

Siempre vuelvo a un pensamiento incómodo sobre la IA. El mercado habla mucho sobre modelos más grandes, chips mejores, inferencias más baratas y agentes más rápidos. Todo eso importa. Pero hay un problema más silencioso debajo: cuando un sistema de IA se vuelve más útil, ¿quién realmente creó ese valor?$OPEN #OpenLedger @OpenLedger
¿Fue el desarrollador del modelo? ¿Fue la persona que proporcionó un conjunto de datos raro? ¿Fue la comunidad que refinó el modelo con el tiempo? ¿Fue la retroalimentación del usuario que hizo que el sistema fuera más inteligente en un dominio específico?
En la mayoría de los sistemas de IA, esas contribuciones se vuelven muy difíciles de separar. Una vez que los datos entran en el pipeline y el modelo mejora, el contribuyente original a menudo desaparece en la salida final. Eso puede ser conveniente para las plataformas centralizadas, pero crea un verdadero problema económico.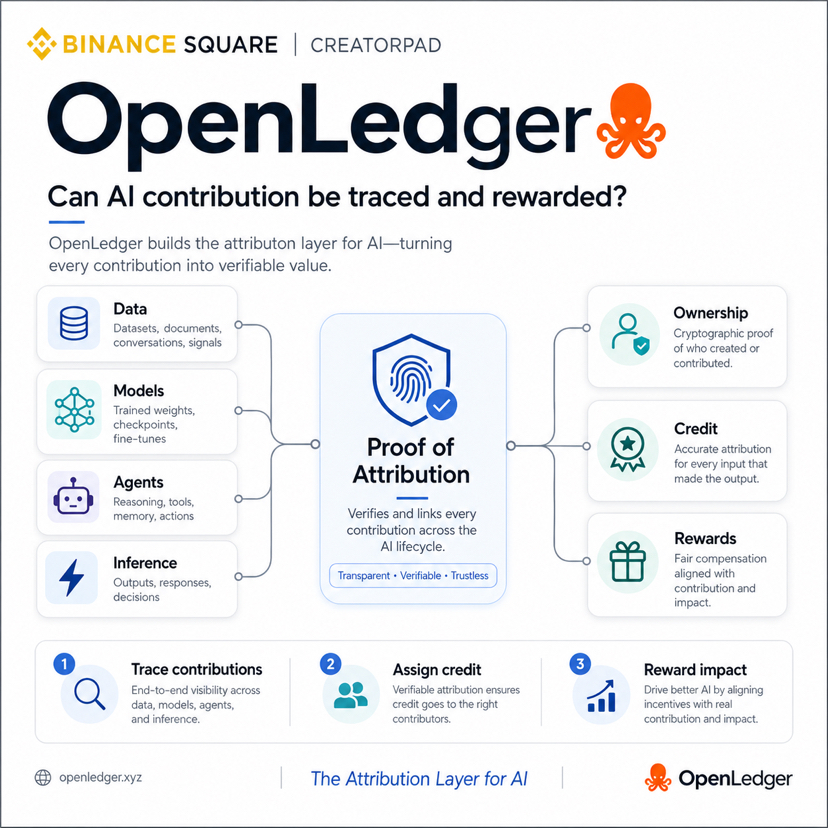
Si la contribución no puede ser rastreada, es difícil recompensar de manera justa. Esa es la parte de OpenLedger que captó mi atención. No porque 'blockchain de IA' sea una nueva frase, sino porque el proyecto se centra en un problema de coordinación específico: la atribución.
La tesis de OpenLedger es que la contribución a la IA no debe permanecer vaga. Debe ser verificable, rastreable y económicamente significativa. En términos simples, el proyecto está tratando de hacer que la contribución a la IA sea algo que se pueda registrar, verificar y recompensar en lugar de ser absorbido silenciosamente por el sistema.
Ese es un ángulo muy diferente de simplemente decir 'poner IA en la cadena'. La fricción práctica es fácil de entender. El desarrollo de IA no es una acción limpia. Es un ciclo de vida. Alguien puede proporcionar datos. Alguien más puede ajustar un modelo. Otro participante puede mejorar un agente. Más tarde, la actividad de inferencia puede mostrar qué modelo o conjunto de datos realmente creó salidas útiles.
La cadena de valor es desordenada. OpenLedger intenta organizar ese ciclo de vida desordenado registrando puntos importantes de contribución en la cadena. Eso puede incluir contribuciones de datos, cambios de modelos y atribución relacionada con la inferencia o el uso futuro. La idea es que una vez que estas acciones se vuelven rastreables, el sistema puede comenzar a asignar propiedad, crédito y, eventualmente, recompensas.
Aquí es donde la Prueba de Atribución se convierte en el mecanismo central. En lugar de tratar el valor de la IA como un resultado final en una caja negra, la Prueba de Atribución intenta identificar qué contribuyentes tuvieron un impacto significativo. Si un conjunto de datos mejora el rendimiento de un modelo, o una actualización de modelo hace que un agente sea más útil, el sistema debería poder reconocer esa contribución en lugar de dejarla desaparecer.
Para cripto, esto importa porque las blockchains son más fuertes cuando resuelven problemas de coordinación. OpenLedger no está utilizando registros en la cadena solo para decoración. La afirmación importante es que la IA necesita una capa económica donde la contribución pueda ser probada y recompensada.
Esa afirmación vale la pena tomarse en serio. La evidencia detrás de la dirección del proyecto es bastante clara. OpenLedger se describe a sí mismo como una Blockchain de IA centrada en rastrear contribuciones a lo largo del ciclo de vida de la IA. Utiliza la Prueba de Atribución para asignar propiedad y crédito. Intenta recompensar a las personas por el valor que realmente aportan, no solo por aparecer. Y al registrar estos pasos en la cadena, intenta hacer que el ciclo de vida de la IA sea más auditable.
Esa última palabra importa más de lo que parece. La auditabilidad no es solo una característica de cumplimiento. También es una característica de confianza. Si los sistemas de IA van a depender de datos externos, modelos abiertos, agentes especializados y participación comunitaria, entonces los contribuyentes necesitan una razón para creer que el sistema no los borrará una vez que su trabajo se vuelva útil.
Imagina que un investigador en ciberseguridad contribuye con un conjunto de datos de nicho que ayuda a mejorar un modelo diseñado para detectar un tipo específico de amenaza. En un pipeline normal de IA, ese conjunto de datos podría mejorar la calidad del modelo, pero el colaborador podría no recibir ningún reconocimiento duradero una vez que el modelo se implemente.
El argumento de OpenLedger es diferente. Si ese conjunto de datos está vinculado a la mejora del modelo y su posterior uso, el colaborador no tiene que ser invisible. La contribución puede seguir conectada a la creación de valor futuro. Si el modelo se utiliza más adelante en inferencias del mundo real, el sistema teóricamente puede rastrear parte de ese valor de vuelta a los datos que ayudaron a mejorar el modelo.
Esa es la idea económica. Una mejor economía de IA no se trata solo de quién posee el modelo más grande. También se trata de si las personas que alimentan, mejoran, prueban y especializan los sistemas de IA pueden participar en el beneficio. OpenLedger está tratando de convertir la atribución en infraestructura.
Aún así, aquí es donde me vuelvo cauteloso. Medir la contribución es mucho más difícil que registrar la contribución. Una blockchain puede probar que algo fue enviado, cambiado o utilizado. Pero probar el verdadero impacto de esa contribución es un problema técnico más profundo. No todos los conjuntos de datos mejoran un modelo de igual manera. No todas las actualizaciones de modelos crean valor útil. Algunas contribuciones pueden estar duplicadas, ser de baja calidad o útiles solo en contextos específicos.
Así que la pregunta difícil no es si OpenLedger puede registrar la actividad de IA. La pregunta más difícil es si puede medir la influencia de manera lo suficientemente justa para que las recompensas se sientan legítimas.
Ese es un gran desafío. Si la atribución es demasiado laxa, el sistema podría recompensar el ruido. Si las reglas son demasiado estrictas, algunos colaboradores más pequeños pero genuinamente útiles podrían quedar excluidos. Si el sistema es demasiado caro o lento, puede que no se mantenga al ritmo de lo rápido que realmente avanza la IA.
Y si solo un pequeño grupo controla las reglas de atribución, OpenLedger podría acabar repitiendo el mismo desequilibrio que está tratando de corregir.
Esta es la parte que observaré más de cerca.
¿Puede OpenLedger hacer que la atribución sea lo suficientemente eficiente para los flujos de trabajo de IA reales? ¿Puede separar la contribución significativa de la simple participación? ¿Puede recompensar el impacto sin convertir el proceso en un complicado juego de puntuación? Y ¿puede hacerlo a través de datos, modelos, agentes e inferencias sin crear demasiada fricción para los constructores?
La idea es fuerte porque el problema es real. La IA se está volviendo más colaborativa, pero la economía sigue siendo desigual. Muchas personas pueden ayudar a crear valor, pero solo unos pocos sistemas suelen capturarlo. Si OpenLedger puede hacer que la contribución sea visible y recompensable, podría convertirse en una capa importante para la IA descentralizada.
Pero el modelo aún tiene que probarse bajo presión. La atribución suena justa en teoría. La verdadera prueba es si puede sobrevivir a datos desordenados, contribuyentes en competencia y el uso de IA a gran escala.
¿Es la atribución la capa económica que falta para la IA descentralizada, o es la parte más difícil que aún está esperando ser resuelta?$OPEN #OpenLedger @OpenLedger 