Cuando las personas hablan sobre la gestión del riesgo de la IA, la conversación suele saltar directamente a la regulación o a la alineación de modelos. Mi primera reacción es diferente. El verdadero problema a menudo no es si los sistemas de IA pueden ser guiados por reglas, sino si sus resultados pueden ser confiables en primer lugar. La mayoría de los sistemas de IA modernos producen respuestas rápidamente y de manera convincente, pero la fiabilidad subyacente sigue siendo incierta. Esa brecha entre la confianza y la corrección es donde comienza el verdadero riesgo.
El problema no es nuevo. Cualquiera que haya trabajado con grandes modelos de IA ha visto lo fácilmente que pueden producir información incorrecta mientras suenan autoritativos. Estos errores suelen describirse como alucinaciones, pero desde una perspectiva de riesgo representan algo más serio: decisiones no verificables que entran en flujos de trabajo reales. Cuando las salidas de la IA influyen en las finanzas, la atención médica, la gobernanza o la infraestructura, el costo de la incertidumbre crece rápidamente.
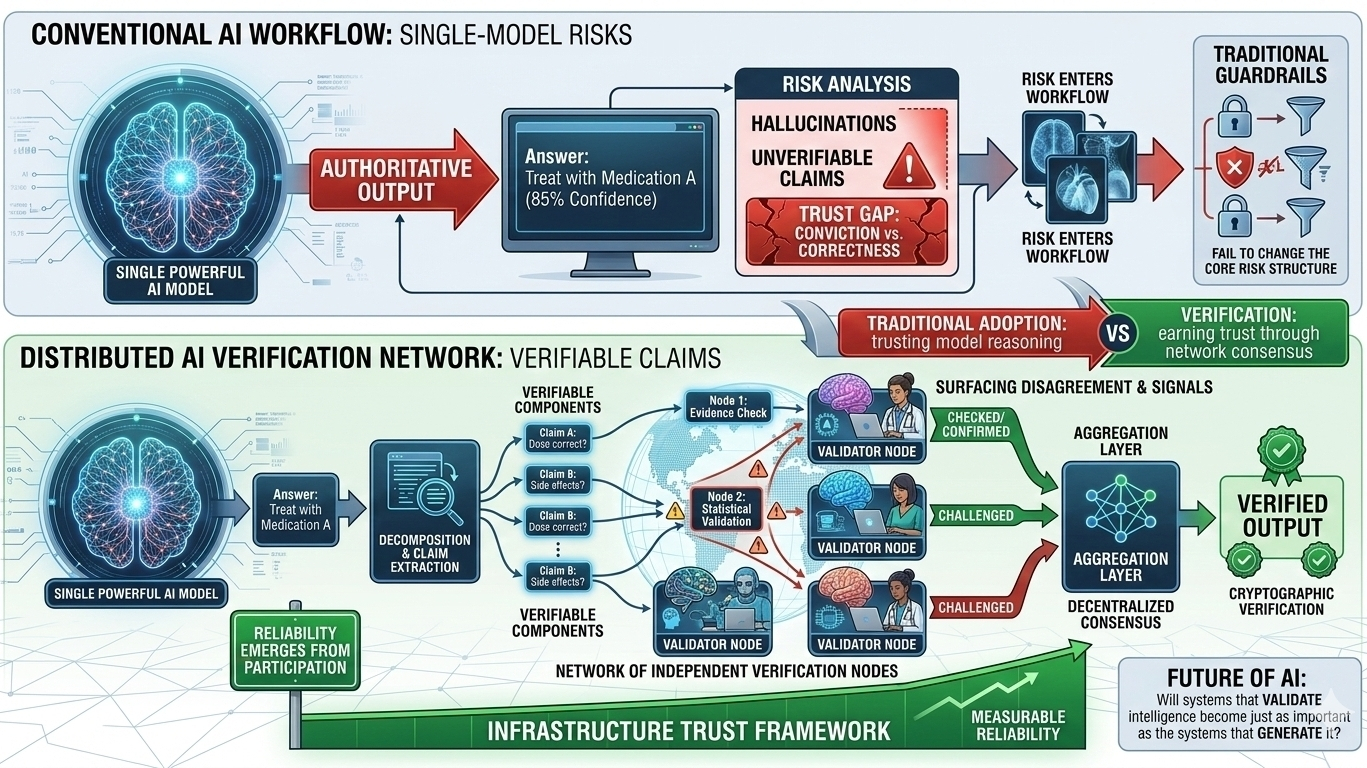
Los enfoques tradicionales para gestionar este riesgo suelen centrarse en mejorar el propio modelo. Los desarrolladores añaden barandillas, vuelven a entrenar modelos en conjuntos de datos curados o construyen sistemas de monitoreo para detectar comportamientos problemáticos. Estos esfuerzos ayudan, pero aún dependen en gran medida de confiar en el proceso de razonamiento de un único modelo. Cuando el mismo sistema que genera una respuesta también es responsable de validarla, la estructura del riesgo no cambia realmente.
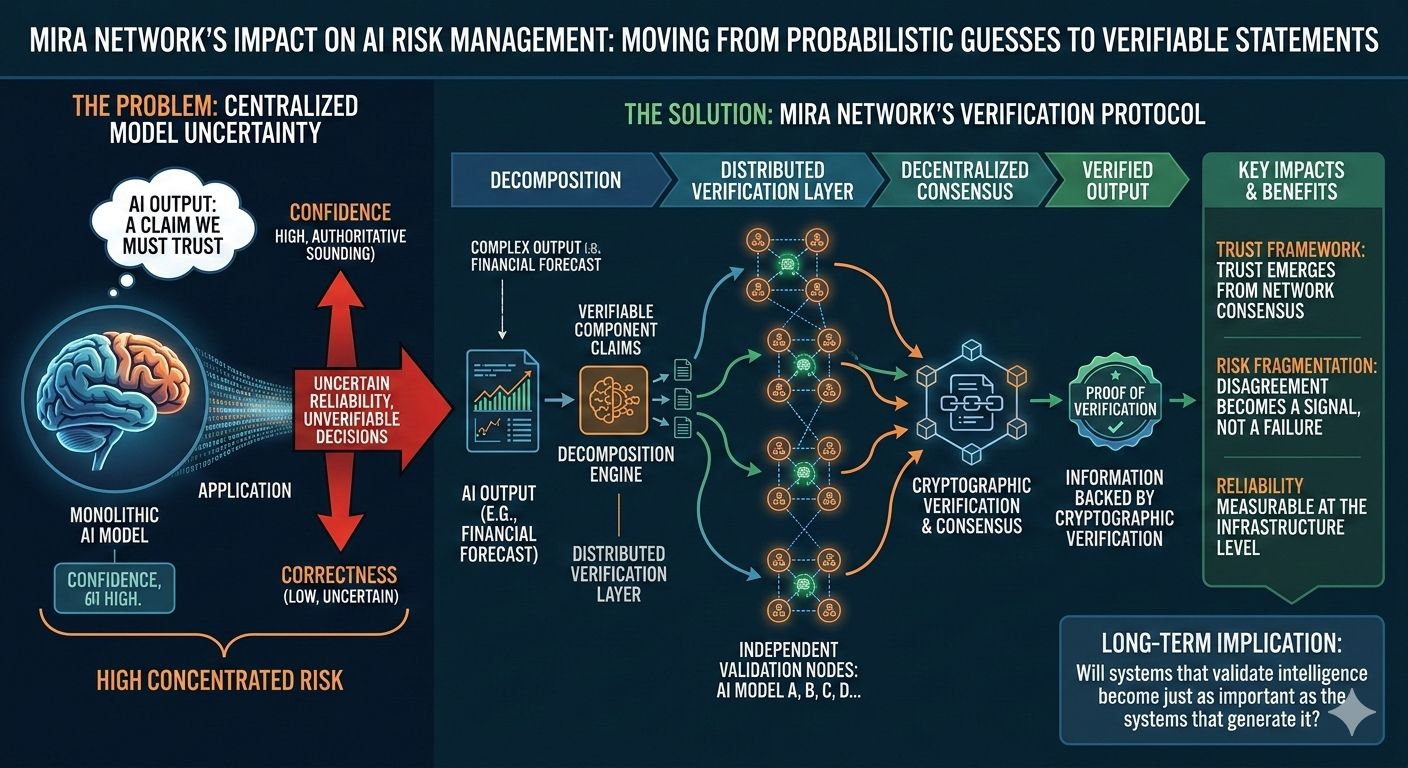
Aquí es donde la arquitectura detrás de Mira Network comienza a cambiar la conversación. En lugar de pedir a un modelo que genere y evalúe información, el protocolo descompone las salidas de IA en reclamos más pequeños que pueden ser verificados de forma independiente a través de una red distribuida de modelos. Cada reclamación se convierte en algo que puede ser revisado, desafiado o confirmado a través de un consenso descentralizado en lugar de aceptarse al pie de la letra.
La mecánica detrás de esto es sutil pero importante. Cuando un sistema de IA produce una respuesta compleja, se descompone en componentes verificables. Esos componentes se distribuyen a través de múltiples nodos de verificación independientes. Cada nodo evalúa la reclamación utilizando su propio proceso de razonamiento y la red agrega esas evaluaciones en un resultado de consenso. La salida final no es solo una respuesta, se convierte en un pedazo de información respaldado por verificación criptográfica.
Ese cambio altera cómo se distribuye el riesgo en todo el sistema. En arquitecturas de IA convencionales, el riesgo principal reside dentro de la capa de salida de un único modelo. Si ese modelo está equivocado, el error viaja directamente a la aplicación. En una red de verificación, el riesgo está fragmentado. Las reclamaciones individuales pueden ser desafiadas por múltiples evaluadores y el desacuerdo se convierte en una señal en lugar de un fallo. En lugar de ocultar la incertidumbre, el sistema la hace visible.
La parte interesante es cómo esto comienza a remodelar los incentivos en torno a la confiabilidad de la IA. En un modelo centralizado, las mejoras de precisión en la tubería dependen principalmente de la organización que entrena el modelo. En una capa de verificación descentralizada, la confiabilidad surge de la participación en la red. Los validadores independientes contribuyen al proceso de evaluación y el consenso determina qué reclamaciones son aceptadas. La confianza se convierte en una propiedad de la red en lugar de una promesa de un único proveedor.
Por supuesto, introducir una capa de verificación no elimina la complejidad. Crea nuevas consideraciones operativas. La velocidad de verificación, los incentivos para los validadores y los mecanismos de resolución de disputas se convierten en factores importantes para mantener la confiabilidad del sistema. Si la verificación se vuelve lenta o económicamente ineficiente, la experiencia del usuario sufre. Si los incentivos están mal diseñados, los validadores pueden priorizar comprobaciones fáciles sobre las significativas.
Pero incluso con esos desafíos, la dirección es notable porque cambia de dónde proviene la confianza. En lugar de confiar en que un poderoso modelo de IA “probablemente lo hizo bien”, el sistema pide a múltiples evaluadores independientes que confirmen la afirmación. Esa distinción puede parecer sutil, pero transforma las salidas de IA de suposiciones probabilísticas en declaraciones verificables.
Otra implicación es cómo esto afecta la relación entre los desarrolladores de IA y las aplicaciones que dependen de ellos. En el panorama actual, las aplicaciones dependen en gran medida de cualquier proveedor de modelo que integren. Si ese proveedor cambia de comportamiento o introduce errores, los sistemas heredan las consecuencias de inmediato. Una capa de verificación separa la generación de la validación, permitiendo que las aplicaciones se basen en información confirmada de forma independiente en lugar de salidas de modelos en bruto.
Esto comienza a mover la infraestructura de IA más cerca de algo que se asemeja a los marcos de confianza que se ven en los sistemas distribuidos. La información se vuelve más sólida cuando sobrevive múltiples rondas de verificación en lugar de cuando proviene de una única fuente poderosa. El resultado no es una certeza perfecta, sino una imagen mucho más clara de cuáles salidas son lo suficientemente confiables para decisiones del mundo real.
Desde la perspectiva de gestión de riesgos, el resultado más significativo puede ser cultural en lugar de técnico. Los sistemas de IA a menudo se tratan como herramientas autoritarias porque generan respuestas rápida y confiadamente. Las redes de verificación desafían esa suposición al convertir cada respuesta en una reclamación que debe ganar confianza a través del consenso.
Por lo tanto, el impacto real no es simplemente que las salidas de IA pueden ser verificadas. El cambio más profundo es que la confiabilidad se vuelve medible a nivel de infraestructura. En lugar de preguntar si un modelo es generalmente preciso, los desarrolladores pueden preguntar si una reclamación específica ha sido verificada de forma independiente.
Y eso plantea una pregunta a largo plazo más interesante: si las salidas de IA requieren cada vez más capas de verificación para ser confiables, ¿se volverán los sistemas que validan la inteligencia tan importantes como los sistemas que la generan?
@Mira - Trust Layer of AI #Mira

