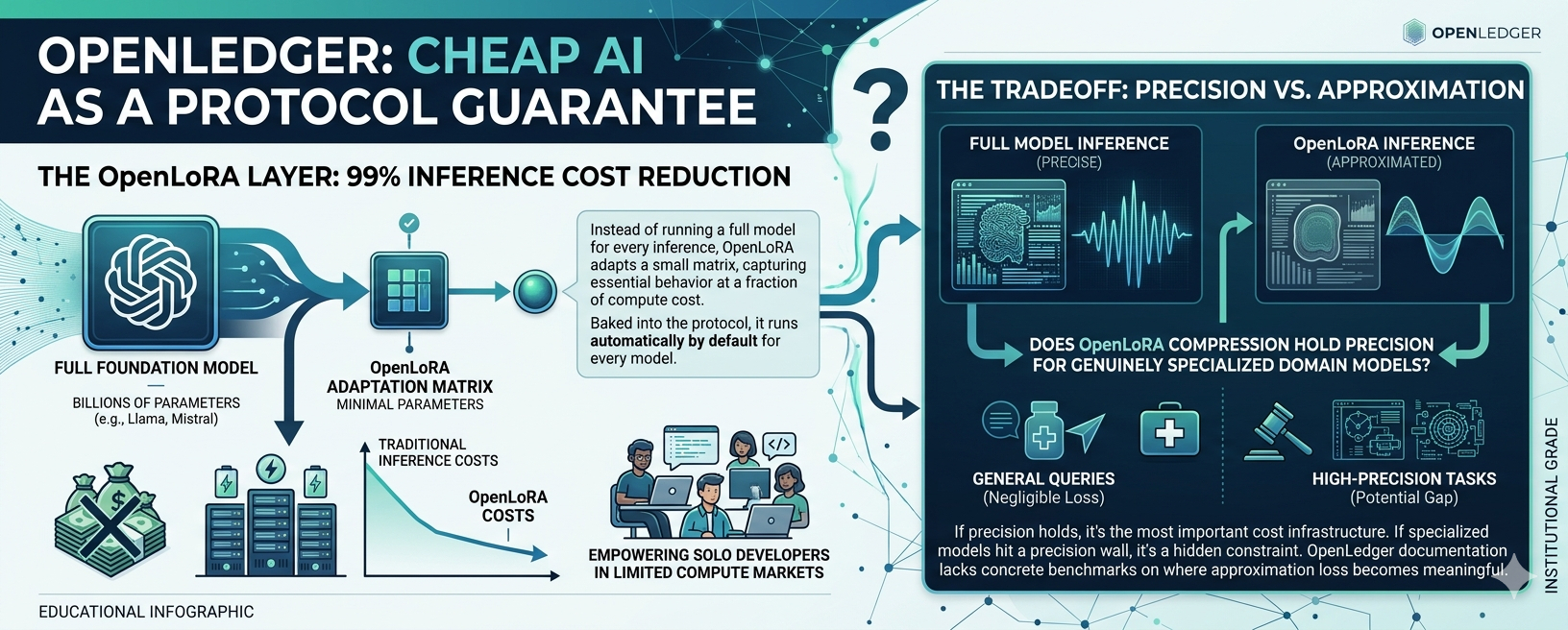

I spent yesterday afternoon mapping out openledger's OpenLoRA layer and i keep landing on the same tension the number is almost too good to question, so most people dont.
99% reduction in AI inference costs. thats the claim. and its not marketing language its an actual implementation of Low-Rank Adaptation baked directly into the protocol layer, not bolted on as an optional tool.
here's what LoRA actually does. instead of running a full model for every inference request loading billions of parameters, burning compute, running the whole thing LoRA adapts a smaller matrix of weights that captures the essential behavior of the model.
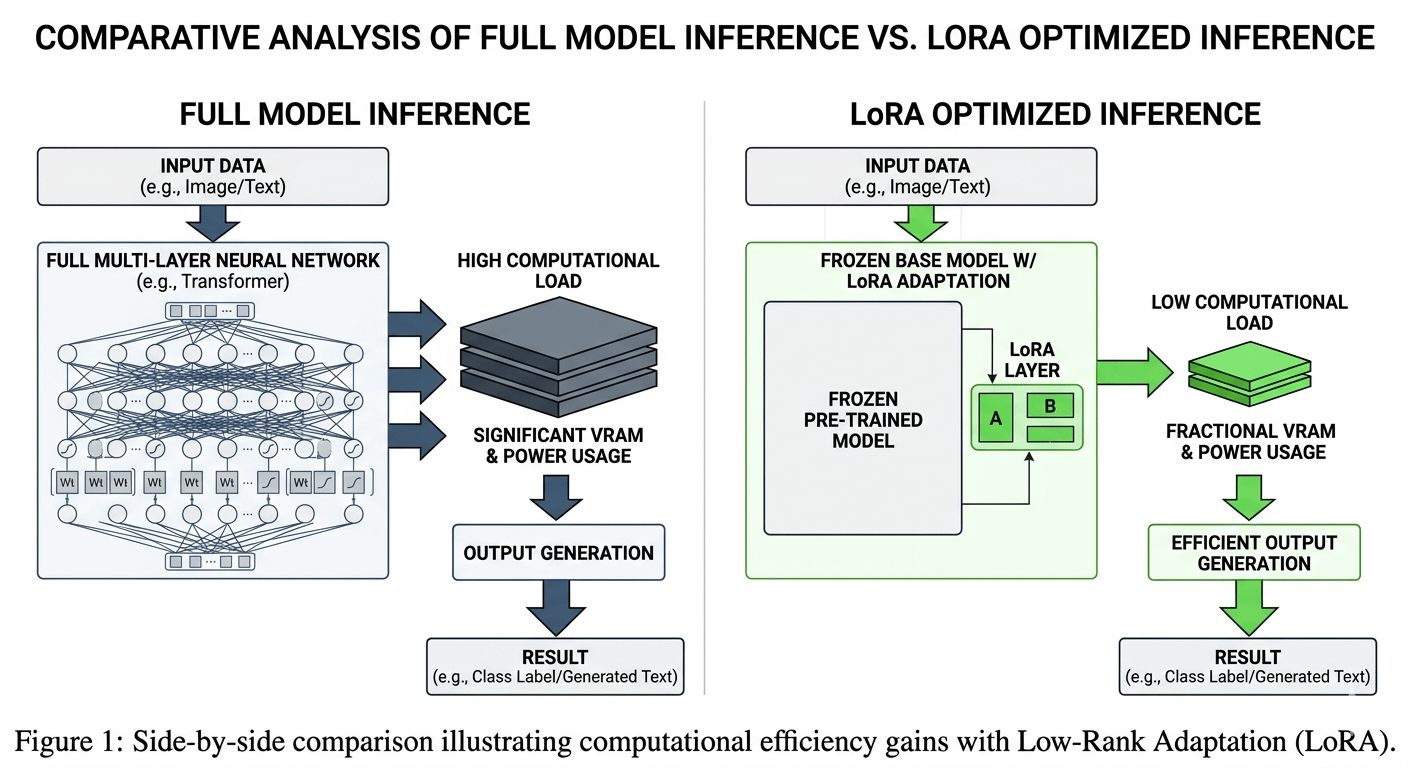
you get outputs... that are functionally close to the full model at a fraction of the compute cost. its been used in research settings for a while. what openledger did is implement it at the infrastructure level, meaning every model deployed through the protocol gets inference optimization by default. developers dont configure it. they dont opt in. it just runs.
thats genuinely interesting design. most protocols treat optimization as a user responsibility. openledger made it a protocol guarantee.
the accessibility implication is real too. if inference costs drop by that magnitude, the universe of people who can actually deploy and run AI models on-chain expands dramatically. a solo developer in a market with limited compute budget can suddenly run models that would have been economically impossible a year ago. thats not a small unlock.
but i cant stop poking at the 99% figure.
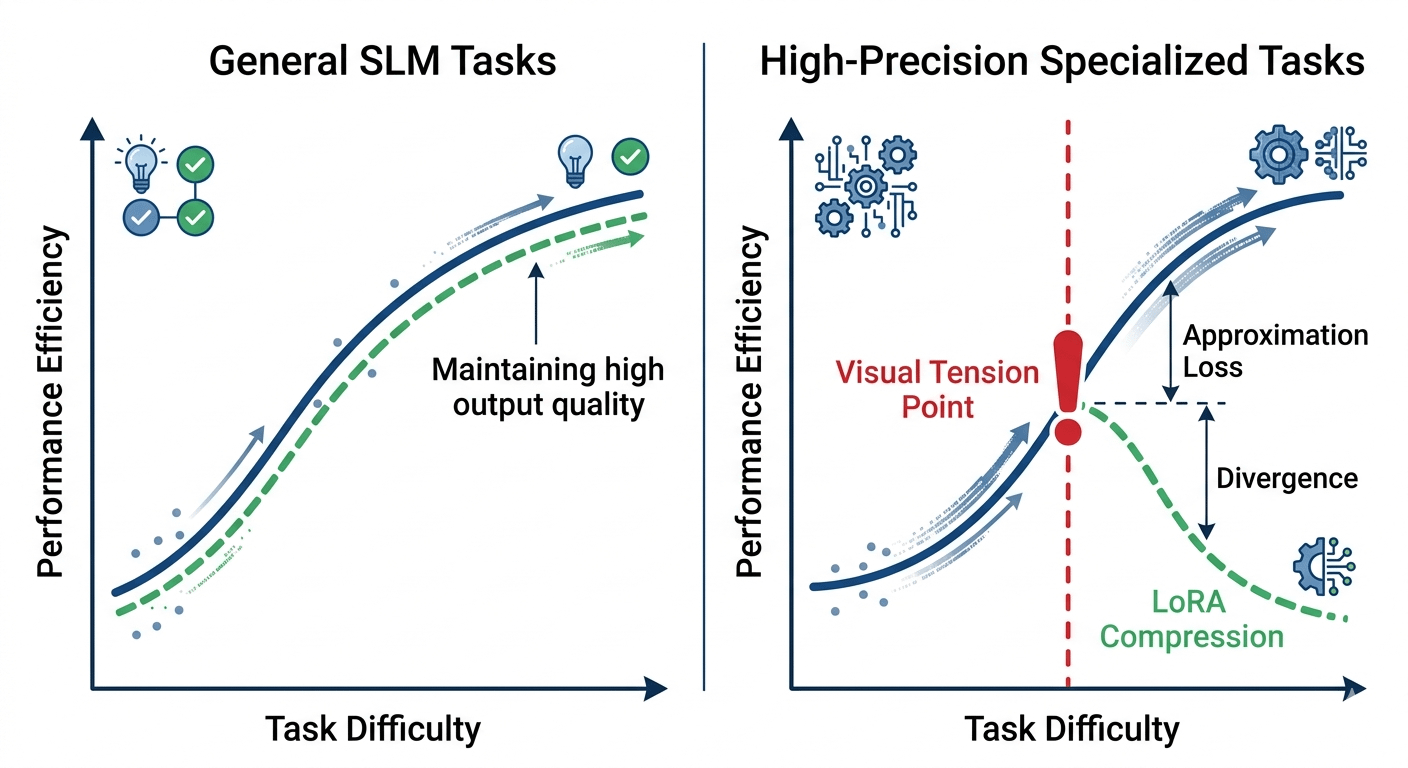
LoRA works by approximating full model behavior not replicating it. the adaptation matrix captures the dominant patterns but drops lower-rank signal in the process. for general queries on well-trained models, that loss is negligible. for specialized, high-precision tasks medical diagnosis, legal interpretation, complex technical analysis the gap between approximated and full inference might matter more than the cost saving.
OpenLedger's entire architecture is built around Specialized Language Models. SLMs trained on curated, domain-specific data with verified provenance. the protocol positions precision as a feature. so the real question is whether LoRA-level approximation is compatible with the precision demands of genuinely specialized models, or whether theres a ceiling where the cost efficiency starts degrading the output quality that makes SLMs worth using in the first place.
i dont have that answer yet. the docs dont give concrete benchmarks for where the approximation loss becomes meaningful. and thats a gap worth naming because if OpenLoRA works as described for general SLM inference, it changes who can participate in on-chain AI in a fundamental way. but if specialized models hit a precision wall at LoRA compression rates, the 99% number becomes a headline that hides a real architectural constraint.
both outcomes are possible. one makes OpenLoRA the most important cost infrastructure in the ecosystem. the other makes it a tool with clear limits that the protocol hasnt fully acknowledged yet.
does OpenLoRA's LoRA compression hold precision for genuinely specialized domain models, or does the approximation loss become the hidden cost of the 99% saving??