
Todavía recuerdo la primera vez que miré seriamente OpenLedger.
No fue a partir de un hilo viral. No porque alguien estuviera haciendo shilling del token. Y honestamente, ni siquiera por los titulares de financiamiento que todos estaban compartiendo.
Ocurrió durante una de esas sesiones de investigación nocturnas donde abres diez pestañas pensando que pasarás quince minutos leyendo, y de repente te das cuenta de que ya casi es de mañana.
En ese momento, cada proyecto de IA en cripto empezaba a sonar idéntico.
“IA revolucionaria.” “Inteligencia de próxima generación.” “Futuro descentralizado.”
Las mismas palabras de moda por todas partes.
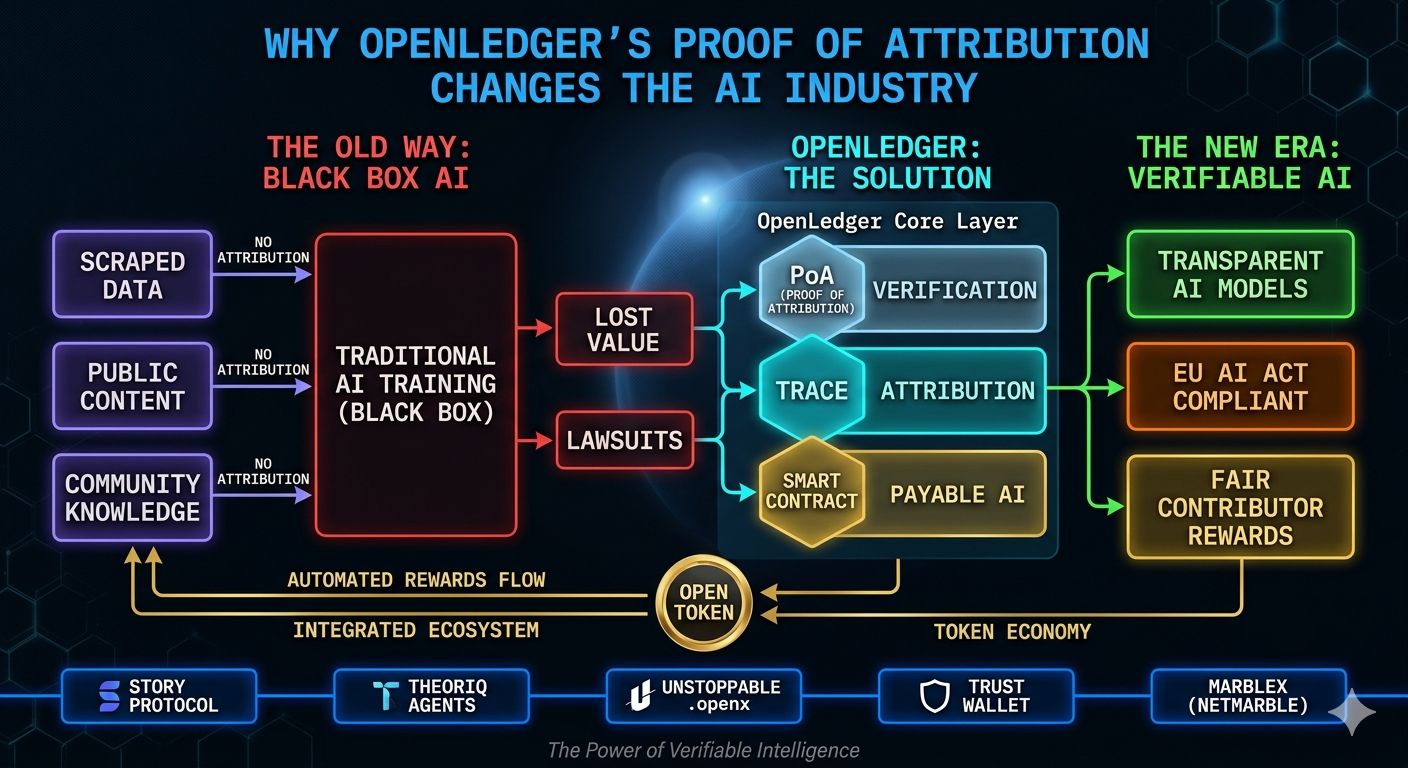
Pero cuando comencé a leer sobre el modelo de Prueba de Atribución de OpenLedger, me detuve un segundo porque la idea detrás de esto estaba resolviendo un problema del que la mayoría de las personas en IA aún evitan hablar directamente.
¿De dónde proviene exactamente todo este conocimiento de IA?
Esa pregunta suena simple, pero se está convirtiendo en uno de los problemas más grandes en toda la industria.
En este momento, la economía moderna de IA funciona con enormes cantidades de datos recopilados, información recolectada, contenido público, material generado por la comunidad y conjuntos de entrenamiento extraídos de innumerables fuentes en internet.
Pero casi nadie realmente sabe cómo se están rastreando esos conjuntos de datos.
Sin transparencia clara. Sin atribución adecuada. Sin responsabilidad pública.
Las personas utilizan productos de IA todos los días sin darse cuenta de cuánta poca visibilidad existe detrás del proceso de entrenamiento en sí.
Incluso los reguladores están luchando por mantenerse al día.
Ya puedes ver la presión acumulándose a nivel global a través de demandas por derechos de autor, disputas de publicación y crecientes preocupaciones sobre el uso no autorizado de datos. Los gobiernos están comenzando a darse cuenta de que la IA no puede seguir escalando para siempre dentro de un sistema donde nadie puede verificar de dónde provino originalmente la inteligencia.
Ahí es donde OpenLedger comenzó a sentirme diferente.
En lugar de tratar los datos como combustible invisible que desaparece después del entrenamiento, OpenLedger los trata como una capa económica activa.
Cada conjunto de datos puede ser registrado. La actividad de entrenamiento puede ser registrada. El uso de inferencia se puede rastrear a través del propio sistema.
Y honestamente, la implicación más profunda aquí es enorme.
Porque por primera vez, los contribuyentes ya no son invisibles.
Si alguien proporciona conjuntos de datos valiosos que mejoran el rendimiento de la IA, la infraestructura de OpenLedger permite que la atribución permanezca conectada al uso. A través de su modelo de IA Pagable, los contribuyentes pueden potencialmente recibir recompensas en tokens OPEN automáticamente cada vez que sus datos se convierten en parte de la actividad de inferencia.
No hay una empresa centralizada decidiendo manualmente los pagos. No hay cálculos ocultos en el backend. No se depende solo de la confianza.
La infraestructura lo maneja de manera transparente.
Esa idea puede sonar técnica en la superficie, pero económicamente cambia todo.
La mayoría de los sistemas de IA hoy en día operan como cajas negras.
Las personas contribuyen valor. Las plataformas lo absorben. Nadie ve lo que sucede después.
OpenLedger voltea completamente esa estructura.
Crea un entorno donde la inteligencia misma se vuelve económicamente rastreable.
Y personalmente, creo que eso se vuelve extremadamente importante una vez que las regulaciones comienzan a apretarse a nivel global.
La Ley de IA de la UE ya está impulsando conversaciones sobre transparencia y responsabilidad. EE. UU. continúa aumentando la presión sobre la gobernanza de la IA. Los mercados asiáticos se están moviendo en la misma dirección a medida que la adopción se acelera.
Tarde o temprano, las grandes empresas de IA probablemente necesitarán sistemas capaces de probar de dónde provino el dato de entrenamiento y cómo se usó.
Cuando llegue ese momento, la Prueba de Atribución dejará de parecer una característica experimental de blockchain.
Empieza a parecer infraestructura requerida.
Esa es la razón por la que OpenLedger se siente más sustancial que la mayoría de las narrativas cripto de IA que flotan en este momento.
Muchos proyectos en este sector honestamente se sienten como envoltorios delgados alrededor de APIs existentes con tokens adjuntos después para llamar la atención del mercado.
OpenLedger parece que está construyendo la capa base en su lugar.
Y el ecosistema a su alrededor sigue reforzando esa dirección.
El Protocolo de Historia conecta la infraestructura de derechos de autor en flujos de trabajo de IA. Theoriq se enfoca en agentes de IA verificables operando dentro de sistemas DeFi. Unstoppable Domains agrega infraestructura de identidad a través de dominios .openx. La integración de Trust Wallet expande la accesibilidad entre usuarios y aplicaciones.
Luego está MARBLEX, respaldado por Netmarble, una de las empresas de juegos más grandes de Asia.
Esa parte me llamó la atención porque el juego puede eventualmente convertirse en uno de los entornos más grandes para sistemas de IA transparentes. Cuando las economías impulsadas por IA comienzan a interactuar con activos digitales, mercados, sistemas de NPC y contenido generado por usuarios, la atribución de repente importa mucho más de lo que la gente actualmente se da cuenta.
Y OpenLedger ya parece estar posicionado para ese futuro.
Cuanto más investigaba el proyecto, más dejé de verlo como solo otro protocolo de blockchain.
Empezó a parecer más una infraestructura de responsabilidad para la próxima fase de crecimiento de la IA.
No es llamativo. No está construido alrededor de ciclos de hype. Pero está resolviendo silenciosamente uno de los problemas más grandes a largo plazo de la industria antes de que la mayoría de la gente entienda completamente cuán importante se volverá ese problema.
Por supuesto, nada de esto garantiza el éxito.
El cripto sigue siendo volátil. La IA se mueve rápido. Las narrativas cambian constantemente.
Pero si alguien me preguntara la idea más fuerte detrás de OpenLedger, no hablaría primero de especulación.
Haría referencia a la Prueba de Atribución.
Porque en el momento en que los sistemas de IA se vean obligados a probar de dónde vino la inteligencia, OpenLedger puede que ya esté exactamente donde el mercado necesita que esté.