La mayoría de la gente todavía habla de la Inteligencia Artificial como si el modelo fuera el producto.
Siempre dicen cosas como: modelo, más parámetros, respuestas más rápidas, mejores puntuaciones de referencia.
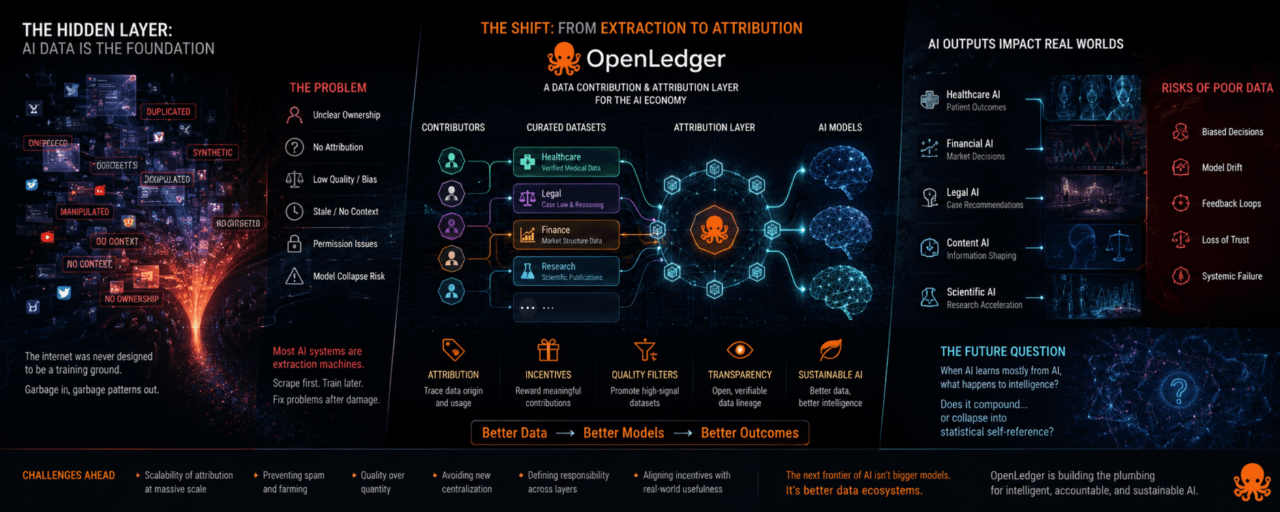
Después de estar observando este espacio por un tiempo, empieza a sentirse extraño cuánto poca atención se le presta a la cosa que alimenta esos modelos en primer lugar.
Los datos de Inteligencia Artificial todavía se sienten como la capa oculta de la que nadie quiere hablar
Probablemente eso fue lo que llamó mi atención de OpenLedger.
El proyecto sigue llevando la conversación de vuelta hacia los datos de Inteligencia Artificial, tratándolos como si fueran una materia prima invisible que mágicamente aparece de internet para siempre.
Honestamente, eso cambia toda la discusión en torno a los algoritmos de aprendizaje de Inteligencia Artificial.
Porque una vez que dejas de asumir que existe un suministro ilimitado de datos de Inteligencia Artificial limpios, todo el sistema comienza a parecer menos estable de lo que la gente piensa.
La mayoría de los algoritmos de aprendizaje de Inteligencia Artificial hoy dependen más de la escala que de la elegancia.
Alimentas información en un modelo de Inteligencia Artificial y eventualmente emergen patrones.
Patrones útiles emergen, a veces emergen patrones rotos.
Ahora parece cada vez más que los datos de Inteligencia Artificial son la verdadera limitante.
No solo la cantidad de datos de Inteligencia Artificial. También la frescura, propiedad, precisión, sesgo, permiso y contexto.
Estas cosas importan una vez que los sistemas de Inteligencia Artificial comienzan a operar continuamente en lugar de ser entrenados una vez y olvidados.
Eso crea un problema.
Internet nunca fue diseñado para convertirse en un campo de entrenamiento para sistemas de aprendizaje automático.
Mucho contenido en línea está duplicado, mucho es sintético ya, parte de él es manipulado para el compromiso. Parte de él está desactualizado pero aún se trata como un hecho porque los modelos de Inteligencia Artificial no pueden entender naturalmente el tiempo como lo hacen los humanos.
Así que cuando OpenLedger impulsa la idea de la atribución de datos de Inteligencia Artificial y conjuntos de datos especializados, se siente como un ángulo de cripto a la moda y más como alguien notando dónde pueden aparecer futuras grietas.
La parte interesante no es la blockchain en sí, es el intento de estructurar cómo aprende la Inteligencia Artificial.
La mayoría de los ecosistemas de Inteligencia Artificial hoy se comportan como máquinas de extracción: raspa primero, entrena después, trata las preguntas de propiedad después de que intervengan los reguladores.
Ese enfoque funcionó cuando la Inteligencia Artificial era experimental. No está claro si escala una vez que las empresas comienzan a depender de los modelos de Inteligencia Artificial para flujos de trabajo y decisiones reales.
Si un modelo de Inteligencia Artificial en salud entrena con datos de Inteligencia Artificial médicos, el daño es obvio.
Incluso los fracasos más pequeños importan: los sistemas de recomendación se desvían, los modelos de Inteligencia Artificial de sentimiento financiero sobreajustan narrativas, los modelos de Inteligencia Artificial de lenguaje reciclan lentamente su propio contenido generado de nuevo en bucles de entrenamiento.
Los algoritmos de aprendizaje de Inteligencia Artificial originalmente mejoraban al observar el comportamiento y los patrones de escritura humana.
Ahora, cada vez más contenido en internet es generado por máquinas.
Entonces, ¿qué pasa cuando los modelos de Inteligencia Artificial aprenden principalmente de otros modelos de Inteligencia Artificial?
¿La inteligencia se compone? ¿El sistema colapsa lentamente en la autorreferencia estadística?
Parece que nadie lo sabe completamente todavía.
Aquí es donde las decisiones de diseño de OpenLedger se vuelven más interesantes que el "branding" de Inteligencia Artificial descentralizada.
La red parece centrarse en rastrear de dónde provienen los datos de Inteligencia Artificial y recompensar a los contribuyentes vinculados a conjuntos de datos de Inteligencia Artificial útiles.
Por lo menos conceptualmente, eso cambia los incentivos.
Normalmente, los contribuyentes de datos de Inteligencia Artificial desaparecen después de subir contenido; las plataformas capturan el valor, los modelos de Inteligencia Artificial absorben la información y las fuentes originales se vuelven irrelevantes.
OpenLedger parece estar tratando de mantener viva la conexión entre el origen de los datos de Inteligencia Artificial y la salida del modelo de Inteligencia Artificial.
Eso suena simple en papel, pero mucho más difícil en la realidad.
Porque la atribución dentro de los sistemas de aprendizaje automático es desordenada; una vez que los patrones se fusionan dentro de una red, se vuelve difícil aislar exactamente qué punto de datos de Inteligencia Artificial influyó en qué comportamiento.
Así que la idea en sí tiene sentido. La implementación se siente como el verdadero campo de batalla aquí.
¿Puede la atribución seguir siendo significativa a gran escala?
¿Pueden los contribuyentes realmente verificar el uso de datos de Inteligencia Artificial?
¿Pueden conjuntos de datos de Inteligencia Artificial de baja calidad inundar los sistemas de recompensa de la misma manera que la agricultura destruyó incentivos en otros sectores cripto?
Ese riesgo se siente muy real.
También hay otro problema debajo de todo esto.
Los buenos datos de Inteligencia Artificial no están distribuidos uniformemente.
Algunas industrias naturalmente producen información estructurada, otras producen ruido.
Así que si los ecosistemas de Inteligencia Artificial comienzan a recompensar los datos de Inteligencia Artificial, eventualmente ciertos grupos ganarán una influencia desproporcionada sobre cómo se comportan los sistemas de Inteligencia Artificial futuros.
Eso introduce otra capa de centralización dentro de sistemas que supuestamente son descentralizados.
La gente habla de monopolios de computación todo el tiempo; los monopolios de datos de Inteligencia Artificial pueden terminar siendo importantes y más difíciles de detectar.
Aún así, hay algo en OpenLedger que se centra en la capa de entrada en lugar de pretender que la arquitectura del modelo de Inteligencia Artificial por sí sola lo resuelve todo.
Muchos proyectos de cripto e Inteligencia Artificial se sienten desconectados de cómo evoluciona el aprendizaje automático.
Adjuntan tokens a los mercados de GPU. Llámalo infraestructura, pero los algoritmos de aprendizaje de Inteligencia Artificial no mejoran solo porque existe más hardware.
Mejoran cuando la calidad de la señal mejora: conjuntos de entrenamiento, mejor etiquetado, más contexto específico del dominio, más bucles de retroalimentación anclados en la realidad en lugar de métricas de compromiso sintéticas.
Esa parte importa, probablemente más de lo que la mayoría de los traders minoristas notan en este momento.
Otra cosa que vale la pena observar es si los modelos de Inteligencia Artificial especializados más pequeños se vuelven más valiosos que los sistemas de propósito general.
Porque si eso sucede, entonces los conjuntos de datos de Inteligencia Artificial curados se convierten en activos.
Un modelo de Inteligencia Artificial legal entrenado en razonamiento verificado, un modelo de Inteligencia Artificial biotecnológico entrenado en entornos de investigación reales, un modelo de Inteligencia Artificial de trading entrenado en el comportamiento estructural de mercado confiable en lugar de ruido social aleatorio.
Ese futuro naturalmente aumentaría la importancia de las redes que intentan organizar sistemas de contribución de datos de Inteligencia Artificial.
Quizás ahí es donde OpenLedger encaja mejor, no reemplazando los laboratorios de Inteligencia Artificial, sino convirtiéndose en la plomería debajo de sistemas inteligentes más específicos.
Aquí sigue habiendo un problema de confianza.
Los sistemas cripto aman hablar sobre la transparencia; los sistemas de Inteligencia Artificial suelen ser cajas negras.
Combinar los dos no resuelve automáticamente la responsabilidad; puede incluso crear confusión.
¿A quién se le culpa cuando las salidas del modelo de Inteligencia Artificial fallan?
¿El proveedor de conjuntos de datos de Inteligencia Artificial, el constructor del modelo de Inteligencia Artificial, la capa de inferencia, los validadores de red?
La responsabilidad se vuelve borrosa rápidamente una vez que suficientes capas se apilan juntas.
Luego está el lado económico.
Los sistemas descentralizados eventualmente luchan con la calidad de los incentivos.
La gente optimiza para recompensas, no para utilidad; ese patrón se repite en todas partes: minería de liquidez, agricultura de airdrops, agricultura de contenido, participación en gobernanza.
Así que la verdadera prueba para OpenLedger probablemente no sea la arquitectura, sino si la red puede distinguir datos de aprendizaje de Inteligencia Artificial genuinamente valiosos, de basura producida en masa diseñada solo para extraer recompensas.
Eso suena más fácil de lo que es porque los humanos apenas están de acuerdo en lo que "información de alta calidad" incluso significa hoy en día.
Cuanto más profundo miro los sistemas de aprendizaje de Inteligencia Artificial, menos se parecen a problemas de ingeniería.
Comienzan a parecerse a sistemas sociales disfrazados de software.
El comportamiento humano entra en el bucle en todas partes; el sesgo entra, la presión económica entra, la manipulación entra, los incentivos de atención entran.
Eso cambia cómo estos algoritmos de Inteligencia Artificial evolucionan con el tiempo.
Quizás por eso los proyectos que se centran en la estructura de datos de Inteligencia Artificial se sienten más importantes últimamente, no porque hayan resuelto la Inteligencia Artificial, sino porque notaron dónde el modelo actual de Inteligencia Artificial puede empezar a romperse silenciosamente primero.
