proyectan confianza.
Visto desde esta perspectiva, el modelo de Mira es menos sobre construir modelos individuales más inteligentes y más sobre construir un marco de responsabilidad en torno a la inteligencia de las máquinas misma. Las respuestas de IA se convierten en propuestas en lugar de declaraciones: declaraciones que deben pasar por una red de evaluadores independientes antes de ser aceptadas como salidas creíbles. En tal sistema, los errores siguen siendo inevitables, pero su impacto se contiene a través de mecanismos de verificación que identifican debilidades antes de que se propaguen a decisiones, sistemas financieros o discurso público.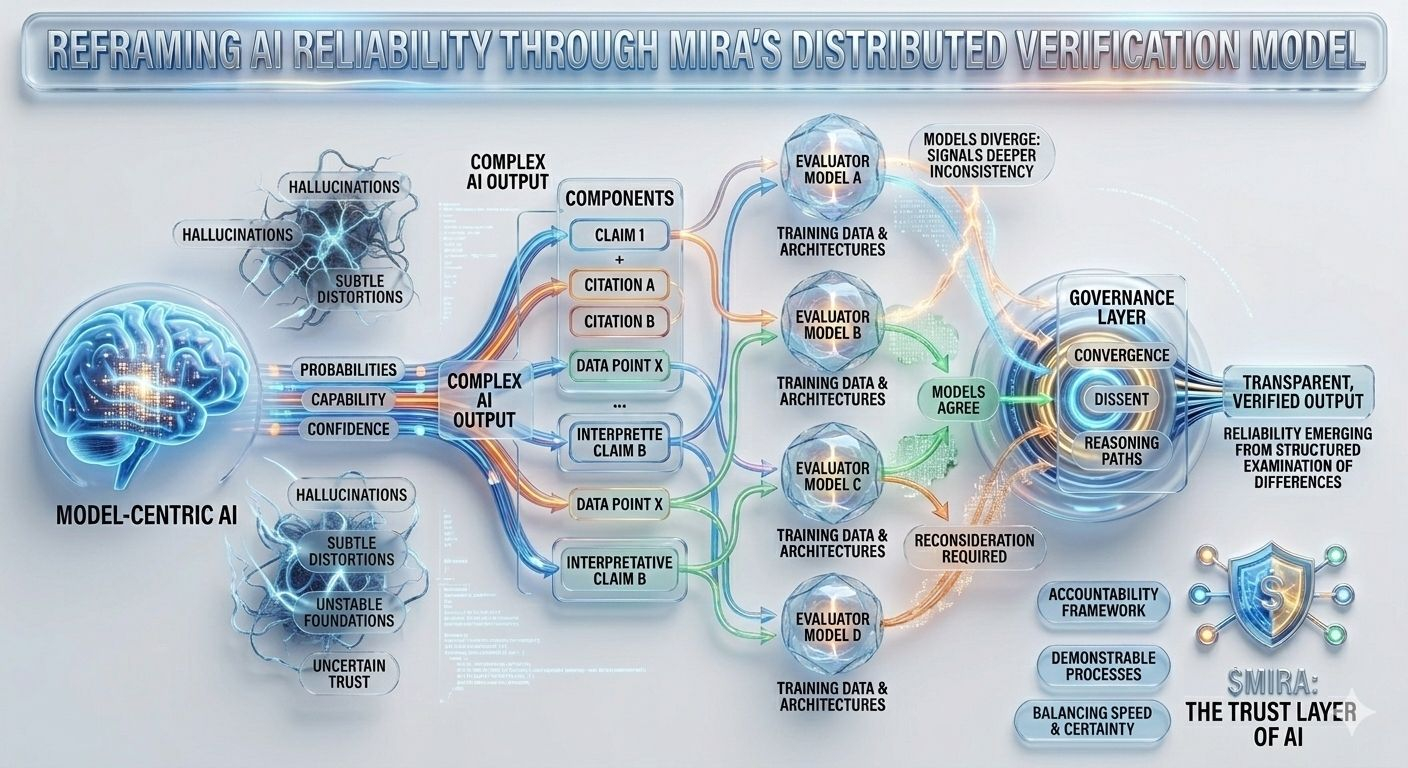
En última instancia, el futuro de la IA confiable puede depender menos de lograr un acuerdo perfecto entre modelos y más de definir cómo se interpreta ese acuerdo, cómo se analizan las señales disidentes y qué salvaguardas se activan cuando el consenso comienza a fracturarse. La verdadera medida de la confianza no será si las máquinas siempre producen la respuesta correcta, sino si los sistemas que las rodean están diseñados para cuestionar, probar y validar esas respuestas antes de que el mundo confíe en ellas.
$MIRA
