Empecé a fijarme en OpenLoRA a partir de una pregunta muy aburrida.
No se trata de cuán inteligente será un agente de IA.
No se trata de cómo OpenLedger desbloqueará la economía de datos.
Sino que: si en el futuro hay miles de modelos especializados, ¿quién realmente los usará lo suficiente para que sobrevivan?
Suena un poco desalentador. Pero el crypto me ha enseñado una lección bastante dura: crear oferta siempre es más fácil que crear demanda. Crear un token es más fácil que crear utilidad. Crear un activo es más fácil que dar razones para que otros lo usen cada día. GameFi ha tenido demasiados ítems sin jugadores reales. DeFi ha tenido demasiados vaults que solo sobrevivían gracias a las emisiones. La IA en crypto puede repetir ese error, solo que esta vez lo que está en el almacén no son NFTs o vaults, sino pequeños modelos llamados 'especializados'.
Al principio, casi caí en la narrativa demasiado rápido.
La IA especializada suena muy lógica. Un modelo para auditar contratos inteligentes. Un modelo para investigación de trading. Un modelo para flujos de trabajo legales. Un modelo para cada comunidad con datos propios. OpenLedger tiene Datanets para agrupar datos especializados, ModelFactory para ajustar, Prueba de Atribución para registrar contribuciones. En papel, todo se conecta bastante bien.
Pero la belleza en papel a menudo pasa por alto una pregunta muy real: ¿ese modelo es llamado lo suficiente?
OpenLoRA me detuvo justo aquí.
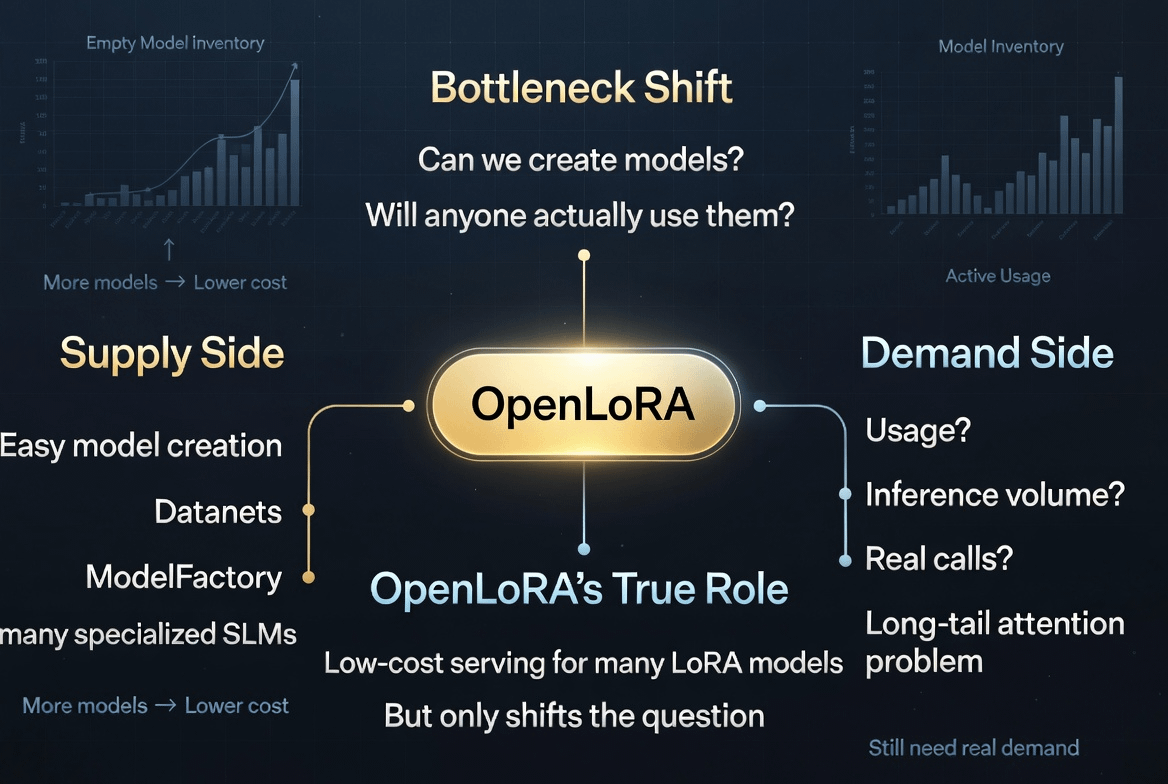
LoRA se puede entender simplemente como una capa de ajuste ligero que se coloca sobre el modelo base, en lugar de tener que reentrenar todo un modelo grande desde cero. OpenLoRA en el whitepaper se describe como un sistema multi-tenant para servir modelos LoRA ajustados con bajo overhead. Este punto de datos suena seco, pero es importante porque OpenLedger no solo necesita crear modelos. Necesita hacer que muchos modelos pequeños puedan ejecutarse a un costo suficientemente bajo.
Antes veía este detalle como una optimización de infraestructura. Ahora creo que se parece más a una prueba.
Cuando el costo de servir sigue siendo demasiado alto, siempre tenemos una razón para justificarlo: la IA especializada aún no ha florecido porque la infraestructura es cara, porque el despliegue es difícil, porque los modelos pequeños no pueden cubrir sus costos por sí mismos. Pero si OpenLoRA reduce esa fricción, la pregunta real comienza a emerger: ¿existe realmente una demanda para la IA de cola larga, o solo hay una oferta de cola larga?
Aquí es donde encuentro que OpenLoRA es más interesante que su parte técnica.
No prueba que OpenLedger tendrá una economía de IA sostenible. Solo desplaza el cuello de botella a un lugar más difícil de eludir. De '¿se pueden ejecutar muchos modelos pequeños?' a '¿qué modelo pequeño tiene un uso real?' De '¿el costo de servir es demasiado alto?' a '¿el volumen de inferencia es lo suficientemente denso para que la recompensa sea significativa?' De '¿quién crea el modelo?' a '¿quién vuelve a llamar a ese modelo por segunda, décima, milésima vez?'
Porque en OpenLedger, un modelo especializado solo tiene vida económica cuando se utiliza. La inferencia no es solo la respuesta de la IA. Es el punto donde se paga la tarifa, la atribución tiene datos para medir, y la recompensa tiene la oportunidad de volver al contribuyente. Si el uso es escaso, la Prueba de Atribución puede ser lógicamente correcta, pero la recompensa para el que aporta datos puede ser demasiado pequeña para cambiar el comportamiento. La equidad en el gráfico no se convierte automáticamente en un incentivo en la vida real.
Aquí es donde creo que muchos pasarán por alto.
A la gente le encanta hablar de 'desbloquear la liquidez para datos y modelos'. Pero la liquidez no aparece solo porque un activo esté definido. Surge cuando hay personas que quieren usarlo, quieren pagar tarifas, quieren volver. De lo contrario, el ecosistema puede tener muchos adaptadores, muchos modelos, muchos dashboards bonitos, pero se asemejan a un mercado abierto toda la noche sin suficientes compradores.
No digo esto para desestimar OpenLoRA. Por el contrario, esta es la razón por la que creo que merece ser observada. Una buena infraestructura no solo resuelve problemas antiguos. También revela el siguiente problema. Si OpenLoRA ayuda a que los modelos pequeños sean más baratos de ejecutar, entonces OpenLedger no se evaluará por la cantidad de modelos creados. Se evaluará por la calidad de la demanda detrás de esos modelos.
¿Los desarrolladores realmente los integran en el flujo de trabajo?
¿Los agentes los llaman porque son más útiles que las opciones generales?
¿Los contribuyentes ven la recompensa lo suficientemente real como para seguir aportando buenos datos a Datanets?
¿O todo esto solo crea una nueva capa de inventario para el mercado de valoración antes de que la utilidad tenga la oportunidad de aparecer?
Aquí es donde veo que OpenLoRA se conecta con una pregunta más grande de la IA cripto. Puede que la próxima ronda de esta industria no carezca de inteligencia. Carece de un mecanismo para saber qué inteligencia merece existir. A medida que crear y servir modelos pequeños se vuelve más fácil, la escasez ya no está en la cantidad de modelos. Está en la atención, distribución, confianza y uso real.
Así que OpenLoRA no es 'la respuesta final' de @OpenLedger .
Es como cuando abrimos una válvula en un sistema de tuberías. Antes, la gente podría discutir indefinidamente si el agua podía fluir o no porque la válvula estaba demasiado apretada. Cuando la válvula se abre, la nueva pregunta es mucho más clara: ¿hay agua realmente en las tuberías, y esa agua llega a donde hay gente que la necesita?
Si lo hay, OpenLoRA podría ser uno de los detalles silenciosos que ayuden a que la IA especializada de cola larga se convierta en una economía real.
Si no, la inteligencia de cola larga solo se convertirá en un almacén interminable de modelos que pocos llamarán.
Y creo que esa es la prueba que vale la pena observar en OpenLedger. No es cuántos modelos bonitos se pueden crear en papel, sino cuántos modelos pueden ser llamados lo suficiente para que los datos detrás de ellos no solo sean reconocidos, sino que realmente haya un flujo de valor de vuelta.