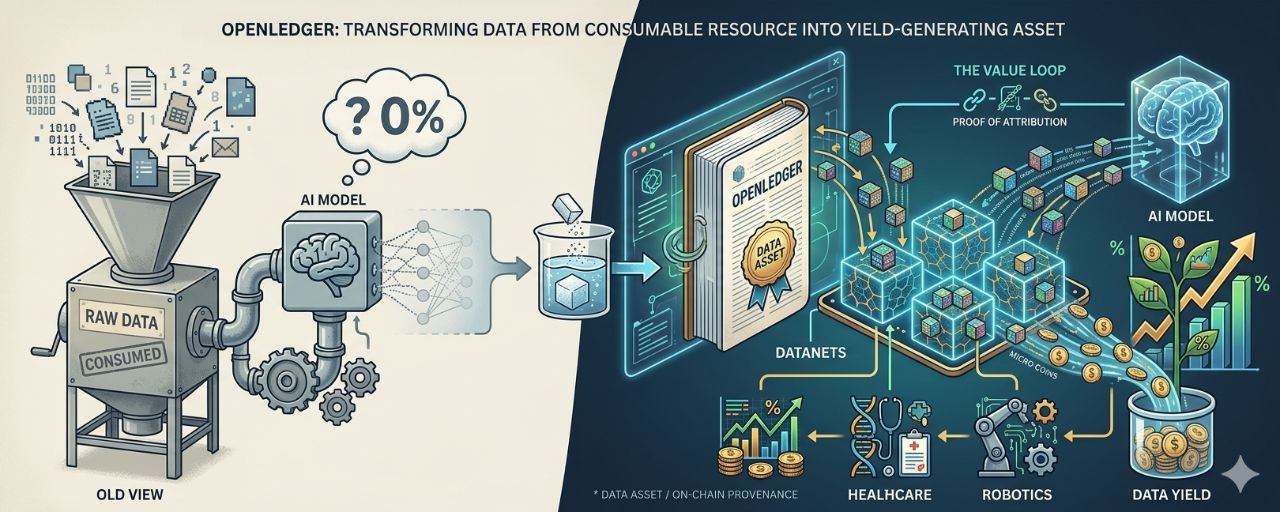
Yo solía entender los datos de la manera más simple: son la materia prima. Un modelo de IA necesita datos para aprender, y una vez que ha aprendido, los datos ya no aparecen en ningún lado. Desaparecen dentro de los pesos del modelo como la sal se disuelve en el agua. No puedes verlo, no se puede rastrear, y definitivamente nadie piensa en pagarle a quien lo creó.
Esa lógica es extremadamente común. Y extremadamente problemática.
La organización WIPO estima que el mercado global de PI, incluyendo derechos digitales y datos, está cerca de los 80 billones de dólares. La mayor parte de ese valor está siendo absorbido por las empresas de IA sin ningún mecanismo para redistribuirlo a quienes lo crearon. Los datos están generando un valor enorme, pero en una sola dirección.
OpenLedger parte de una suposición completamente diferente: los datos no son un recurso desechable. Son un activo. Y los activos pueden generar rendimiento.
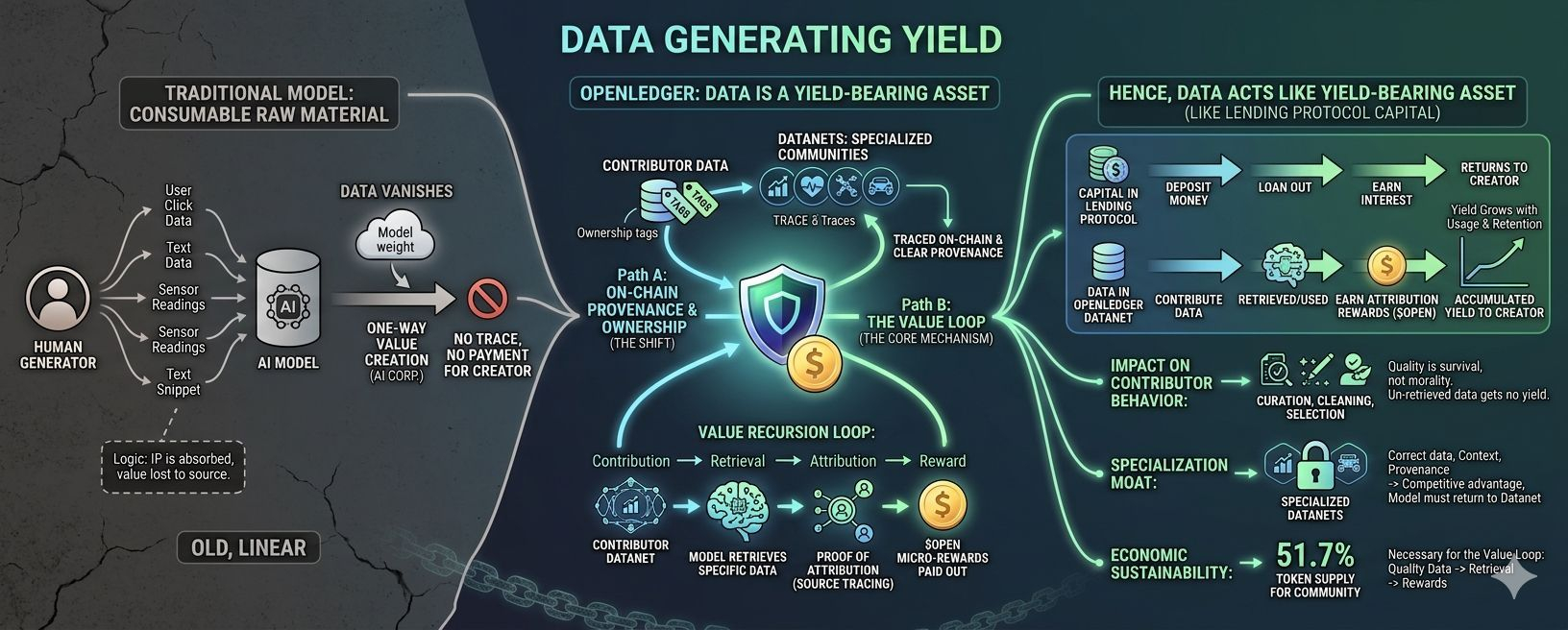
Para entender por qué, necesito hablar sobre Datanets primero. En el sistema OpenLedger, cuando contribuyes datos, no van a un repositorio central anónimo. Van a Datanets, que son redes de datos comunitarias utilizadas para entrenar modelos especializados. En ese momento, tus datos tienen un propietario claro. Tienen un lugar. Tienen un origen registrado en la cadena. Este es el primer desvío en la forma en que el sistema ya no ve esto como una entrada anónima, sino como una contribución que puede ser rastreada.
Pero lo más importante es lo que sucede a continuación.
OpenLedger está utilizando un mecanismo que llamaremos ciclo de retroalimentación de valor: contribución → recuperación → atribución → recompensa. No es una transacción única. Es un bucle. Cada vez que tus datos son recuperados y utilizados en la salida de un modelo, Proof of Attribution de OpenLedger rastrea hacia atrás la fuente, y recibes micro-recompensas correspondientes a la verdadera influencia de esos datos en la salida. Esto significa que el valor de los datos no reside en el momento de la carga. Aparece cada vez que se vuelven a usar los datos.
Esta es la razón por la que los datos comienzan a comportarse más como un activo generador de rendimiento que como un recurso.
Piensa en esto de esta manera. Cuando depositas dinero en un protocolo de préstamos, ese dinero no desaparece. Se presta, genera interés, y ese interés vuelve a ti según la frecuencia de uso. Los datos en Datanets de OpenLedger funcionan de manera similar. Los datos no desaparecen después de ser utilizados por primera vez. Siguen en el sistema, siguen siendo recuperados, siguen generando señales de atribución, siguen generando recompensas. Cuanto más se utilizan, mayor es el rendimiento acumulado.
Y aquí es donde las cosas se complican de manera interesante.
Cuando la recompensa se vincula a la recuperación, el comportamiento del contribuyente comienza a cambiar. Ya no solo suben datos por subir. Comienzan a curar. A limpiar. A seleccionar. A asegurar que los datos sean realmente recuperables, de verdad tengan calidad y sean relevantes para el dominio que el modelo está sirviendo. Porque los datos de baja calidad no se recuperan mucho, lo que significa que no hay rendimiento. La calidad ya no es un concepto moral vago. Es una cuestión de supervivencia del flujo de ingresos.
Y de ahí surge algo que suena muy financiero: el foso de la especialización.
@OpenLedger enfatiza especialmente Datanets para dominios especializados, finanzas, salud, robótica, movilidad. Cuando los datos ingresan a esos dominios específicos, el valor ya no proviene de tener muchos datos. Proviene de tener los datos correctos. Los datos financieros exclusivos con todo el contexto y un origen limpio no son fáciles de reemplazar. Un modelo que quiere funcionar bien en ese dominio debe volver a ese Datanet específico. Los contribuyentes en ese Datanet tienen un tipo de foso natural sin necesidad de construir muros o patentar nada.
Creo que esta es la parte menos discutida en la historia de la economía de datos.
La mayor parte del discurso actual gira en torno a "quién posee los datos", quién tiene derecho a usar los datos, quién debería ser pagado. Pero la pregunta más profunda es: ¿qué mecanismo hace que el "ser pagado" sea una realidad continua y no solo un evento único? OpenLedger construyó el ciclo de retroalimentación de valor como un mecanismo de infraestructura, no solo como una característica de UI. Cada interacción en el sistema es un evento monetizable para el contribuyente. Esa es la razón por la que describen el token $OPEN no solo como un token de gobernanza, sino como algo que distribuye recompensas basadas en el uso real en la pista de atribución.
Según su diseño, el 51.7% del suministro de tokens se asigna a la comunidad, vinculado a la contribución real al ecosistema. No es porque quieran tener una narrativa bonita, sino porque es la única manera de que el ciclo de retroalimentación de valor funcione. Si la recompensa no es suficiente, el contribuyente no tiene la motivación para mantener la calidad. Si el contribuyente no mantiene la calidad, la tasa de recuperación disminuye. Si la tasa de recuperación disminuye, la salida del modelo empeora. Todo el sistema colapsa.
Pero no quiero que este artículo termine en un punto demasiado optimista.
Hay una tensión real en este modelo. Cuando la recompensa se vuelve clara y medible, aparece el riesgo de farming. La gente puede optimizar no por la verdad, sino por la señal de atribución. Subir datos está diseñado para ser recuperado mucho, pero no necesariamente son los mejores datos. Este es un problema que todos los sistemas de incentivos deben enfrentar, y OpenLedger no es la excepción.
Y hay un punto más: el rendimiento de los datos no es fijo. Los datos pueden volverse obsoletos. Los dominios pueden cambiar. El modelo entrenado en ese Datanet puede ya no ser utilizado. Entonces, ese flujo de rendimiento se contrae. A diferencia de un bono del gobierno con un cupón fijo, el rendimiento de los datos depende de un ecosistema que solo controlas en parte.
Creo que esta es la razón por la que la afirmación "los datos son activos que generan rendimiento" necesita ser entendida mejor como "los datos son activos que generan rendimiento en un sistema con trazabilidad y demanda real". El rendimiento no reside en los datos por sí mismos. Está en el ciclo de retroalimentación de valor: contribución en el lugar correcto, recuperación con suficiente frecuencia, atribución lo suficientemente transparente, recompensa suficiente para mantener el comportamiento de curación.
OpenLedger no solo está construyendo una blockchain con Proof of Attribution. Está tratando de crear las condiciones para que ese bucle se mantenga por sí mismo a lo largo del tiempo. Si realmente lo logra o no depende de cosas mucho más difíciles de medir: si los contribuyentes realmente tienen la motivación para la curación a largo plazo, si el motor de atribución es lo suficientemente preciso para distinguir la calidad de los datos, y si la demanda por modelos de IA especializados es lo suficientemente grande para mantener Datanets siempre activos.
Esa pregunta aún no tengo respuesta.