The Sign state was valid when the window opened.
Great.
That is exactly how you end up with the wrong wallet still claimable three hours later.
I keep getting stuck on this because people talk about revocation on @SignOfficial like that is the whole timing problem. It is not. Sometimes nothing dramatic even happens. No big revoke event. No obvious failure. The system just checked the state at the wrong moment, called that good enough, generated the claim set, and moved on like time was not still happening after that.
Time, annoyingly, kept happening.
A wallet clears under the schema. Attestation is there. Status good. Sign's SignScan indexer shows a clean record. Query layer reads it. TokenTable or whatever claims logic is upstream of distribution says fine, eligible, open the window. Good. Efficient. One less thing for ops to think about.
Then the condition changes.
Maybe the offchain case shifts. Maybe issuer-side approval gets pulled. Maybe a sanctions refresh lands. Maybe the attestation status changes. Maybe the subject was only safe under a narrower state that stopped being true before execution. Does not really matter which version. The important part is uglier and simpler: the system checked once, too early, and treated “fresh enough at open” like “safe enough at execution.”
Those are not the same timestamp. Not even close once money is attached.
That is the Sign protocol part. Read looked clean. So everyone acted like the timing problem was over. It wasn’t. Schema matched. Issuer signed. Status looked right when read. SignScan can surface it. Query comes back nice and neat. After that the temptation is obvious. Read once. Build the claim set. Stop paying for extra checks. Stop hitting the state again at execution-time. Everything after that starts looking wasteful right up until somebody has to explain why a wallet was still allowed through after the thing that made it eligible had already moved.
Alright.
That gap is it.
Maybe “cheap” is rude. Keep it. Most of the time this gets dressed up as efficiency. Reduce calls. Precompute the claimable set. Avoid extra verification at redemption time. Fine. All normal. Also exactly how a fresh-enough read gets promoted into a permission the system keeps honoring after the underlying condition is already stale.
The read happened. The action happened later.
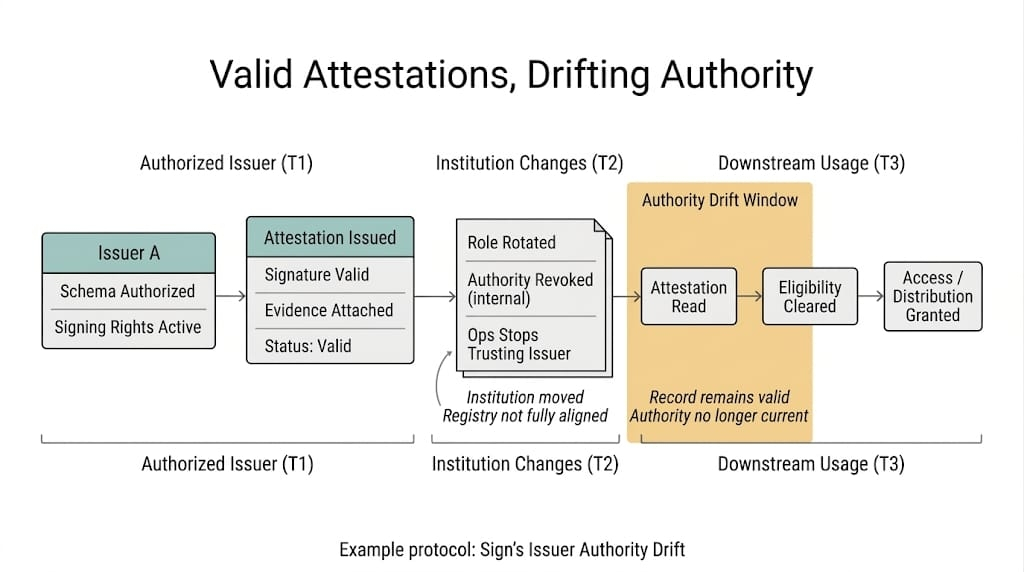
I keep picturing the workflow because it is so ordinary it almost hides. At 09:00 the eligibility read runs off Sign state and maybe some thin side conditions. Claim set generated. Wallet included. Window open. At 11:40 something changes. Status flips. Approval pulled on Sign. Manual hold added. At 12:05 the wallet executes anyway because the claims path is not reading the state that matters now. It is honoring the state it read earlier.
By 12:05 the set is already out somewhere. Cached. Published. Committed. Whatever ugly version they chose. Nobody wants to reopen it during a live claim window. So the path honors inclusion and keeps moving.
The set was already published by then. Nobody was re-reading status at claim-time.
And then everyone answers the wrong question.
Was the attestation valid when the set was generated. Sure.
Did $SIGN SignScan return the record correctly. Sure.
Was the wallet in the claim set. Sure.
Fine.
The actual question is why the system cared more about the timestamp at open than the timestamp at execution.
Which timestamp actually mattered here.
Open.
Execution.
Hold landed.
Status changed.
Which one was the filter built to care about.
That is where people start getting vague, because usually the real answer is some combination of cost control, operational convenience, lazy assumptions about stability, and the general human belief that if a record looked clean one hour ago it probably still deserves trust now.
Probably.
There is that word again.
That word keeps systems in business, apparently.
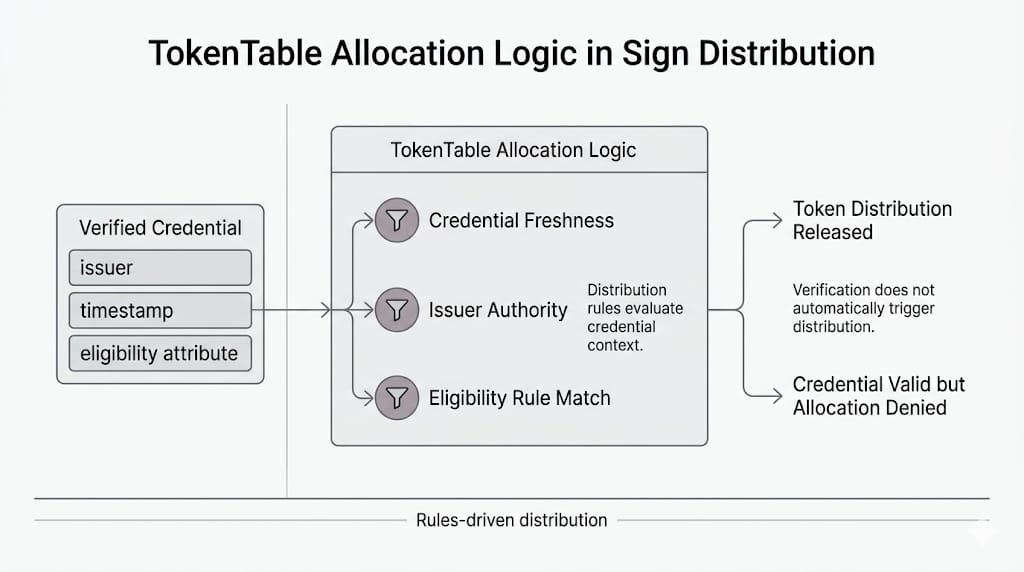
TokenTable is the obvious place this gets ugly because TokenTable likes clear states. Claimable or not. Included or not. Once the set is generated, that decision starts hardening socially even when it was only supposed to be a snapshot. Snapshot is another polite word. Makes it sound harmless. Sometimes it is. Sometimes it is the moment the workflow decides to stop looking at reality and start honoring its cached version of it.
Cached trust. That usually ages well.
And it is not always revocation.
That is what people miss.
Maybe the Sign's attestation still looks valid. Maybe what changed was offchain. Maybe the institution would still stand by the old record as history and still say it should not have authorized this execution. Real record. Wrong timing.
Nobody likes that split once money lands.
Because the protocol can be correct at read-time and still useless at execution-time if the wrong timestamp got promoted into the one that mattered. Sign protocol sharpens that because the state at read-time looks respectable. Queryable. Signed. Calm. Not some fuzzy internal flag. A real attested object with all the usual cues telling the next system it can trust what it is seeing.
Good. Great even.
Right up until the next system forgets that trusting what it saw earlier is not the same as checking what is true now.
The worst part is how boring this sounds before it breaks. No exploit theater. No forged record. No broken schema. Just a system that read the right thing at the wrong time and then kept acting like timing was a side detail.
Then the wallet claims.
Then somebody asks why it was still in scope.
And every answer is still coming from before claim-time. Earlier read. Earlier state. Earlier clean status on Sign. Fine. Money moved anyway.