
El 16 de marzo de 2026, se inaugurará oficialmente la conferencia GTC 2026 de NVIDIA, donde el fundador y CEO de NVIDIA, Jensen Huang, dará un discurso principal.
En esta conferencia, considerada como la "peregrinación anual de la industria de la IA", Jensen Huang explicó la transformación de NVIDIA de una "empresa de chips" a una "empresa de infraestructura y fábricas de IA". Enfrentando las preocupaciones del mercado sobre la sostenibilidad del rendimiento y el espacio de crecimiento, Jensen Huang desglosó detalladamente la lógica comercial subyacente que impulsa el crecimiento futuro: la "economía de la fábrica de tokens".

La guía de rendimiento es extremadamente optimista, "demanda de al menos 10 billones de dólares para 2027"
En los últimos dos años, la demanda global de computación de IA ha crecido exponencialmente. A medida que los grandes modelos evolucionan de la "percepción" y la "generación" al "razonamiento" y la "acción (ejecución de tareas)", el consumo de potencia de cálculo se ha disparado. Respecto a los límites de pedidos e ingresos que preocupan enormemente al mercado, Huang Renxun ha expresado expectativas muy optimistas.
En su discurso, Huang Renxun afirmó con franqueza:
Por estas fechas el año pasado, dije que veíamos una demanda de 500 mil millones de dólares con alta probabilidad de éxito, que abarcaba a Blackwell y Rubin hasta 2026. Ahora, aquí y ahora, veo una demanda de al menos 1 billón de dólares hasta 2027.
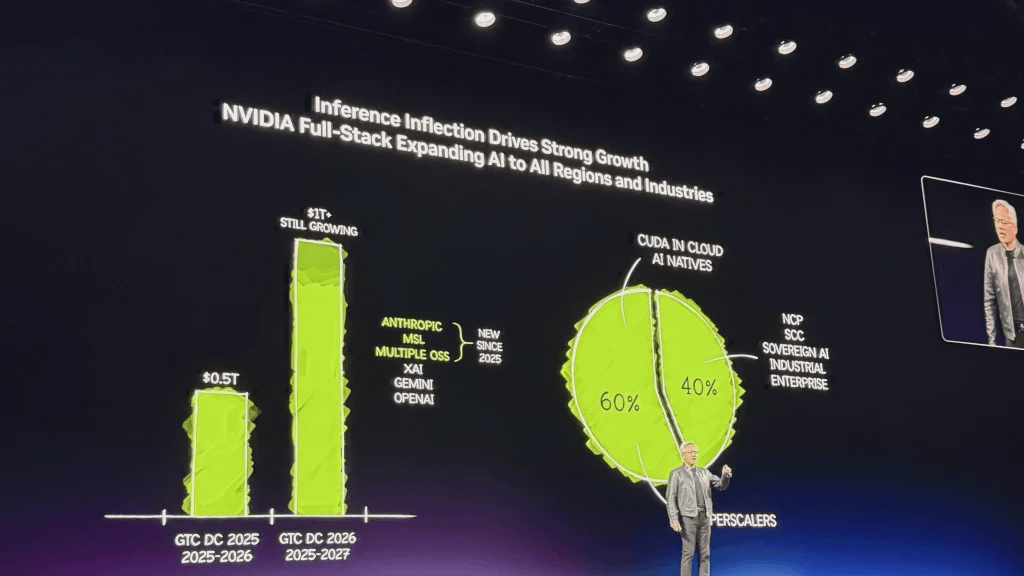
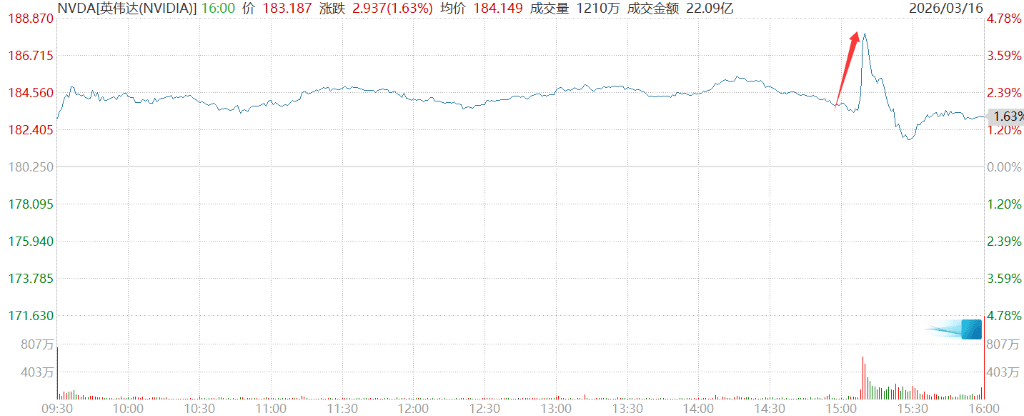
La previsión de Jensen Huang de alcanzar un billón de dólares impulsó en su momento el precio de las acciones de Nvidia en más de un 4,3%.
Además, añadió a esta cifra:
¿Es esto razonable? De eso hablaré a continuación. De hecho, podríamos incluso enfrentarnos a una escasez de suministro. Estoy seguro de que la demanda real de computación será mucho mayor.
Jensen Huang señaló que los sistemas de Nvidia han demostrado ser la infraestructura de menor coste del mundo. Gracias a su capacidad para ejecutar modelos de IA en prácticamente cualquier ámbito, esta versatilidad permite aprovechar al máximo el billón de dólares invertidos por los clientes y garantizar una larga vida útil.
Actualmente, el 60% del negocio de Nvidia proviene de los cinco principales proveedores de servicios en la nube a hiperescala, mientras que el 40% restante se distribuye ampliamente entre diversos campos como la nube soberana, las empresas, la industria, la robótica y la computación perimetral.
Economía de Token Factory: El rendimiento por vatio determina la supervivencia del negocio.
Para explicar la lógica detrás de esta demanda de billones de dólares, Jensen Huang presentó una mentalidad empresarial completamente nueva a los directores ejecutivos de empresas globales. Señaló que los centros de datos del futuro ya no serán almacenes para guardar archivos, sino "fábricas" para producir tokens (las unidades básicas generadas por la IA).

Huang Renxun enfatizó:
Por definición, todo centro de datos y toda fábrica tiene un consumo energético limitado. Una fábrica de 1 GW nunca llegará a ser de 2 GW; es una ley física y atómica. A un nivel de potencia fijo, quien tenga el mayor rendimiento por vatio tendrá el menor coste de producción.
Jensen Huang divide los servicios de IA del futuro en cuatro niveles de negocio:
Nivel gratuito (alto rendimiento, baja velocidad)
Nivel intermedio (aproximadamente 3 dólares por millón de tokens)
Nivel avanzado (aproximadamente 6 dólares por millón de tokens)
Capa de alta velocidad (aproximadamente 45 dólares por millón de tokens)
Capa de ultra alta velocidad (aproximadamente 150 dólares por millón de tokens)
Señaló que, a medida que los modelos se vuelven más grandes y los contextos más extensos, la IA se volverá más inteligente, pero la tasa de generación de tokens disminuirá. Jensen Huang afirmó:
En esta fábrica de tokens, su rendimiento y velocidad de generación de tokens se traducirán directamente en sus ingresos exactos el próximo año.
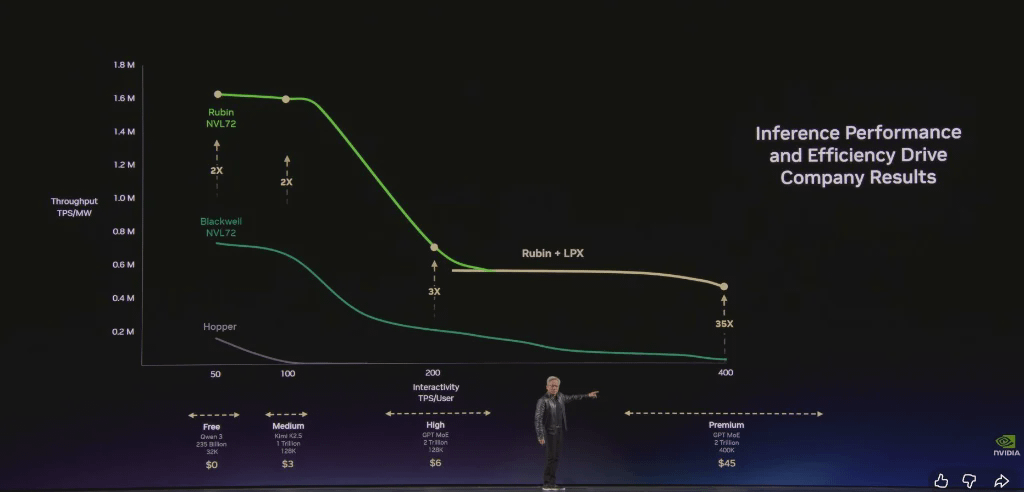
Jensen Huang destacó que la arquitectura de NVIDIA permite a los clientes alcanzar un rendimiento extremadamente alto en el nivel gratuito, al tiempo que aumenta el rendimiento hasta 35 veces en el nivel de inferencia de mayor valor.
Vera Rubin logra una aceleración de 350 veces en dos años; Groq cubre la necesidad de un razonamiento ultrarrápido.
Bajo las limitaciones de estos límites físicos, NVIDIA presentó Vera Rubin, su sistema de computación de IA más complejo hasta la fecha. Jensen Huang declaró:
Antes, cuando mencionaba a Hopper, mostraba un chip, lo cual resultaba bastante gracioso. Pero cuando mencionaba a Vera Rubin, la gente pensaba en todo el sistema. En este sistema 100% refrigerado por líquido, que elimina por completo los cables tradicionales, un rack que antes tardaba dos días en instalarse ahora se puede montar en tan solo dos horas.
Jensen Huang señaló que, mediante un codiseño integral de hardware y software, Vera Rubin logró un asombroso salto en el procesamiento de datos dentro del mismo centro de datos de 1 GW:
En tan solo dos años, aumentamos la tasa de generación de tokens de 22 millones a 700 millones, un incremento de 350 veces. La Ley de Moore solo proporcionó un incremento de aproximadamente 1,5 veces durante el mismo período.
Para abordar los cuellos de botella de ancho de banda en condiciones de inferencia de velocidad extremadamente alta (como 1000 tokens/segundo), NVIDIA presentó su solución final mediante la integración de su empresa adquirida Groq: inferencia asimétrica desacoplada. Jensen Huang explicó:
Estos dos procesadores tienen características muy diferentes. El chip Groq tiene 500 MB de SRAM, mientras que el chip Rubin tiene 288 GB de memoria.

Jensen Huang señaló que NVIDIA, a través de su sistema de software Dynamo, delega la etapa de "precarga", que requiere una gran capacidad de cálculo y memoria, a Vera Rubin, y la etapa de "decodificación", sensible a la latencia, a Groq. Huang también ofreció sugerencias para la configuración de la potencia de cálculo empresarial:
Si su trabajo implica principalmente un alto rendimiento, utilice Vera Rubin al 100%; si tiene una gran demanda de generación de tokens de alto valor a nivel programático, asigne el 25% del espacio de su centro de datos a Groq.
Se ha revelado que el chip Groq LP30, fabricado por Samsung, ya se encuentra en producción en masa y se espera que se envíe en el tercer trimestre, mientras que el primer rack de Vera Rubin ya está funcionando en la nube de Microsoft Azure.
Además, en lo que respecta a la tecnología de interconexión óptica, Jensen Huang presentó el primer conmutador óptico coempaquetado (CPO) de producción en masa del mundo, el Spectrum X, calmando así el debate del mercado sobre el enfoque de "salida de cobre, entrada de fibra".
Necesitamos mayor capacidad de producción de cables de cobre, mayor capacidad de producción de chips ópticos y mayor capacidad de producción de CPO.
Los agentes están dejando atrás el SaaS tradicional; el "salario anual + ficha" se ha convertido en el estándar en Silicon Valley.
Más allá de las barreras de hardware, Huang dedicó una parte importante de su análisis a la revolución del software y los ecosistemas de IA, en particular al surgimiento de los agentes.
Describió el proyecto de código abierto OpenClaw como "el proyecto de código abierto más popular de la historia de la humanidad", afirmando que superó los logros de Linux de los últimos 30 años en tan solo unas semanas. Huang declaró sin rodeos que OpenClaw es esencialmente un "sistema operativo" para ordenadores agentes.
Huang Renxun afirmó:
Todas las empresas de SaaS (Software como servicio) se convertirán en empresas de AaaS (Agente como servicio). Sin duda, para garantizar el despliegue seguro de estos agentes capaces de acceder a datos confidenciales y ejecutar código, NVIDIA ha lanzado el diseño de referencia NeMo Claw de nivel empresarial, que incorpora un motor de políticas y un enrutador de privacidad.
Para los profesionales comunes y corrientes, esta transformación también está a la vuelta de la esquina. Jensen Huang describe una nueva forma de lugar de trabajo para el futuro:
En el futuro, cada ingeniero de nuestra empresa necesitará un presupuesto anual para Tokens. Su salario base anual podría ser de varios cientos de miles de dólares, y yo destinaré aproximadamente la mitad de esa cantidad a Tokens para que logren una mejora de eficiencia diez veces mayor. Esta ya es la nueva táctica de contratación en Silicon Valley: ¿cuántos Tokens incluye tu oferta?
Al final de su discurso, Jensen Huang también ofreció un adelanto de la arquitectura informática de próxima generación, Feynman, que será la primera en lograr la escalabilidad horizontal tanto de los cables de cobre como del CPO. Aún más interesante es el desarrollo por parte de Nvidia de "Vera Rubin Space-1", un centro de datos desplegado en el espacio, que abre por completo las posibilidades de extender la capacidad de computación de la IA más allá de la Tierra.
A continuación, el texto completo del discurso de Jensen Huang en la GTC 2026, traducido (con ayuda de herramientas de IA):
Presentador: Demos la bienvenida a Jensen Huang, fundador y director ejecutivo de Nvidia, al escenario.
Jensen Huang, Fundador y Director Ejecutivo:
Bienvenidos a GTC. Quiero recordarles a todos que esta es una conferencia de tecnología. Me complace ver a tanta gente haciendo fila para entrar esta mañana y verlos a todos aquí hoy.
En GTC, nos centraremos en tres temas principales: tecnología, plataformas y ecosistema. NVIDIA cuenta actualmente con tres plataformas principales: la plataforma CUDA-X, la plataforma de sistema y nuestra plataforma AI Factory, lanzada recientemente.
Antes de dar comienzo oficialmente, quiero agradecer a nuestros presentadores: Sarah Guo de Conviction, Alfred Lin de Sequoia Capital (el primer inversor de capital riesgo de Nvidia) y Gavin Baker, el primer gran inversor institucional de Nvidia. Estos tres poseen un profundo conocimiento de la tecnología y ejercen una gran influencia en todo el ecosistema tecnológico. Por supuesto, también quiero agradecer a todos los distinguidos invitados que he invitado personalmente a asistir hoy. Gracias a este equipo excepcional.
También quisiera agradecer a todas las empresas presentes hoy. NVIDIA es una empresa de plataformas; contamos con tecnología, plataformas y un amplio ecosistema. Las empresas presentes hoy representan a casi todos los actores de esta industria de 100 billones de dólares, y estamos profundamente agradecidos a las 450 empresas que patrocinaron este evento.
Esta conferencia contará con 1000 foros técnicos y 2000 ponentes, que abarcarán todas las capas de la arquitectura de "cinco capas" de la inteligencia artificial, desde la infraestructura como terrenos, electricidad y centros de datos, hasta chips, plataformas, modelos y las diversas aplicaciones que, en última instancia, impulsan toda la industria.
CUDA: Veinte años de acumulación tecnológica
Todo comenzó aquí. Este año se cumple el 20 aniversario de CUDA.
Durante dos décadas, nos hemos dedicado al desarrollo de esta arquitectura. CUDA es una invención revolucionaria: la tecnología SIMT (Single Instruction, Multithreaded) permite a los desarrolladores escribir programas en código escalar y extenderlos a aplicaciones multihilo, lo que facilita enormemente la programación en comparación con la arquitectura SIMD anterior. Recientemente, incorporamos Tiles para ayudar a los desarrolladores a programar con mayor facilidad los Tensor Cores y las diversas estructuras matemáticas en las que se basa la inteligencia artificial actual. Actualmente, CUDA cuenta con miles de herramientas, compiladores, marcos de trabajo y bibliotecas, cientos de miles de proyectos públicos en la comunidad de código abierto y está profundamente integrada en todos los ecosistemas tecnológicos.
Este gráfico revela la lógica estratégica de NVIDIA al 100%, y he estado presentando esta diapositiva desde el principio. El elemento más difícil y fundamental de lograr son los "sistemas instalados" en la parte inferior del gráfico. En las últimas dos décadas, hemos acumulado cientos de millones de GPU y sistemas informáticos que ejecutan CUDA en todo el mundo.
Nuestras GPU cubren todas las plataformas en la nube y dan servicio a casi todos los fabricantes de ordenadores e industrias. La enorme base instalada de CUDA es la razón fundamental por la que este ciclo virtuoso se acelera continuamente. Esta base instalada atrae a desarrolladores, quienes crean nuevos algoritmos y logran avances significativos. Estos avances generan nuevos mercados, que a su vez forman nuevos ecosistemas y atraen a más empresas, expandiendo aún más la base instalada. Este ciclo virtuoso se acelera constantemente.
Las descargas de las bibliotecas de NVIDIA están creciendo a un ritmo asombroso, a gran escala y a un ritmo cada vez mayor. Este efecto multiplicador permite que nuestra plataforma informática admita una enorme cantidad de aplicaciones y un flujo constante de nuevos avances.
Más importante aún, también otorga a estas infraestructuras una vida útil extremadamente larga. La razón es obvia: las aplicaciones que pueden ejecutarse en NVIDIA CUDA son increíblemente diversas, abarcando todas las etapas del ciclo de vida de la IA, diversas plataformas de procesamiento de datos y una amplia gama de solucionadores científicos. Por lo tanto, una vez instalada una GPU NVIDIA, su valor práctico es extremadamente alto. Por eso, el precio en la nube de nuestras GPU con arquitectura Ampere, que lanzamos hace seis años, ha aumentado.
La clave de todo esto reside en nuestra enorme base instalada, nuestra potente arquitectura de volante de inercia y nuestro extenso ecosistema de desarrolladores. Cuando estos factores se combinan, junto con nuestras actualizaciones de software continuas, los costes de computación disminuyen progresivamente. La computación acelerada mejora significativamente el rendimiento de las aplicaciones y, gracias a nuestro mantenimiento a largo plazo y la iteración del software, los usuarios no solo experimentan mejoras iniciales en el rendimiento, sino que también disfrutan de reducciones constantes en los costes de computación. Nos comprometemos a brindar soporte a largo plazo para todas las GPU a nivel mundial, ya que son compatibles arquitectónicamente.
Estamos dispuestos a hacerlo debido a la enorme cantidad de instalaciones: cada nueva versión optimizada beneficia a millones de usuarios. Esta combinación dinámica permite que las arquitecturas de NVIDIA expandan continuamente su alcance y aceleren su propio crecimiento, al tiempo que reducen los costos de computación, lo que en última instancia estimula un nuevo crecimiento. CUDA es la clave de todo esto.
De GeForce a CUDA: una evolución de 25 años
Nuestra colaboración con CUDA comenzó hace 25 años.
GeForce: muchos de ustedes crecieron con GeForce. GeForce es el programa de marketing más exitoso de NVIDIA. Empezamos a cultivar clientes potenciales cuando no podían permitirse nuestros productos; sus padres se convirtieron en los primeros usuarios de NVIDIA, comprando nuestros productos año tras año, hasta que un día se convirtieron en excelentes informáticos y en verdaderos clientes y desarrolladores.
Esta es la base que GeForce sentó hace 25 años. Hace veinticinco años, inventamos el sombreador programable, una invención obvia pero trascendental que hizo programables los aceleradores, y el primer acelerador programable del mundo, el sombreador de píxeles. Cinco años después, creamos CUDA, una de las inversiones más importantes que jamás hayamos realizado. Con recursos limitados, invertimos la gran mayoría de nuestras ganancias en extender CUDA de GeForce a todos los ordenadores. Estábamos tan decididos porque creíamos en su potencial. A pesar de las dificultades iniciales, la empresa mantuvo esta convicción durante 13 generaciones, dos décadas completas, y hoy CUDA es omnipresente.
Fue el sombreador de píxeles lo que impulsó la revolución GeForce. Y hace unos ocho años, presentamos RTX, una renovación arquitectónica completa para la era moderna de los gráficos por computadora. GeForce trajo CUDA al mundo, y fue gracias a esto que muchos investigadores, incluidos Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton y Andrew Ng, descubrieron que las GPU podían ser una herramienta poderosa para acelerar el aprendizaje profundo, lo que desencadenó la explosión de la IA hace una década.
Hace diez años, decidimos combinar el sombreado programable con dos conceptos totalmente nuevos: el trazado de rayos por hardware, que supuso un desafío técnico enorme; y una idea vanguardista para la época: prevemos hace aproximadamente una década que la IA revolucionaría los gráficos por ordenador. Del mismo modo que GeForce introdujo la IA en el mundo, ahora la IA, a su vez, transformará la forma en que se implementan los gráficos por ordenador.
Hoy les voy a mostrar el futuro. Esta es nuestra tecnología gráfica de próxima generación, que llamamos Neural Rendering: una profunda fusión de gráficos 3D e inteligencia artificial. Esto es DLSS 5, por favor, échenle un vistazo.
Renderizado neuronal: la fusión de datos estructurados e IA generativa
¿No es impresionante? Los gráficos por computadora han cobrado vida.
¿Qué hicimos? Combinamos gráficos 3D controlables (la base del mundo virtual) con sus datos estructurados e incorporamos inteligencia artificial generativa y computación probabilística. Una es completamente determinista, la otra probabilística pero altamente realista; fusionamos estos dos conceptos, logrando un control preciso mediante datos estructurados y generando contenido en tiempo real. En definitiva, el contenido es visualmente impresionante y totalmente controlable.
El concepto de integrar información estructurada con IA generativa seguirá cobrando fuerza en diversos sectores. Los datos estructurados son la piedra angular de una IA fiable.
Plataforma de aceleración para datos estructurados y no estructurados
Ahora les voy a mostrar un diagrama de arquitectura técnica.
Los datos estructurados —plataformas conocidas como SQL, Spark, Pandas y Velox, así como plataformas importantes como Snowflake, Databricks, Amazon EMR, Azure Fabric y Google BigQuery— procesan marcos de datos. Estos marcos de datos son como hojas de cálculo gigantes que contienen toda la información del mundo empresarial y representan la realidad de la informática empresarial.
En la era de la IA, necesitamos capacitar a la IA para que utilice datos estructurados y acelere su procesamiento al máximo. Anteriormente, acelerar el procesamiento de datos estructurados tenía como objetivo mejorar la eficiencia de las empresas. En el futuro, la IA utilizará estas estructuras de datos a velocidades muy superiores a las humanas, y los agentes de IA harán un uso extensivo de las bases de datos estructuradas.
En lo que respecta a los datos no estructurados, las bases de datos vectoriales, los PDF, los vídeos y el audio constituyen la gran mayoría de los formatos de datos a nivel mundial; aproximadamente el 90 % de los datos generados cada año no están estructurados. En el pasado, estos datos eran prácticamente inutilizables: los leíamos, los almacenábamos en sistemas de archivos y ahí terminaba todo. No podíamos consultarlos y era difícil recuperarlos porque los datos no estructurados carecían de métodos de indexación sencillos; teníamos que comprender su significado y contexto. Ahora, la IA puede hacerlo: mediante tecnología de percepción y comprensión multimodal, la IA puede leer documentos PDF, comprender su significado e integrarlos en una estructura más amplia que permita realizar consultas.
Nvidia creó dos bibliotecas base para este propósito:
cuDF: Se utiliza para el procesamiento acelerado de marcos de datos y datos estructurados.
cuVS: Se utiliza para el almacenamiento de vectores, datos semánticos y el procesamiento de datos de IA no estructurados.
Estas dos plataformas se convertirán en una de las plataformas fundamentales más importantes del futuro.
Hoy anunciamos alianzas con varias empresas. IBM, creadora del lenguaje SQL, utilizará cuDF para acelerar su plataforma WatsonX Data. Dell se ha asociado con nosotros para desarrollar la plataforma Dell AI Data, integrando cuDF y cuVS, y ha logrado mejoras de rendimiento significativas en proyectos reales de NTT Data. En Google Cloud, estamos acelerando no solo Vertex AI, sino también BigQuery, y nos hemos asociado con Snapchat para reducir sus costos de computación en casi un 80 %.
Las ventajas de la computación acelerada son triples: velocidad, escalabilidad y coste. Esto concuerda con la lógica de la Ley de Moore: lograr avances significativos en el rendimiento mediante la computación acelerada, optimizando continuamente los algoritmos para que todos puedan beneficiarse de la constante disminución de los costes computacionales.
NVIDIA ha desarrollado una plataforma de computación acelerada que integra numerosas bibliotecas, entre ellas RTX, cuDF y cuVS. Estas bibliotecas están integradas en servicios globales en la nube y redes de fabricantes de equipos originales (OEM), llegando a usuarios de todo el mundo.
Estrecha cooperación con los proveedores de servicios en la nube.
Alianzas con los principales proveedores de servicios en la nube.
Google Cloud: Aceleramos Vertex AI y BigQuery, nos integramos profundamente con JAX/XLA y destacamos en PyTorch. NVIDIA es el único acelerador a nivel mundial que destaca tanto en PyTorch como en JAX/XLA. Hemos incorporado clientes como Base10, CrowdStrike, Puma y Salesforce al ecosistema de Google Cloud.
AWS: Estamos acelerando EMR, SageMaker y Bedrock, que están profundamente integrados con AWS. Lo que más me entusiasma este año es que llevaremos OpenAI a AWS, lo que impulsará significativamente el crecimiento del consumo de computación en la nube de AWS y ayudará a OpenAI a expandir sus implementaciones regionales y su capacidad de procesamiento.
Microsoft Azure: La supercomputadora NVIDIA de 100 PFLOPS es la primera que construimos y la primera que implementamos en Azure, sentando una base importante para nuestra colaboración con OpenAI. Estamos acelerando los servicios en la nube de Azure y AI Foundry, colaborando en la expansión de la región de Azure y trabajando intensamente en la búsqueda de Bing. Cabe destacar que nuestras capacidades de **Computación Confidencial**, que garantizan que ni siquiera los operadores puedan ver los datos y modelos de los usuarios, convierten a las GPU de NVIDIA en unas de las primeras del mundo en admitir la computación confidencial, lo que permite la implementación segura de modelos de OpenAI y Anthropic en entornos de nube en todo el mundo. Por ejemplo, con Synopsys, aceleramos sus flujos de trabajo completos de EDA y CAD y los implementamos en Microsoft Azure.
Oracle: Fuimos el primer cliente de IA de Oracle, y me enorgullece haber sido el primero en explicarles el concepto de nube de IA. Desde entonces, han crecido rápidamente y les hemos conseguido muchos socios, entre ellos Cohere, Fireworks y OpenAI.
CoreWeave: La primera nube nativa de IA del mundo, diseñada específicamente para el alojamiento de GPU y servicios de IA en la nube, cuenta con una excelente base de clientes y un fuerte impulso de crecimiento.
Palantir + Dell: Las tres partes han creado conjuntamente una plataforma de IA totalmente nueva basada en la plataforma de ontología y la plataforma de IA de Palantir, que puede implementar IA en cualquier país y en cualquier entorno de aislamiento físico de forma totalmente localizada, abarcando todo, desde el procesamiento de datos (vectorización o estructuración) hasta la pila completa de computación acelerada para IA.
NVIDIA ha establecido esta alianza especial con proveedores globales de servicios en la nube: llevamos a los clientes a la nube, creando un ecosistema mutuamente beneficioso.
Integración vertical y apertura horizontal: la estrategia central de Nvidia
Nvidia es la primera empresa del mundo integrada verticalmente y abierta horizontalmente.
La necesidad de este modelo es muy simple: la computación acelerada no es un problema de chips ni de sistemas; su descripción completa debería ser aceleración de aplicaciones. Las CPU pueden hacer que las computadoras funcionen más rápido en general, pero este camino ha llegado a su límite. En el futuro, solo la aceleración específica de aplicaciones o dominios podrá seguir ofreciendo mejoras de rendimiento y reducciones de costos.
Precisamente por eso, NVIDIA debe profundizar en una biblioteca tras otra, en un dominio tras otro y en un sector vertical tras otro. Somos una empresa de computación integrada verticalmente; no hay otra opción. Debemos comprender las aplicaciones, comprender los dominios, comprender a fondo los algoritmos y ser capaces de implementarlos en cualquier escenario: centros de datos, la nube, instalaciones locales, el borde e incluso sistemas robóticos.
Al mismo tiempo, NVIDIA mantiene un enfoque horizontalmente abierto, dispuesta a integrar su tecnología en la plataforma de cualquier socio, para que el mundo pueda disfrutar de los beneficios de la computación acelerada.
La estructura de asistentes a la GTC de este año ilustra perfectamente este punto. El sector de servicios financieros representó la mayor proporción de asistentes; esperamos ver desarrolladores, no operadores. Nuestro ecosistema abarca tanto la cadena de suministro ascendente como la descendente. Ya sea que una empresa tenga 50, 70 o 150 años, el año pasado fue su mejor año hasta la fecha. Estamos en el punto de partida de algo muy, muy significativo.
CUDA-X: Un motor de computación acelerada para diversas industrias
Nvidia tiene una fuerte presencia en diversos sectores verticales:
Conducción autónoma: un impacto amplio y de gran alcance.
Servicios financieros: La inversión cuantitativa está pasando de la ingeniería de características manual al aprendizaje profundo impulsado por supercomputadoras, lo que marca el comienzo de su "momento transformador".
Sector sanitario: Está entrando en su propio "momento ChatGPT", que abarca áreas como el descubrimiento de fármacos asistido por IA, los diagnósticos con soporte de IA y el servicio de atención al cliente en el sector sanitario.
Industria: La mayor ola de construcción del mundo está en marcha, con fábricas de inteligencia artificial, fábricas de chips y fábricas de centros de datos surgiendo por doquier.
Entretenimiento y juegos: La plataforma de IA en tiempo real admite traducción, transmisión en directo, interacción con juegos y agentes de compra inteligentes.
Robótica: Con más de una década de experiencia y un conjunto completo de tres arquitecturas informáticas principales (ordenador de entrenamiento, ordenador de simulación y ordenador de a bordo), se exhibieron 110 robots en esta exposición.
Telecomunicaciones: Un sector valorado en aproximadamente 2 billones de dólares, donde las estaciones base evolucionarán desde funciones de comunicación individuales hasta convertirse en plataformas de infraestructura de IA. Una de estas plataformas, Aerial, mantiene estrechas colaboraciones con empresas como Nokia y T-Mobile.
En el centro de todas estas áreas se encuentran nuestras bibliotecas CUDA-X, la base misma de NVIDIA como empresa de algoritmos. Estas bibliotecas son los activos más valiosos de la compañía, ya que permiten que la plataforma informática genere valor real en diversos sectores.
Una de las bibliotecas más importantes es cuDNN (CUDA Deep Neural Network Library), que revolucionó la inteligencia artificial y provocó una gran explosión en la IA moderna.
(Reproduciendo vídeo de demostración de CUDA-X)
Todo lo que acabas de ver fue una simulación, incluyendo el solucionador basado en la física, el modelo físico asistido por IA y el modelo físico del robot con IA. Todo fue simulación; no hubo animación dibujada a mano ni articulación de articulaciones. Esta es precisamente la capacidad principal de NVIDIA: aprovechar estas oportunidades mediante un profundo conocimiento de los algoritmos y la integración orgánica de las plataformas informáticas.
Las empresas nativas de IA y la nueva era de la informática.
Acabas de ver gigantes de la industria que definen la sociedad actual, como Walmart, L'Oréal, JPMorgan Chase, Roche y Toyota, así como un gran número de empresas de las que nunca habías oído hablar: lo que llamamos empresas nativas de IA. Esta lista es muy extensa e incluye a OpenAI, Anthropic y numerosas empresas emergentes que operan en diferentes sectores verticales.
El sector ha experimentado un crecimiento fenomenal en los últimos dos años. La inversión de capital riesgo en startups ha alcanzado la cifra récord de 150.000 millones de dólares. Y lo que es aún más importante, el tamaño de una sola inversión ha pasado de millones de dólares a cientos de millones, o incluso miles de millones, por primera vez. La razón es simple: por primera vez en la historia, todas las empresas de este sector requieren enormes cantidades de recursos informáticos y un gran número de tokens. El sector está creando, generando o añadiendo valor a los tokens de organizaciones como Anthropic y OpenAI.
Así como la revolución de los ordenadores personales, la revolución de internet y la revolución de la nube móvil dieron lugar a una serie de empresas que marcaron una época, esta generación de transformación de las plataformas informáticas también dará lugar a una serie de empresas muy influyentes que se convertirán en una fuerza importante en el mundo del futuro.
Tres avances históricos que impulsaron todo esto
¿Qué sucedió exactamente en los últimos dos años? Tres acontecimientos importantes.
Primero: ChatGPT, que marca el comienzo de la era de la IA generativa (finales de 2022 a 2023).
No solo puede percibir y comprender, sino también generar contenido único. Demostré la fusión de la IA generativa y los gráficos por computadora. La IA generativa transforma radicalmente nuestra forma de computar —pasando de la recuperación de información a la generación—, impactando profundamente la arquitectura informática, los métodos de implementación y el significado general.
Segundo: IA de razonamiento, representada por O1.
La capacidad de razonamiento permite a la IA reflexionar sobre sí misma, planificar y desglosar problemas, incluso aquellos que no comprende directamente, en pasos manejables. Esto hace que la IA generativa sea creíble y capaz de razonar basándose en información del mundo real. Para lograrlo, se incrementa significativamente el número de tokens en el contexto de entrada y el número de tokens de salida utilizados para el razonamiento, lo que conlleva un aumento sustancial de la complejidad computacional.
Tercero: Claude Code, el primer modelo de agente inteligente.
Puede leer archivos, escribir código, compilar, probar, evaluar e iterar. Claude Code ha revolucionado la ingeniería de software: el 100 % de los ingenieros de NVIDIA utilizan Claude Code, Codex y Cursor, o incluso más; ningún ingeniero de software prescinde de la ayuda de la IA.
Este es un punto de inflexión completamente nuevo: ya no se le pregunta a la IA "qué, dónde y cómo", sino que se le permite "crear, ejecutar y construir", lo que le permite usar herramientas de forma proactiva, leer archivos, analizar problemas y tomar medidas. La IA ha evolucionado de la percepción a la generación, al razonamiento, y ahora realmente puede lograr resultados.
En los últimos dos años, la demanda computacional necesaria para la inferencia se ha multiplicado por aproximadamente 10 000, mientras que el uso se ha incrementado por aproximadamente 100. Siempre he creído que la demanda computacional se ha multiplicado por un millón en los últimos dos años; es una opinión compartida por todos, por OpenAI y por Anthropic. Mayor capacidad de procesamiento se traduce en más tokens, mayores ingresos y una IA más inteligente. El punto de inflexión para la inferencia ha llegado.
La era de la infraestructura de IA de billones de dólares
El año pasado, por estas fechas, les decía que teníamos mucha confianza en la demanda y los pedidos de Blackwell y Rubin, que ascendían a aproximadamente 500 mil millones de dólares hasta 2026. Hoy, un año después de la GTC, les digo: de cara a 2027, preveo una cifra de al menos 1 billón de dólares. Y estoy convencido de que la demanda real de computación será mucho mayor.
2025: El año de la deducción de Nvidia
2025 es el Año de la Inferencia de NVIDIA. Nuestro objetivo es garantizar la excelencia en cada etapa del ciclo de vida de la IA, más allá del entrenamiento y el post-entrenamiento, lo que permitirá que nuestra infraestructura siga funcionando de manera eficiente con una vida útil efectiva más larga y un menor coste unitario.
Al mismo tiempo, Anthropic y Meta se unieron oficialmente a la plataforma NVIDIA, representando en conjunto un tercio de la demanda mundial de potencia de cálculo para IA. Los modelos de código abierto se acercan a niveles de vanguardia y son omnipresentes.
NVIDIA es actualmente la única plataforma del mundo capaz de ejecutar todos los modelos de IA en todos los campos de la inteligencia artificial: lenguaje, biología, gráficos por computadora, visión artificial, voz, proteínas y química, robótica, etc., tanto en el borde como en la nube, e independientemente del lenguaje. La arquitectura de NVIDIA es versátil en todos estos escenarios, lo que nos convierte en la plataforma más económica y confiable.
Actualmente, el 60 % del negocio de NVIDIA proviene de los cinco principales proveedores de servicios en la nube a hiperescala del mundo, mientras que el 40 % restante se distribuye entre diversos campos como la nube regional, la nube soberana, la empresa, la industria, la robótica y la computación perimetral. La amplitud de su cobertura en IA es la clave de su resiliencia; sin duda, se trata de una revolución totalmente nueva en la plataforma informática.
Grace Blackwell y NVLink 72: Innovación arquitectónica audaz.
Mientras la arquitectura Hopper aún estaba en su apogeo, decidimos rediseñar completamente el sistema, ampliando NVLink de 8 a 72 vías y descomponiendo y reconstruyendo exhaustivamente el sistema informático. Grace Blackwell: NVLink 72 fue una apuesta tecnológica arriesgada y no fue fácil para ninguno de nuestros socios. Queremos expresar nuestro sincero agradecimiento a todos los involucrados.
Al mismo tiempo, presentamos NVFP4, que no es un FP4 convencional, sino un tipo completamente nuevo de núcleo tensorial y unidad de cálculo. Hemos demostrado que NVFP4 puede realizar inferencias sin pérdida de precisión, a la vez que ofrece mejoras significativas en rendimiento y eficiencia energética, y es igualmente adecuado para el entrenamiento. Además, han surgido una serie de nuevos algoritmos como Dynamo y TensorRT-LLM, e incluso hemos invertido miles de millones de dólares en la construcción de una supercomputadora específica para la optimización de kernels, llamada DGX Cloud.
Los resultados demuestran nuestro extraordinario rendimiento en inferencia. Los datos de SemiAnalysis, la herramienta de evaluación comparativa de rendimiento de inferencia de IA más completa hasta la fecha, muestran a NVIDIA muy por delante tanto en tokens por vatio como en coste por token. La Ley de Moore podría haber arrojado una mejora de rendimiento de 1,5x para el H200, pero nosotros logramos 35x. Dylan Patel, de SemiAnalysis, incluso afirmó: «Huang está siendo conservador; en realidad es 50x». Y tiene razón.
Me gustaría citarlo aquí: "Jensen se anduvo con rodeos (Huang Renxun estaba siendo conservador en sus reportajes)".
El coste por token de Nvidia es el más bajo del mundo, sin parangón actualmente entre las empresas. La razón reside en su modelo de codiseño extremo.
Tomando como ejemplo Fireworks, antes de que NVIDIA actualizara por completo su software y algoritmos, su velocidad media de procesamiento de tokens era de unos 700 tokens por segundo; tras la actualización, alcanzó casi los 5000 tokens por segundo, una mejora de aproximadamente siete veces. Este es el poder del diseño colaborativo definitivo.
Fábrica de IA: Del centro de datos a la fábrica de tokens
Los centros de datos solían ser lugares para almacenar archivos; ahora son fábricas que producen tokens. En el futuro, todos los proveedores de servicios en la nube y todas las empresas de IA utilizarán la "eficiencia de la fábrica de tokens" como una métrica operativa clave.
Este es mi argumento principal:
Eje vertical: Rendimiento: Número de tokens generados por segundo a un nivel de potencia fijo.
Eje horizontal: Velocidad de token: la velocidad de respuesta de cada intento de inferencia. Cuanto mayor sea la velocidad, mayor será el modelo utilizable, más extenso el contexto y más inteligente la IA.
Este token es un nuevo producto que tendrá precios escalonados una vez que alcance su madurez.
Nivel gratuito (alto rendimiento, baja velocidad)
Nivel intermedio (aproximadamente 3 dólares por millón de tokens)
Nivel avanzado (aproximadamente 6 dólares por millón de tokens)
Capa de alta velocidad (aproximadamente 45 dólares por millón de tokens)
Capa de ultra alta velocidad (aproximadamente 150 dólares por millón de tokens)
En comparación con Hopper, Grace Blackwell ofrece un rendimiento 35 veces superior en el nivel de mayor valor e introduce niveles completamente nuevos. Utilizando un modelo simplificado, distribuyendo el 25 % de su potencia entre los cuatro niveles, Grace Blackwell podría generar 5 veces más ingresos que Hopper.
Vera Rubin: Sistema informático de IA de próxima generación
(Se reproduce un vídeo que presenta el sistema Vera Rubin)
Vera Rubin es un sistema completo, optimizado de principio a fin, diseñado específicamente para cargas de trabajo agenciales:
Núcleo de computación de modelos de lenguaje a gran escala: clúster de GPU NVLink 72, que gestiona el prellenado y la caché de clave-valor.
El nuevo procesador Vera: diseñado para un rendimiento excepcionalmente alto en tareas de un solo hilo, utiliza memoria LPDDR5 y ofrece una eficiencia energética extraordinaria. Es el único procesador para centros de datos del mundo que utiliza LPDDR5, lo que lo hace ideal para herramientas basadas en inteligencia artificial.
Sistema de almacenamiento: BlueField 4 + CX 9, una plataforma de almacenamiento totalmente nueva para la era de la IA, con una participación global del 100% en la industria del almacenamiento.
Switch CPO Spectrum X: El primer switch Ethernet óptico con encapsulado integrado del mundo, ahora en producción en masa a gran escala.
Kyber Rack: Un sistema de rack totalmente nuevo que admite 144 GPU que forman un único dominio NVLink, con computación frontal y conmutación NVLink posterior, conformando así una supercomputadora.
Rubin Ultra: Un nodo de supercomputación de última generación con un diseño de conexión vertical, compatible con racks Kyber y que admite interconexiones NVLink de mayor escala.
Vera Rubin ahora cuenta con refrigeración líquida al 100%, lo que reduce el tiempo de instalación de dos días a dos horas. Utiliza refrigeración por agua caliente a 45 °C, lo que disminuye significativamente la carga de refrigeración en los centros de datos. Me complace enormemente que Satya Nadella haya confirmado que el primer rack Vera Rubin ya está funcionando en Microsoft Azure.
Integración con Groq: La máxima extensión del rendimiento de la inferencia.
Adquirimos el equipo de Groq y obtuvimos una licencia tecnológica. Groq es un procesador de flujo de datos determinista que utiliza compilación estática y planificación del compilador, cuenta con una gran cantidad de SRAM, está optimizado para cargas de trabajo de inferencia única y ofrece una latencia extremadamente baja y una velocidad de generación de tokens extremadamente alta.
Sin embargo, la limitada capacidad de memoria de Groq (500 MB de SRAM integrada) dificulta el manejo independiente de los parámetros y la caché KV de modelos grandes, lo que limita su aplicación a gran escala.
La solución es Dynamo, un software de planificación de inferencias. Utilizamos Dynamo para desagregar el proceso de inferencia:
El prellenado y la decodificación del mecanismo de atención se realizan en Vera Rubin (lo que requiere una potencia de cálculo y un almacenamiento en caché KV considerables).
La decodificación de la red de alimentación directa, o la parte de generación de tokens, se realiza en Groq (lo que requiere un ancho de banda extremadamente alto y una latencia baja).
Ambos están estrechamente conectados mediante Ethernet, y un modo especial reduce la latencia a la mitad. Gracias a la programación unificada de Dynamo, el "sistema operativo de la fábrica de IA", el rendimiento general mejora 35 veces y se abre un nuevo nivel de rendimiento de inferencia que antes era inalcanzable con NVLink 72.
Recomendaciones de combinación de Groq y Vera Rubin:
Si la carga de trabajo es principalmente de alto rendimiento, utilice 100 % Vera Rubin.
Si una gran parte de la carga de trabajo implica la generación de tokens de alto valor, como código, se puede introducir Groq, con una proporción sugerida de aproximadamente 25 % Groq + 75 % Vera Rubin.
El Groq LP30 es fabricado por Samsung y actualmente se encuentra en producción en masa; se espera que los envíos comiencen en el tercer trimestre. Agradecemos a Samsung su total colaboración.
Un salto histórico en el rendimiento del razonamiento.
Cuantificando los avances tecnológicos previos: En dos años, la tasa de generación de tokens de una fábrica de IA de 1 gigavatio aumentará de 22 millones de tokens por segundo a 700 millones de tokens por segundo, un incremento de 350 veces. Este es el poder del diseño colaborativo definitivo.
Hoja de ruta tecnológica
Blackwell: Actualmente en producción, sistema de rack estándar Oberon, cableado de cobre extendido a NVLink 72, extensión óptica opcional a NVLink 576.
Vera Rubin (actual): rack Kyber, NVLink 144 (cable de cobre); rack Oberon, NVLink 72 + óptico, extendido a NVLink 576; Spectrum 6, el primer conmutador CPO del mundo.
Vera Rubin Ultra (próximamente): La GPU Rubin Ultra de próxima generación, con chip LP35 (que integra NVFP4 por primera vez), aumenta aún más el rendimiento varias veces.
Feynman (próxima generación): Una GPU completamente nueva, el chip LP40 (desarrollado conjuntamente por NVIDIA y el equipo Groq, que integra NVFP4); una CPU completamente nueva: Rosa (Rosalyn); BlueField 5; CX 10; y racks Kyber que admiten cableado de cobre y expansión CPO.
La hoja de ruta es clara: se están desarrollando tres vías en paralelo: expansión del cable de cobre, expansión de la fibra óptica (Scale-Up) y expansión de la fibra óptica (Scale-Out). Necesitamos que todos nuestros socios amplíen continuamente la capacidad de producción de cables de cobre, fibra óptica y CPO.
NVIDIA DSX: Una plataforma de gemelos digitales para la fábrica de IA
Las fábricas de IA son cada vez más complejas, pero los diversos proveedores de tecnología que las componen nunca han colaborado entre sí durante la fase de diseño, limitándose a "reunirse" en el centro de datos, lo cual claramente no es suficiente.
Con este fin, creamos Omniverse y la plataforma NVIDIA DSX, construida sobre ella: una plataforma para que todos los socios diseñen y operen conjuntamente fábricas de IA a escala de gigavatios en un mundo virtual. DSX ofrece:
Sistemas de simulación mecánica, térmica, eléctrica y de red a nivel de rack
La conexión a la red eléctrica permite una gestión coordinada del ahorro energético.
Optimización dinámica del consumo de energía y la refrigeración en centros de datos basada en Max-Q
Según estimaciones conservadoras, este sistema podría mejorar la eficiencia energética aproximadamente al doble, un beneficio muy significativo a la escala que estamos considerando. Comenzando con Digital Earth, Omniverse admitirá gemelos digitales de todos los tamaños, y estamos colaborando con socios globales para construir la computadora más grande de la historia.
Además, Nvidia se está adentrando en el espacio. Los chips Thor han recibido la certificación de resistencia a la radiación y ya están en funcionamiento en satélites. Colaboramos con socios para desarrollar Vera Rubin Space-1, destinado a la construcción de centros de datos espaciales. La gestión térmica es un desafío clave en el espacio, donde la disipación del calor depende exclusivamente de la radiación, y estamos reuniendo a ingenieros de primer nivel para afrontar este reto.
OpenClaw: El sistema operativo para la era de los agentes inteligentes
Peter Steinberger desarrolló un software llamado OpenClaw. Este es el proyecto de código abierto más popular de la historia, superando en tan solo unas semanas los logros de Linux tras treinta años de trayectoria.
OpenClaw es esencialmente un sistema con capacidad de agencia:
Gestión de recursos, acceso a herramientas, sistemas de archivos y modelos de lenguaje de gran tamaño.
Ejecutar tareas programadas y temporizadas
Desglosa el problema paso a paso y llama a los subagentes.
Admite entrada y salida en cualquier modalidad (voz, vídeo, texto, correo electrónico, etc.).
Utilizando la sintaxis de los sistemas operativos, se trata, en efecto, de un sistema operativo: un sistema operativo para ordenadores con agentes inteligentes. Windows hizo posible los ordenadores personales; OpenClaw hace posible los agentes inteligentes personales.
Cada empresa necesita desarrollar su propia estrategia para OpenClaw, del mismo modo que todos necesitamos estrategias para Linux, estrategias para HTML y estrategias para Kubernetes.
Una completa reestructuración de las TI empresariales.
Antes de OpenClaw, la informática empresarial consistía en datos y archivos que ingresaban a los sistemas, fluían a través de herramientas y flujos de trabajo, y finalmente se convertían en herramientas para uso humano. Las empresas de software creaban las herramientas, mientras que los integradores de sistemas globales (GSI) y las consultoras ayudaban a las empresas a utilizarlas.
La informática empresarial tras OpenClaw: Todas las empresas de SaaS se transformarán en empresas de AaaS (Agente como Servicio), que no solo proporcionarán herramientas, sino también agentes de IA especializados en dominios específicos.
Sin embargo, existe un desafío clave: los agentes inteligentes dentro de una empresa pueden acceder a datos confidenciales, ejecutar código y comunicarse con entidades externas. Esto debe controlarse estrictamente en un entorno empresarial.
Con este fin, nos asociamos con Peter para incorporar la seguridad en la versión empresarial, lo que dio como resultado:
NeMo Claw (Diseño de referencia): Un marco de referencia de nivel empresarial basado en OpenClaw, que integra el conjunto completo de herramientas de IA para agentes inteligentes de NVIDIA.
Open Shield (Capa de seguridad): Integrado en OpenClaw, proporciona un motor de políticas, una barrera de red y un enrutamiento de privacidad para garantizar la seguridad de los datos empresariales.
NeMo Cloud: Descargable y utilizable, y compatible con los motores de estrategia de todas las empresas SaaS.
Esto supone un renacimiento para la informática empresarial, un sector que originalmente valía 2 billones de dólares y que está a punto de crecer hasta alcanzar una escala multimillonaria, pasando de proporcionar herramientas a proporcionar servicios especializados de agentes de IA.
Preveo que, en el futuro, cada ingeniero de la empresa tendrá un presupuesto anual para tokens. Su salario anual puede ascender a cientos de miles de dólares, y les asignaré tokens adicionales equivalentes a la mitad de su salario, multiplicando su productividad por diez. La pregunta "¿Cuántos tokens se incluyen al unirse a la empresa?" se ha convertido en un nuevo tema de reclutamiento en Silicon Valley.
En el futuro, todas las empresas serán tanto usuarias de tokens (para ingenieros) como productoras de tokens (para ofrecer servicios a sus clientes). La importancia de OpenClaw es innegable; es tan fundamental como HTML y Linux.
Iniciativa de modelo abierto de NVIDIA
En lo que respecta a Custom Claws, ofrecemos el modelo de vanguardia desarrollado por NVIDIA:
Los dominios de modelado incluyen Nemotron (modelo de lenguaje a gran escala), Cosmos (modelo de la Fundación Mundial), GROOT (modelo de robot humanoide de propósito general), Alpamayo (conducción autónoma), BioNeMo (biología digital) y Phys-AI (física).
Estamos a la vanguardia de la tecnología en todos los campos y estamos comprometidos con la mejora continua: a Nemotron 3 le siguió Nemotron 4, a Cosmos 1 le siguió Cosmos 2, y Groq también se actualizará a su segunda generación.
Nemotron 3 se sitúa entre los tres mejores modelos del mundo en OpenClaw, lo que lo coloca a la vanguardia del sector. Nemotron 3 Ultra se convertirá en el modelo fundamental más potente jamás creado, ayudando a los países a desarrollar inteligencia artificial soberana.
Hoy anunciamos la formación del Consorcio Nemotron, que invertirá miles de millones de dólares para impulsar el desarrollo de modelos fundamentales de IA. Entre los miembros del consorcio se encuentran BlackForest Labs, Cursor, LangChain, Mistral, Perplexity, Reflection, Sarvam (India) y Thinking Machines (el laboratorio de Mira Murati). Empresas de software se están sumando, integrando el diseño de referencia NeMo Claw y el AI Agent Toolkit de NVIDIA en sus propios productos.
Física, IA y Robótica
Los agentes inteligentes digitales actúan en el mundo digital: escriben código y analizan datos; mientras que la IA física es un agente inteligente encarnado, es decir, un robot.
En la GTC de este año se exhibieron un total de 110 robots, que representan a casi todas las empresas de I+D en robótica del mundo. NVIDIA proporcionó tres ordenadores (uno para entrenamiento, otro para simulación y otro integrado) y un paquete completo de software y modelos de IA.
En el ámbito de la conducción autónoma, ha llegado el momento decisivo. Hoy anunciamos la incorporación de cuatro nuevos socios a la plataforma NVIDIA RoboTaxi Ready: BYD, Hyundai, Nissan y Geely, con una capacidad de producción anual combinada de 18 millones de vehículos. Esto refuerza aún más la ya existente lista de socios, que incluye a Mercedes-Benz, Toyota y GM. Además, anunciamos una importante alianza con Uber para desplegar e integrar vehículos RoboTaxi Ready en varias ciudades.
En el campo de la robótica industrial, muchas empresas de robótica como ABB, Universal Robots y KUKA se han asociado con nosotros para combinar modelos físicos de IA con sistemas de simulación, promoviendo la implementación de robots en las líneas de producción de todo el mundo.
En el sector de las telecomunicaciones, también se incluyen Caterpillar y T-Mobile. En el futuro, las estaciones base inalámbricas ya no serán solo nodos de comunicación, sino plataformas inteligentes de computación perimetral como NVIDIA Aerial AI RAN, capaces de detectar el tráfico en tiempo real, ajustar la formación de haces y lograr ahorros y eficiencia energética.
Reportaje especial: El robot Olaf hace su debut.
(Se reproduce un vídeo de demostración del robot Olaf de Disney)
Jensen Huang: ¡El muñeco de nieve ha llegado! ¡Newton funciona a la perfección! ¡Omniverse también funciona a la perfección! Olaf, ¿cómo estás?
Olaf: Me alegra mucho verte.
Jensen Huang: Sí, porque yo te di la computadora... ¡Jetson!
Olaf: ¿Qué es eso?
Huang Renxun: Está justo dentro de tu vientre.
Olaf: Eso es increíble.
Jensen Huang: Aprendiste a caminar en Omniverse.
Olaf: Me gusta caminar. Es mucho mejor que montar en un reno y mirar hacia el hermoso cielo.
Jensen Huang: Esto se debe precisamente a la simulación física, basada en el solucionador Newton que se ejecuta en NVIDIA Warp, que desarrollamos en colaboración con Disney y DeepMind, lo que permite adaptarlo al mundo físico real.
Olaf: Eso es exactamente lo que iba a decir.
Jensen Huang: Ahí reside tu inteligencia. Soy un muñeco de nieve, no una bola de nieve.
Jensen Huang: ¿Te lo imaginas? Un Disneyland del futuro: todos esos personajes robot deambulando libremente por el parque. Pero, sinceramente, pensé que serías más alto. Nunca había visto un muñeco de nieve tan bajito.
Olaf: (Sin comentarios)
Jensen Huang: ¿Me puedes ayudar a terminar mi discurso de hoy?
Olaf: ¡Eso es genial!
Resumen del discurso de apertura
Jensen Huang: Hoy hemos analizado juntos los siguientes temas principales:
Ha llegado el punto de inflexión: la inferencia se ha convertido en la carga de trabajo principal de la IA, los tokens son la nueva mercancía y el rendimiento de la inferencia determina directamente los ingresos.
La era de la fábrica de IA: Los centros de datos han evolucionado de instalaciones de almacenamiento de archivos a fábricas de producción de tokens. En el futuro, cada empresa medirá su competitividad por la "eficiencia de la fábrica de IA".
La revolución de los agentes inteligentes de OpenClaw: OpenClaw ha dado paso a la era de la computación basada en agentes inteligentes. El departamento de TI empresarial está pasando de la era de las herramientas a la era de los agentes inteligentes, y todas las empresas necesitan desarrollar una estrategia para OpenClaw.
Inteligencia artificial física y robótica: La inteligencia incorporada se está desplegando a gran escala, y la conducción autónoma, los robots industriales y los robots humanoides constituyen en conjunto la próxima gran oportunidad para la IA física.
¡Gracias a todos, que lo pasen genial en GTC! #黄仁勋 #GTC #AI $BTC $ETH